9,380 reads
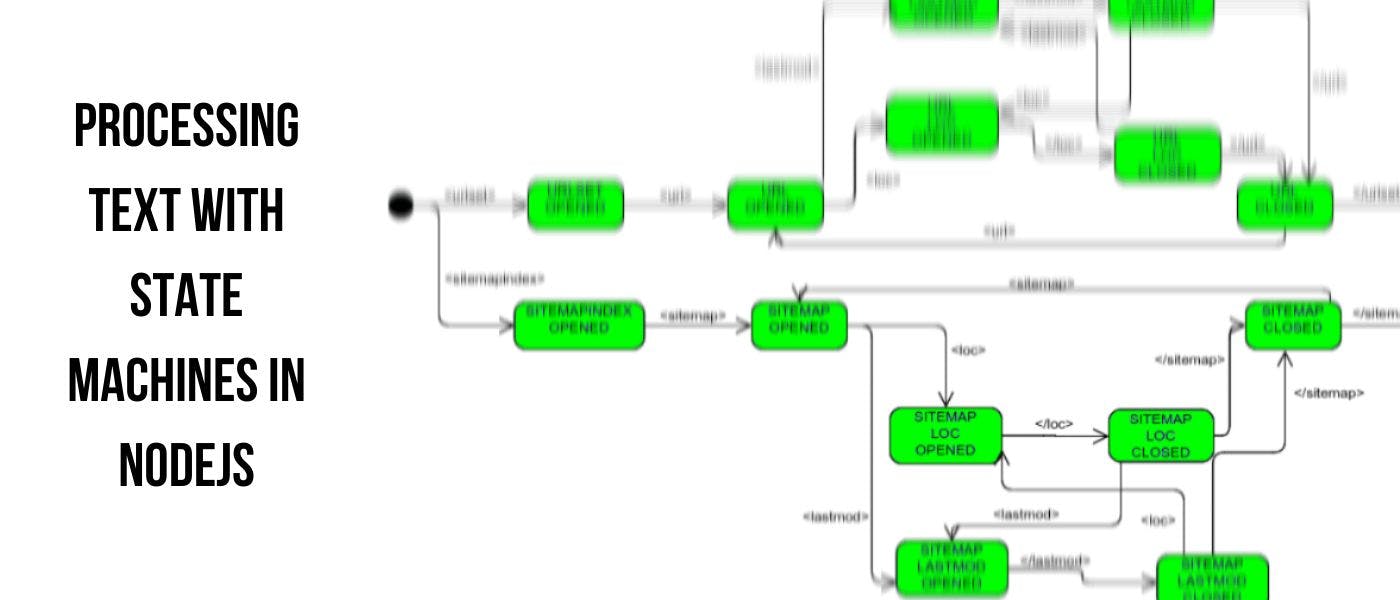
High Performance Text Parsing Using Finite State Machines (FSM)
by
February 13th, 2021






Audio Presented by



About Author

Senior Software Architect / Engineering Lead at Behavioral Signals
Comments

Senior Software Architect / Engineering Lead at Behavioral Signals