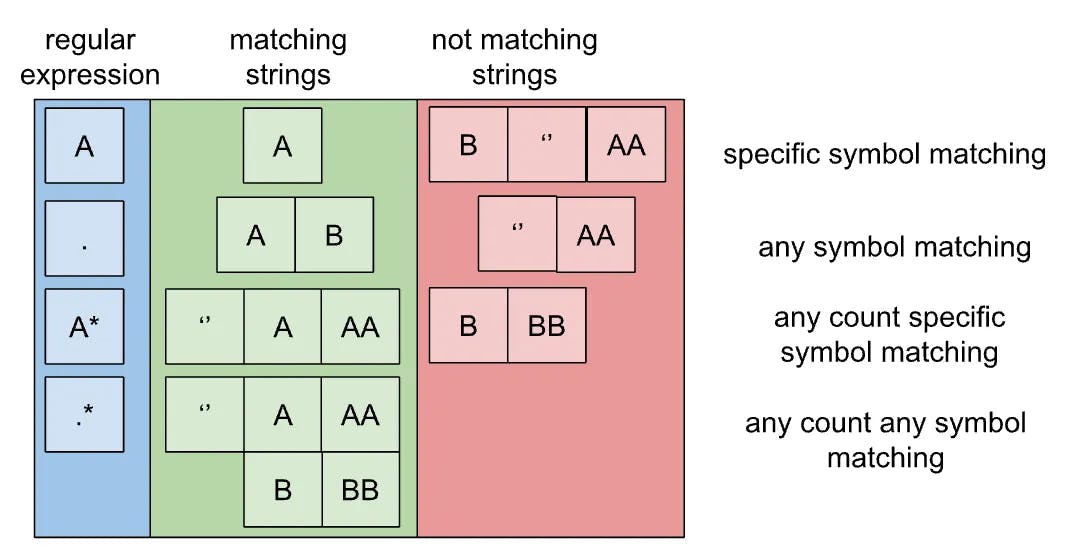
Brief In this article, I would like to consider an efficient way of implementing the sliding window median algorithm. This algorithm is widely used in data analysis and efficient implementation is valuable for big data runtime analytics. The article will be based on a hard-level “leet-code” task statement. The main goal is to develop and implement a fast solution. Points considered here will be the same for multiple algorithms based on the sliding window. Problem statement In data analysis, we often need to count the aggregating value of the sequential part of the dataset. Then we need to count this aggregating value for the next sequential part of the dataset that has equal size but sequential values selection moved front on the dataset line just by one element. Then this computation needs to be repeated several times after each move by one element. This approach to computation is known as computation in the sliding window. A sliding window is just a dataset part selection algorithm but exact aggregating computation algorithms can vary. We need to consider a specific aggregation algorithm known as median computation. This median can be computed in different ways — but in“leetcode” the task statement notation median is: middle element of the ascendant ordered sliding window ( if elements counts is odd ) average of two elements in the middle the ascendant ordered of sliding window ( if elements count is even) Design notes Sliding window median computation (algorithm-specific) The property of the aggregation algorithm defines the ability of the sliding window computation algorithm to be implemented in a runtime-efficient way. Moreover, the Median computation has some properties we need to consider: median depends only on elements on specific indexes of sliding window only on ability of detect of this elements indexes with O(1) complexity we will have best possible solution These points work by just one sliding window position. But after moving the sliding window one element forward on the dataset we needto recompute the median. This one step forward move also needs to be fast. To define the main approach for fast-moving — let’s consider the following picture: In the picture we find out what happens on the inside of the sliding window as this move occurs: we remove the first element from the previous step from the sliding window next, we add a new last element to the sliding window at the new position This action can have O(1) complexity for the one move in the best case. To implement the algorithm we need to select or create the most appropriate container to store sliding window values. This container should match the following parameters: store the data in ascending order be tolerant to duplicates in the stored collection be able to return middle element / near to middle elements of the collection with the most efficient complexity be able to add and drop elements with the best possible complexity Next, we will consider several standard containers to find the complexity of the final solution for this container’s usage. Then we will consider the synthetic container that can operate with the best complexity. Vector based solution When using a vector, we have the advantage of selecting any element with O(1) complexity. In the case of total median selection, the complexity will be equal to O(N - K), where N is the dataset size and K is the sliding window size. The algorithm involves sorting the vector data, and this sorting is crucial for its performance. From a runtime perspective, a significant portion of the algorithm involves the ascending sorting of the sliding window. This sorting requires two types of operations: Initial full sliding window sorting with a complexity of O(K * log(K)), where K is the sliding window size. Partial sorting for each sliding window move with a complexity of O((log(K) + K) * (N - K)). The partial sorting is done at each sliding window move step, which involves finding the appropriate place to insert a new element in the sorted vector with a complexity of O(log(K)), and then inserting the new element with a complexity of O(K). The total complexity of the vector-based solution is: O(N - K) + O(K * log(K)) + O((N - K) * (log(K) + K)) => O(N - K) + O(K * log(K)) + O((N - K) * K) => O((N - K) * K) This solution represents one of the two most promising trivial solutions based on standard container usage. Now, let's delve into the second solution. Binary-tree-based solution If we use binary trees as base collection we will have sorted collection by design. The complexity of the sorting will be: Initial full sliding window put in the binary tree complexity is O(K*log(K)) Addition and deletion of the new and old element on all of the sliding window moves complexity O((N-K)*log(K)) However, the selection of the middle elements at the sliding window to compute the median will not have O(1) complexity. We need to traverse from the beginning of the sliding window binary tree to the middle to get the median. Complexity of the median selection will be O((N-K)*K) This makes total complexity of binary tree bases median selection at sliding window algorithm complexity equal to: O((N-K)*K) + O(K*log(K)) + O((N-K)*log(K)) =>O((N-K)*K) This complexity will equal the complexity of the solution