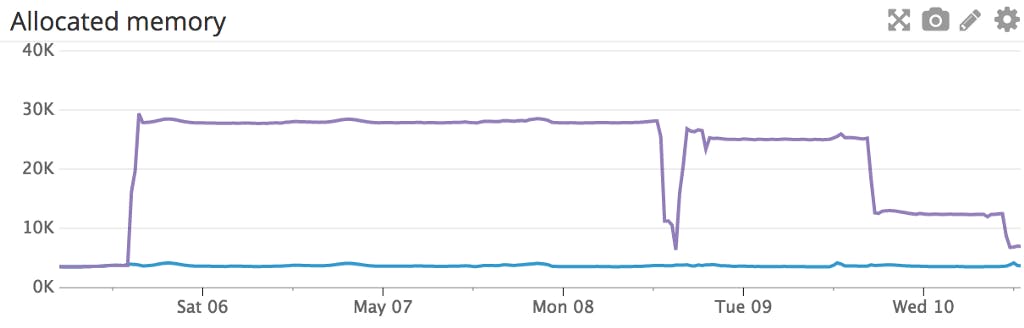
The most fun thing I’ve been working on in recent history is a graph database we use at to catch bad people. The database has been growing like crazy and currently the largest machine has something under 200 million nodes. Ravelin We don’t consider this database to be a “source of truth”, but it does need some level of persistence in order to restart quickly after failures or (hopefully more often) when deploying new code. Until recently we used the excellent for this, but we’ve come to realise that our use case has a lot of random writes and causes significant write amplification with BoltDB. Even a small change results in many write IOPS. We found that even with fast local SSDs we were running out of write IOPS in certain situations. BoltDB Originally when we built the database, we imagined that BoltDB would allow us to run a database that was bigger than the machine’s memory. But experience showed us that if we let the database grow larger than RAM we would see occasional severe slow-downs. So we decided to change our persistence story. We would unashamedly keep everything in RAM, and just keep a “transaction log” of changes to the database written to disk. When we needed to restart we would read the entire transaction log and reconstruct our in-memory structures. Writes to the database would require a single IOP to write the change to the log, and restarts would involve nice big buffered sequential reads, which can be shockingly fast. Now, we worked hard to minimise the number of memory allocations we made to build our data structures and to keep the structures small, but the amount of Go heap memory we used jumped quite considerably. The total amount of RAM we used didn’t change much (or perhaps even decreased), but most of the memory used by BoltDB is rather than heap memory. The Go heap memory jumped from around 4GB with most of the data in BoltDB, to just under 30GB in our new system. memory mapped files And why does this matter I hear you ask? Well, crucially, the Go garbage collector does not know anything about memory mapped files. When it wants to see if a piece of memory is referenced anywhere it does not even consider memory mapped files. But if you allocate memory on the heap, even as a relatively small number of large allocations, then the GC will scan it, looking for pointers to other allocations. And that will use CPU. What we found is that CPU usage increased as soon as we moved our memory to the heap. With ~30GB allocated, this averaged out to about 5% CPU on a 16 CPU system. When we looked in more detail we discovered this was actually all 16 CPUs running at 100% for around a second every 5 minutes. I’m not sure this would actually be a problem. Our CPU usage with this system is pretty low on average (we need to buy CPUs to get RAM!). But it’s very untidy, and I didn’t like it! CPU usage followed heap memory usage. As we moved more data to anonymous memory maps the CPU usage dropped. Certainly the GC stop-the-world pause times remained resolutely low, which is pretty impressive! Well done Go GC! Even with massively increased heap usage, GC pauses barely moved. So what could I do about it? Well, when we ran in BoltDB the data was in RAM, but it was stored in a large memory mapped file rather than on heap. In my replacement system I could use anonymous memory maps to store my data. These are just memory mapped files without a file, or in other words, just some memory. Yes, just some memory with a fancy name to make it sound complicated. Instead of asking Go for memory, we would ask the OS directly. With judicious use of the “unsafe” and “syscall” packages I could replace some of my very large slices with slices backed by memory maps. We used two syscalls: SYS_MMAP to allocate the maps, and SYS_MREMAP to grow them. With these you can build what look exactly like normal Go slices that are backed by memory allocated directly from the OS. You can also make the slices grow beyond their original capacity without any copying. SYS_MREMAP allows you to make a memory allocation made with SYS_MMAP bigger. It uses the OS virtual memory manager to assign a larger piece of the process virtual address space to the allocation, and assigns more pages of physical RAM to back it. This may cause the address of the memory as seen by your program to change if there’s already an object in memory that would clash with the extended allocation. But this is no different to a normal slice that grows beyond its initial capacity and has to be copied into another allocation. We want to grow our data at 4000–5000, but some kittens are in the way. mremap allocates a new region of address space at 6000–8000 and moves the physical memory pages to the new region, as well as adding some new ones. No copying is required The one big caveat is that you cannot store pointers to normal Go heap allocations in these structures unless they are also referenced by heap memory. Go will not find the reference to the allocation in your off-heap memory, and so will free it underneath you. For me, this meant I also needed to copy strings to a memory map before storing them. I did not replace a large hash map, so the heap memory usage is still larger than the old system, but it got pretty close. And as I moved chunks of data into memory maps the CPU usage dropped in rough proportion, confirming my hypothesis that the garbage collector was behind it. Which is nice. I’d be very interested in hearing from anyone else using a “not small” amount of RAM in a long-running Go application, particularly if their experience does not match ours, or if they’ve solved the problem differently. By day, Phil uses his coding super-power to fight crime at ravelin.com . Perhaps you can join him ? If you even read this bit, try hitting the heart button and further miracles may occur!