
How to Maintain a Prototyping Mindset When Building for the Semantic Web
by byMarko Marinkovic@marxwood
byMarko Marinkovic@marxwood
#a11y not only for humans, but also machines - for the semantic web. {content, semantics, accessibility}-first design.
January 10th, 2022





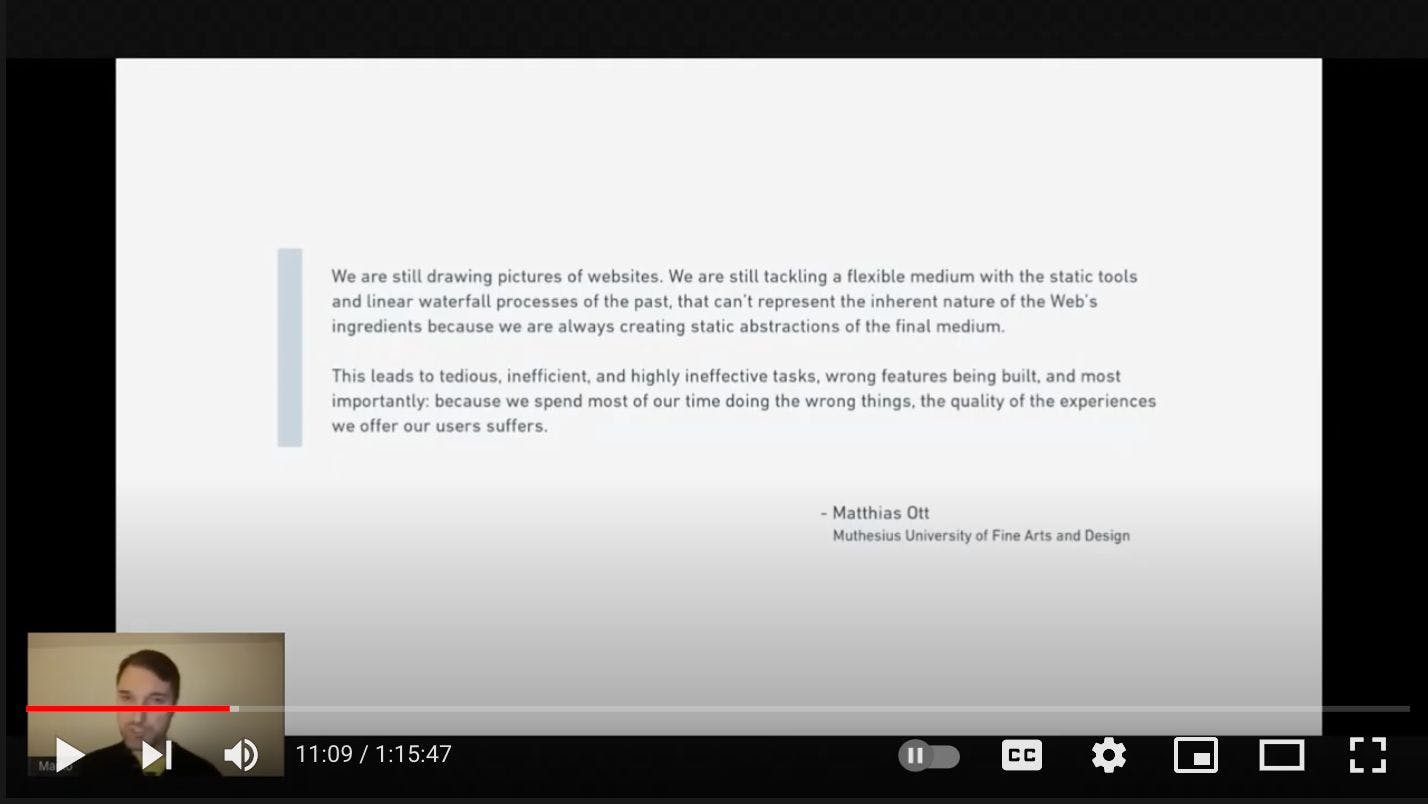
Audio Presented by
#a11y not only for humans, but also machines - for the semantic web. {content, semantics, accessibility}-first design.


#a11y not only for humans, but also machines - for the semantic web. {content, semantics, accessibility}-first design.
About Author

#a11y not only for humans, but also machines - for the semantic web. {content, semantics, accessibility}-first design.
Comments

