based on the vector. Custom-container-based solution Even if binary tree-based implementation shows complexity that is not the best it has just one reason: selection of the middle element(s) of the binary tree tends to be long. If this issue can be resolved — then a solution can be considered as the best. In the picture above we can see another representation of the sliding window. It is presented by 2 ( not just one ) binary trees. These binary trees have a limited size that is equal to half of the sliding window size. These binary trees will contain the first and last halves of sorted elements of the sliding window. Representation of the sliding window like this makes it possible to select middle elements of the sliding window with O(1) complexity. However, it still is not clear how to make the move in this case and what complexity we will have. To make the move with a container like this we need to split the sliding window move into 3 actions: add a new element to the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)) delete the old element of the binary tree from the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)). balancing the front and back parts of the sliding window — move the element on the border from one part to another to meet half of the sliding window part size for each of the sliding windows. Complexity is O(log(K)). Let’s look at the picture to understand the action sequence and complexity computation order. This tree criteria makes the total complexity of the algorithm equal to: O((N-K)*log(K)) + O(K*log(K)) + O((N-K)*log(K)) =>O((N-K)*log(K)) + O(K*log(K)) =>O(N*log(K)) This is the best possible runtime complexity can be achieved for the median of sliding window detection. Implementation notes Runtime-wise efficient implementation expects to use language that is appropriate for runtime-efficient software development. I have used C++. We need to have an implementation that will be tolerant of the duplicates at the sliding window. In C++ notation we have a standard container at Standard Template Library named “multiset” that implements the binary tree that is tolerant to element duplication.To minimize the memory footprint we need to avoid the current binary trees copying and implement all of the actions in place. It is good to use containers by reference at code or use move semantics of C++ to hold memory as tight as possible. Conclusion During this article, the best possible runtime-wise solution was found for sliding window median detection. The exposed approach to implement the move of the sliding window can be used for different purposes in an efficient way. Thank you for the time you spend and let’s improve your analytics runtime by information from this article. Brief In this article, I would like to consider an efficient way of implementing the sliding window median algorithm. This algorithm is widely used in data analysis and efficient implementation is valuable for big data runtime analytics. The article will be based on a hard-level “leet-code” task statement . The main goal is to develop and implement a fast solution. Points considered here will be the same for multiple algorithms based on the sliding window. big data hard-level “leet-code” task statement hard-level “leet-code” task statement Problem statement In data analysis , we often need to count the aggregating value of the sequential part of the dataset. Then we need to count this aggregating value for the next sequential part of the dataset that has equal size but sequential values selection moved front on the dataset line just by one element. Then this computation needs to be repeated several times after each move by one element. data analysis This approach to computation is known as computation in the sliding window. A sliding window is just a dataset part selection algorithm but exact aggregating computation algorithms can vary. We need to consider a specific aggregation algorithm known as median computation. This median can be computed in different ways — but in“leetcode” the task statement notation median is: middle element of the ascendant ordered sliding window ( if elements counts is odd ) average of two elements in the middle the ascendant ordered of sliding window ( if elements count is even) middle element of the ascendant ordered sliding window ( if elements counts is odd ) middle element of the ascendant ordered sliding window ( if elements counts is odd ) middle element of the ascendant ordered sliding window ( if elements counts is odd ) average of two elements in the middle the ascendant ordered of sliding window ( if elements count is even) average of two elements in the middle the ascendant ordered of sliding window ( if elements count is even) average of two elements in the middle the ascendant ordered of sliding window ( if elements count is even) Design notes Sliding window median computation (algorithm-specific) The property of the aggregation algorithm defines the ability of the sliding window computation algorithm to be implemented in a runtime-efficient way. Moreover, the Median computation has some properties we need to consider: Moreover, the Median computation has some properties we need to consider: median depends only on elements on specific indexes of sliding window only on ability of detect of this elements