
775 reads
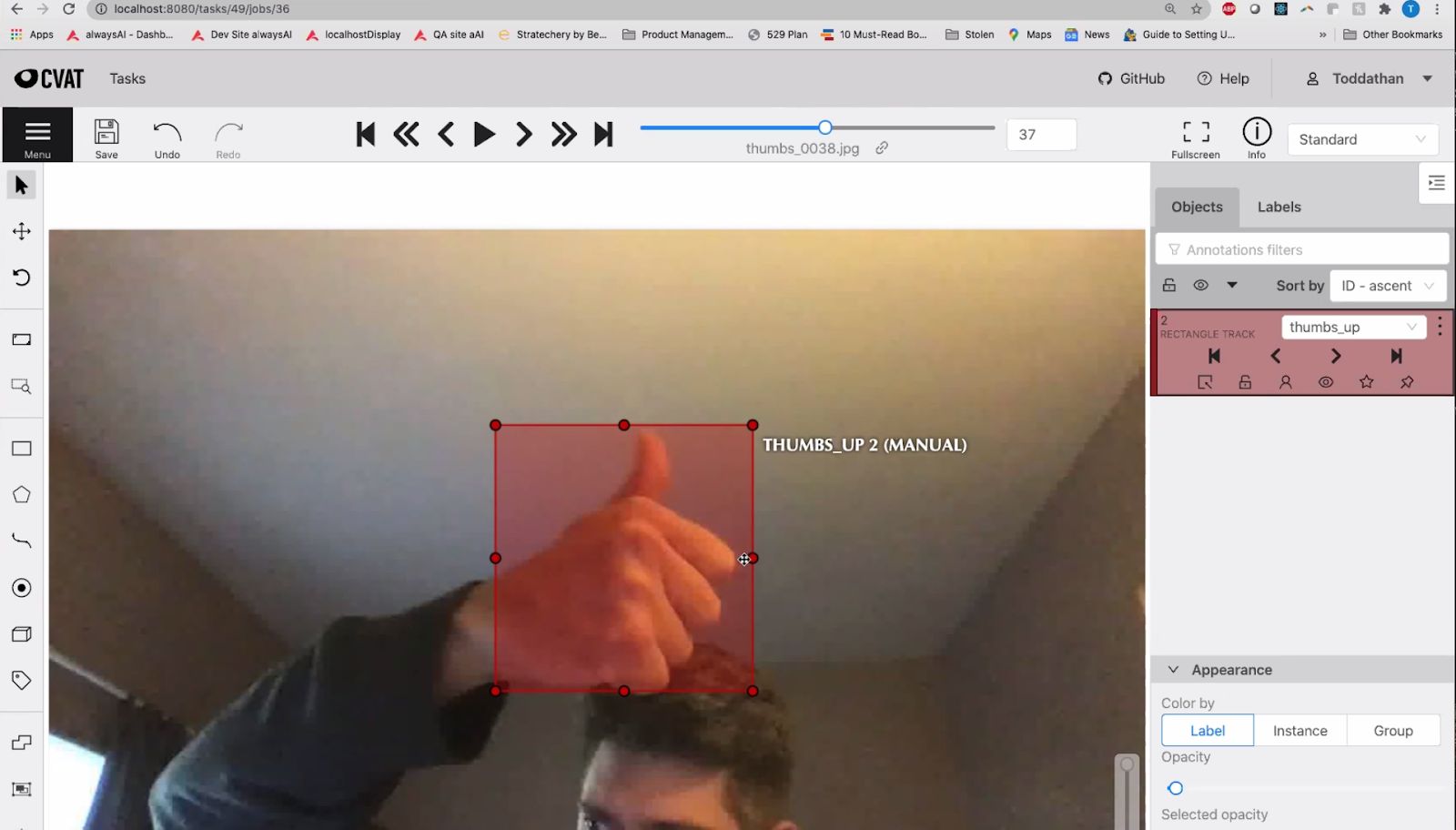
How to Train Computer Vision Models Efficiently
by byalwaysAI @alwaysai
byalwaysAI @alwaysai
A developer platform for creating & deploying computer vision applications on the edge.
November 9th, 2020





A developer platform for creating & deploying computer vision applications on the edge.


A developer platform for creating & deploying computer vision applications on the edge.
About Author

A developer platform for creating & deploying computer vision applications on the edge.
Comments













