





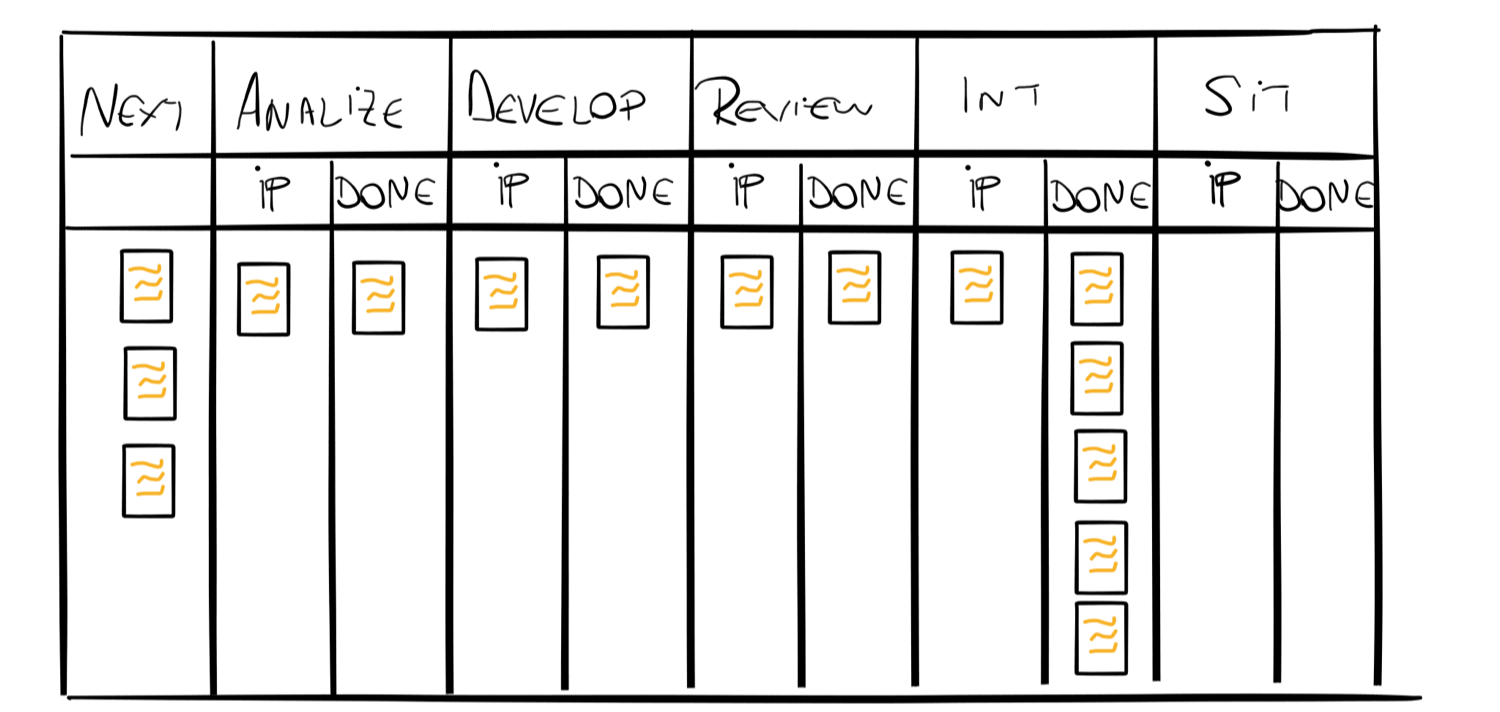









A mechanism for building a roadmap

Jan 09, 2018

Learning agile while practicing. Programmer, husband, father. Cyclist wannabe. I try to be the best
Learning agile while practicing. Programmer, husband, father. Cyclist wannabe. I try to be the best
Learning agile while practicing. Programmer, husband, father. Cyclist wannabe. I try to be the best
Learning agile while practicing. Programmer, husband, father. Cyclist wannabe. I try to be the best