indexes with O(1) complexity we will have best possible solution median depends only on elements on specific indexes of sliding window only median depends only on elements on specific indexes of sliding window only median depends only on elements on specific indexes of sliding window only on ability of detect of this elements indexes with O(1) complexity we will have best possible solution on ability of detect of this elements indexes with O(1) complexity we will have best possible solution These points work by just one sliding window position. But after moving the sliding window one element forward on the dataset we need to recompute the median. This one step forward move also needs to be fast. To define the main approach for fast-moving — let’s consider the following picture: In the picture we find out what happens on the inside of the sliding window as this move occurs: we remove the first element from the previous step from the sliding window next, we add a new last element to the sliding window at the new position we remove the first element from the previous step from the sliding window we remove the first element from the previous step from the sliding window next, we add a new last element to the sliding window at the new position next, we add a new last element to the sliding window at the new position This action can have O(1) complexity for the one move in the best case. To implement the algorithm we need to select or create the most appropriate container to store sliding window values. This container should match the following parameters: This container should match the following parameters: store the data in ascending order be tolerant to duplicates in the stored collection be able to return middle element / near to middle elements of the collection with the most efficient complexity be able to add and drop elements with the best possible complexity store the data in ascending order store the data in ascending order be tolerant to duplicates in the stored collection be tolerant to duplicates in the stored collection be able to return middle element / near to middle elements of the collection with the most efficient complexity be able to return middle element / near to middle elements of the collection with the most efficient complexity be able to add and drop elements with the best possible complexity be able to add and drop elements with the best possible complexity Next, we will consider several standard containers to find the complexity of the final solution for this container’s usage. Then we will consider the synthetic container that can operate with the best complexity. Vector based solution Vector based solution When using a vector, we have the advantage of selecting any element with O(1) complexity. In the case of total median selection, the complexity will be equal to O(N - K), where N is the dataset size and K is the sliding window size. The algorithm involves sorting the vector data, and this sorting is crucial for its performance. From a runtime perspective, a significant portion of the algorithm involves the ascending sorting of the sliding window. This sorting requires two types of operations: Initial full sliding window sorting with a complexity of O(K * log(K)), where K is the sliding window size. Partial sorting for each sliding window move with a complexity of O((log(K) + K) * (N - K)). Initial full sliding window sorting with a complexity of O(K * log(K)), where K is the sliding window size. Initial full sliding window sorting with a complexity of O(K * log(K)), where K is the sliding window size. Partial sorting for each sliding window move with a complexity of O((log(K) + K) * (N - K)). Partial sorting for each sliding window move with a complexity of O((log(K) + K) * (N - K)). The partial sorting is done at each sliding window move step, which involves finding the appropriate place to insert a new element in the sorted vector with a complexity of O(log(K)), and then inserting the new element with a complexity of O(K). The total complexity of the vector-based solution is: O(N - K) + O(K * log(K)) + O((N - K) * (log(K) + K)) => O(N - K) + O(K * log(K)) + O((N - K) * K) => O((N - K) * K) This solution represents one of the two most promising trivial solutions based on standard container usage. Now, let's delve into the second solution. Binary-tree-based solution If we use binary trees as base collection we will have sorted collection by design. The complexity of the sorting will be: The complexity of the sorting will be: Initial full sliding window put in the binary tree complexity is O(K*log(K)) Addition and deletion of the new and old element on all of the sliding window moves complexity O((N-K)*log(K)) Initial full sliding window put in the binary tree complexity is O(K*log(K)) Initial full sliding window put in the binary tree complexity is O(K*log(K)) Addition and deletion of the new and old element on all of the sliding window moves complexity O((N-K)*log(K)) Addition and deletion of the new and old element on all of the sliding window moves complexity O((N-K)*log(K)) However, the selection of the middle elements at the sliding window to compute the median will not have O(1) complexity. We need to traverse from the beginning of the sliding window binary tree to the middle to get the median. Complexity of