
3,970 reads
How to Build a Production-Grade Text2SQL Engine
by byDataStax, an IBM Company@datastax
byDataStax, an IBM Company@datastax
DataStax, an IBM company, provides integrated AI dev platforms that let you harness data in your app without building a complex tool stack.
August 13th, 2024


















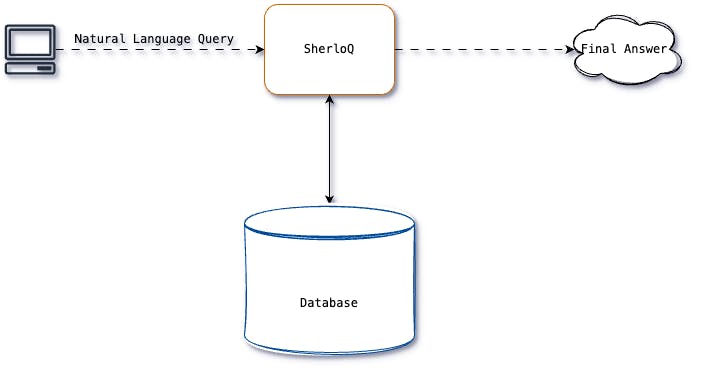
DataStax, an IBM company, provides integrated AI dev platforms that let you harness data in your app without building a complex tool stack.


DataStax, an IBM company, provides integrated AI dev platforms that let you harness data in your app without building a complex tool stack.
About Author

DataStax, an IBM company, provides integrated AI dev platforms that let you harness data in your app without building a complex tool stack.
Comments

















