
138 reads
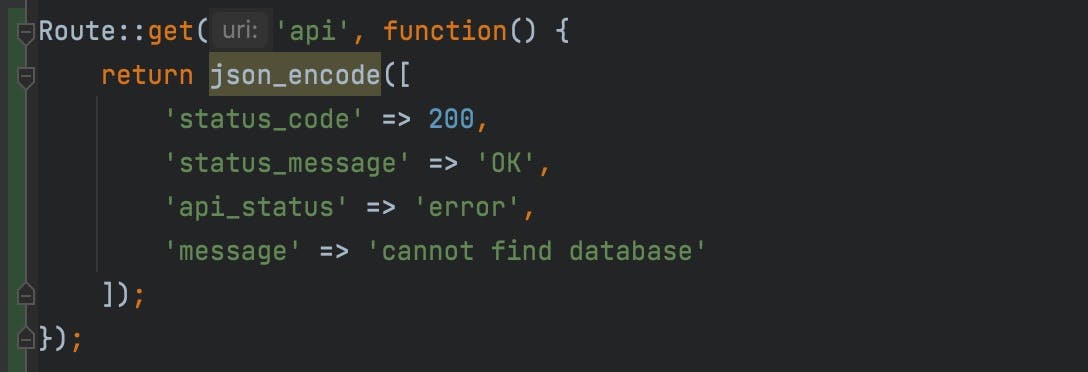
Handling Data Integrity Issues Like a Pro
by
November 23rd, 2021





Audio Presented by


About Author

On an exciting journey to learn new things all the time.
Comments

TOPICS
THIS ARTICLE WAS FEATURED IN





Related Stories












10 Threats to an Open API Ecosystem
Jul 18, 2022