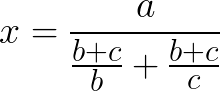If you look for an easy answer, here it is. If it makes you annoyed, if you wonder, why the hell the thing is that complex, then it is accidental. If it makes you depressed, if you know exactly why the hell it is, then it is essential. If you look for a more elaborate explanation, then I’m afraid I have bad news for you. The deeper you dig into the subject, the more subtle the boundaries become. The terms come from the famous “ ” paper by Fred Brooks. The essence of the paper could be put in a single quote: No Silver Bullet — Essence and Accident in Software Engineering there is no single development, in either technology or management technique, which by itself promises even one [tenfold] improvement within a decade in productivity, in reliability, in simplicity. order of magnitude The accidental complexity here is just an instrument for explaining, how come high-level languages the development that improved productivity tenfold. Just as all the best things in life, it could be illustrated with a disassembly. were Consider a simple problem: Let’s say all the variables are non-negative integer numbers. In x64 GCC disassembly, the function that does the computation looks like this. _Z12do_the_mathsmmm:.LFB1426:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movq %rdi, -8(%rbp)movq %rsi, -16(%rbp)movq %rdx, -24(%rbp)movq -16(%rbp), %rdxmovq -24(%rbp), %rax movl $0, %edx movq %rax, %rcxmovq -16(%rbp), %rdxmovq -24(%rbp), %rax movl $0, %edx leaq (%rcx,%rax), %rsimovq -8(%rbp), %raxmovl $0, %edx popq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc addq %rdx, %rax ; addition is essential divq -16(%rbp) ; division is essential addq %rdx, %rax ; addition is essential divq -24(%rbp) ; division is essential divq %rsi ; division is essential We can’t do the problem unless we do three divisions and two additions, that’s the essence of the solution. All the rest is just the supplementary code provided by the compiler to make it work for the specific hardware architecture. This is accidental. In this particular piece, the proportion of accidental lines to essential is about 4 to 1. Let’s now look at the source code. uint64_t do_the_maths(uint64_t , uint64_t , uint64_t ){return / (( + ) / + ( + ) / );} a b c a b c b b c c It’s just 2 meaningful lines. Yes, it looks like it has an extra addition, so it is not exactly the optimal solution, but what actually happens here is we delegate the job of pre-calculating to the compiler and this makes the whole thing both compact and efficient. b+c In sheer lines of code 2/25 is close to the above-mentioned order of magnitude. We removed accidental complexity from our code by delegating the tedious job of optimization to the compiler. But hold on a minute! Is assembly code the only source of accidental complexity? Of course not. Since writing assembly is now a privilege of the machine, we invented a whole new world of high-level complexity for us to play with. Perhaps this wasn’t obvious in 1987 when the original paper was published, but most of the accidental complexity nowadays is born by the attempts of fleeing from the complexity. It’s just a vicious cycle. In fact it’s even more; it’s like evolving spiral. You solve one problem — here’s two more. Let’s say we want our code to work both on unsigned integers and unsigned floating point numbers. No problem. uint64_t do_the_maths(uint64_t a, uint64_t b, uint64_t c){return a / ((b + c) / b + (b + c) / c);} float do_the_maths(float a, float b, float c){return a / ((b + c) / b + (b + c) / c);} Well, it does the job, but it makes our program twice as big and seemingly twice as complex. Besides, it’s an obvious copy-paste, and copy-paste is a no-no. I know! Why don’t we make it parametric? template <typename T>T do_the_maths(T a, T b, T c){return a / ((b + c) / b + (b + c) / c);} Now it can work on integers, floats and everything that has and . I bet it would even work on . + / boost::path The problem is, it wouldn’t work just like with unsigned integers. And I don’t even mean I’m talking about floats. There is no such thing as standard unsigned float, so we should not just assume that the input is always non-negative. We should assert it specifically. booth::path template <typename T>T do_the_maths(T a, T b, T c){assert(a >= 0);assert(b >= 0);assert(c >= 0);return a / ((b + c) / b + (b + c) / c);} Fair enough. But there is still a substantial difference. For integer numbers when the denominator is it’s undefined behavior. For floating point numbers it’s just a special kind of computation. In our case this means that the former integer solution crashes on zero division somehow like this: 0 okaleniuk@bb:~/complexity$ ./mainFloating point exception (core dumped) But for the floating point numbers it just fails silently and may cause nasty troubles elsewhere. We should not allow this to happen! template <typename T>T do_the_maths(T a, T b, T c){assert(a >= 0);assert(b >= 0);assert(c >= 0);assert(b != 0);assert(c != 0);T d = ((b + c) / b + (b + c) / c);assert(d != 0);return a / d;} Well, this looks error-proof. Note that all the code here is essential. Well, it looks essential, we can’t just remove any line here. But let’s take a peek at our disassembly once more to see what it does to our hidden accidental part. _Z12do_the_mathsIiET_S0_S0_S0_:.LFB1540:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6subq $32, %rspmovl %edi, -20(%rbp)movl %esi, -24(%rbp)movl %edx, -28(%rbp)cmpl $0, -20(%rbp)jns .L4movl $_ZZ12do_the_mathsIiET_S0_S0_S0_E19__PRETTY_FUNCTION__, %ecxmovl $7, %edxmovl $.LC0, %esimovl $.LC1, %edicall __assert_fail.L4:cmpl $0, -24(%rbp)jns .L5movl $_ZZ12do_the_mathsIiET_S0_S0_S0_E19__PRETTY_FUNCTION__, %ecxmovl $8, %edxmovl $.LC0, %esimovl $.LC2, %edicall __assert_fail.L5:cmpl $0, -28(%rbp)jns .L6movl $_ZZ12do_the_mathsIiET_S0_S0_S0_E19__PRETTY_FUNCTION__, %ecxmovl $9, %edxmovl $.LC0, %esimovl $.LC3, %edicall __assert_fail.L6:cmpl $0, -24(%rbp)jne .L7movl $_ZZ12do_the_mathsIiET_S0_S0_S0_E19__PRETTY_FUNCTION__, %ecxmovl $10, %edxmovl $.LC0, %esimovl $.LC4, %edicall __assert_fail.L7:cmpl $0, -28(%rbp)jne .L8movl $_ZZ12do_the_mathsIiET_S0_S0_S0_E19__PRETTY_FUNCTION__, %ecxmovl $11, %edxmovl $.LC0, %esimovl $.LC5, %edicall __assert_fail.L8:movl -24(%rbp), %edxmovl -28(%rbp), %eaxaddl %edx, %eaxcltdidivl -24(%rbp)movl %eax, %ecxmovl -24(%rbp), %edxmovl -28(%rbp), %eaxaddl %edx, %eaxcltdidivl -28(%rbp)addl %ecx, %eaxmovl %eax, -4(%rbp)cmpl $0, -4(%rbp)jne .L9movl $_ZZ12do_the_mathsIiET_S0_S0_S0_E19__PRETTY_FUNCTION__, %ecxmovl $13, %edxmovl $.LC0, %esimovl $.LC6, %edicall __assert_fail.L9:movl -20(%rbp), %eaxcltdidivl -4(%rbp)leave.cfi_def_cfa 7, 8ret.cfi_endproc It doesn’t look very simple, does it? And it is still a code that works for the integers only. All the assertions are redundant here. The problem with hiding away the accidental complexity made by a compiler is that it is only accidental for us, coders. For the machine, it is the only essence of the job. From the machines’ point of view, the source code in accidental. And coders are just a nuisance they have to tolerate. I’m trying to say, the assembly code is essential for performance. If we have to take it into consideration, it should become essential for us on a source code level. We don’t want to pay for all the assertions we don’t need, so we have to make a template specialization for unsigned integers. template <typename T>T do_the_maths(T a, T b, T c){assert(a >= 0);assert(b >= 0);assert(c >= 0);assert(b != 0);assert(c != 0);T d = ((b + c) / b + (b + c) / c);assert(d != 0);return a / d;} template <>uint64_t do_the_maths(uint64_t a, uint64_t b, uint64_t c){return a / ((b + c) / b + (b + c) / c);} So… this is all essential, right? Either for compatibility, or for performance. No less than 13 lines of meaningful code. Well, we can still make it smaller. For instance, since we had to get back to two instances of , it would be better to make them specific. That will cut 2 lines down. do_the_maths float do_the_maths(float a, float b, float c){assert(a >= 0);assert(b >= 0);assert(c >= 0);assert(b != 0);assert(c != 0);T d = ((b + c) / b + (b + c) / c);assert(d != 0);return a / d;} uint64_t do_the_maths(uint64_t a, uint64_t b, uint64_t c){return a / ((b + c) / b + (b + c) / c);} You might argue that we might need another type soon enough and with the parametric solution, we would have had a new instance for free. But nothing is free. We got a bag of mishaps from a simple float; we can not possibly hope that every other type will integrate seamlessly. More probable, it would bring a whole new specter of hard to detect problems. With specific instances, we would have to face them upfront, and that’s a good thing. Now obviously enough, we don’t need separate lines for non-negativity and not zero, we can easily conjoin them, that’s two more lines. float do_the_maths(float a, float b, float c){assert(a >= 0);assert(b > 0);assert(c > 0);T d = ((b + c) / b + (b + c) / c);assert(d != 0);return a / d;} uint64_t do_the_maths(uint64_t a, uint64_t b, uint64_t c){return a / ((b + c) / b + (b + c) / c);} Now for the fun part. If both and are greater than than their sum can not possibly be smaller than or apart. This means that both parts of the big denominator are guaranteed to be or greater. This makes the last assert redundant, neither we have to introduce a new variable for . That’s two more lines as well. b c 0 b c d 1 d float do_the_maths(float a, float b, float c){assert(a >= 0);assert(b > 0);assert(c > 0);return a / ((b + c) / b + (b + c) / c);} uint64_t do_the_maths(uint64_t a, uint64_t b, uint64_t c){return a / ((b + c) / b + (b + c) / c);} This is the same code essentially, but it’s almost half the size. It is also noticeably simpler. So was the code removed accidental? We kind of established that it wasn’t. How come we removed it safely? Now was the disassembly essential? Not for us anyway. So how come we introduced more code to make it simpler? You see, when you dig into the business of complexity segregation deep enough, there are more questions than answers. I for one think, essentially all the complexity is accidental. All the hardware, all the problems, and all the languages were invented by people. It is all a solid universe of complexity. Sometimes you make your programmers’ task twice as simple by choosing the right language for the task. Sometimes you make it absolutely simple by clarifying that the task isn’t worth solving. We all live in a huge network of complexity. You can go as far as you want by making your own hardware, or by building your own business with your own problems to solve. It doesn’t end with a compiler or the software at all. We only limit our horizon to our own field of responsibility not to go insane. But that is no more than my own opinion. That’s just what I do behind my field of responsibility. I do opinions. I might be loosing a bit of sanity in the process.