the median selection will be O((N-K)*K) Complexity of the median selection will be O((N-K)*K) Complexity of the median selection will be O((N-K)*K) This makes total complexity of binary tree bases median selection at sliding window algorithm complexity equal to: O((N-K)*K) + O(K*log(K)) + O((N-K)*log(K)) =>O((N-K)*K) O((N-K)*K) + O(K*log(K)) + O((N-K)*log(K)) =>O((N-K)*K) O((N-K)*K) + O(K*log(K)) + O((N-K)*log(K)) => O((N-K)*K) This complexity will equal the complexity of the solution based on the vector. Custom-container-based solution Even if binary tree-based implementation shows complexity that is not the best it has just one reason: selection of the middle element(s) of the binary tree tends to be long. selection of the middle element(s) of the binary tree tends to be long. selection of the middle element(s) of the binary tree tends to be long. If this issue can be resolved — then a solution can be considered as the best. In the picture above we can see another representation of the sliding window. It is presented by 2 ( not just one ) binary trees. These binary trees have a limited size that is equal to half of the sliding window size. These binary trees will contain the first and last halves of sorted elements of the sliding window. Representation of the sliding window like this makes it possible to select middle elements of the sliding window with O(1) complexity. Representation of the sliding window like this makes it possible to select middle elements of the sliding window with O(1) complexity. Representation of the sliding window like this makes it possible to select middle elements of the sliding window with O(1) complexity. Representation of the sliding window like this makes it possible to select middle elements of the sliding window with O(1) complexity. However, it still is not clear how to make the move in this case and what complexity we will have. To make the move with a container like this we need to split the sliding window move into 3 actions: add a new element to the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)) delete the old element of the binary tree from the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)). balancing the front and back parts of the sliding window — move the element on the border from one part to another to meet half of the sliding window part size for each of the sliding windows. Complexity is O(log(K)). add a new element to the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)) add a new element to the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)) add a new element to the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)) delete the old element of the binary tree from the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)). delete the old element of the binary tree from the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)). delete the old element of the binary tree from the part binary tree selected by comparison with the middle element of the sliding window. Complexity is O(log(K)). balancing the front and back parts of the sliding window — move the element on the border from one part to another to meet half of the sliding window part size for each of the sliding windows. Complexity is O(log(K)). balancing the front and back parts of the sliding window — move the element on the border from one part to another to meet half of the sliding window part size for each of the sliding windows. Complexity is O(log(K)). balancing the front and back parts of the sliding window — move the element on the border from one part to another to meet half of the sliding window part size for each of the sliding windows. Complexity is O(log(K)). Let’s look at the picture to understand the action sequence and complexity computation order. This tree criteria makes the total complexity of the algorithm equal to: O((N-K)*log(K)) + O(K*log(K)) + O((N-K)*log(K)) =>O((N-K)*log(K)) + O(K*log(K)) =>O(N*log(K)) O((N-K)*log(K)) + O(K*log(K)) + O((N-K)*log(K)) =>O((N-K)*log(K)) + O(K*log(K)) =>O(N*log(K)) O((N-K)*log(K)) + O(K*log(K)) + O((N-K)*log(K)) =>O((N-K)*log(K)) + O(K*log(K)) =>O(N*log(K)) O((N-K)*log(K)) + O(K*log(K)) + O((N-K)*log(K)) => O((N-K)*log(K)) + O(K*log(K)) => O(N*log(K)) This is the best possible runtime complexity can be achieved for the median of sliding window detection. Implementation notes Runtime-wise efficient implementation expects to use language that is appropriate for runtime-efficient software development. I have used C++. We need to have an implementation that will be tolerant of the duplicates at the sliding window. In C++ notation we have a standard container at Standard Template Library named “multiset” that implements the binary tree that is tolerant to element duplication. To minimize the memory footprint we need to avoid the current binary trees copying and implement all of the actions in place. It is good to use containers by reference at code or use move semantics of C++ to hold memory as tight as possible. Conclusion During this article, the best possible runtime-wise solution was found for sliding window median detection. The exposed approach to implement the move of the sliding window can be used for different purposes in an efficient way. Thank you for the time you spend and let’s improve your analytics runtime by information from this article.