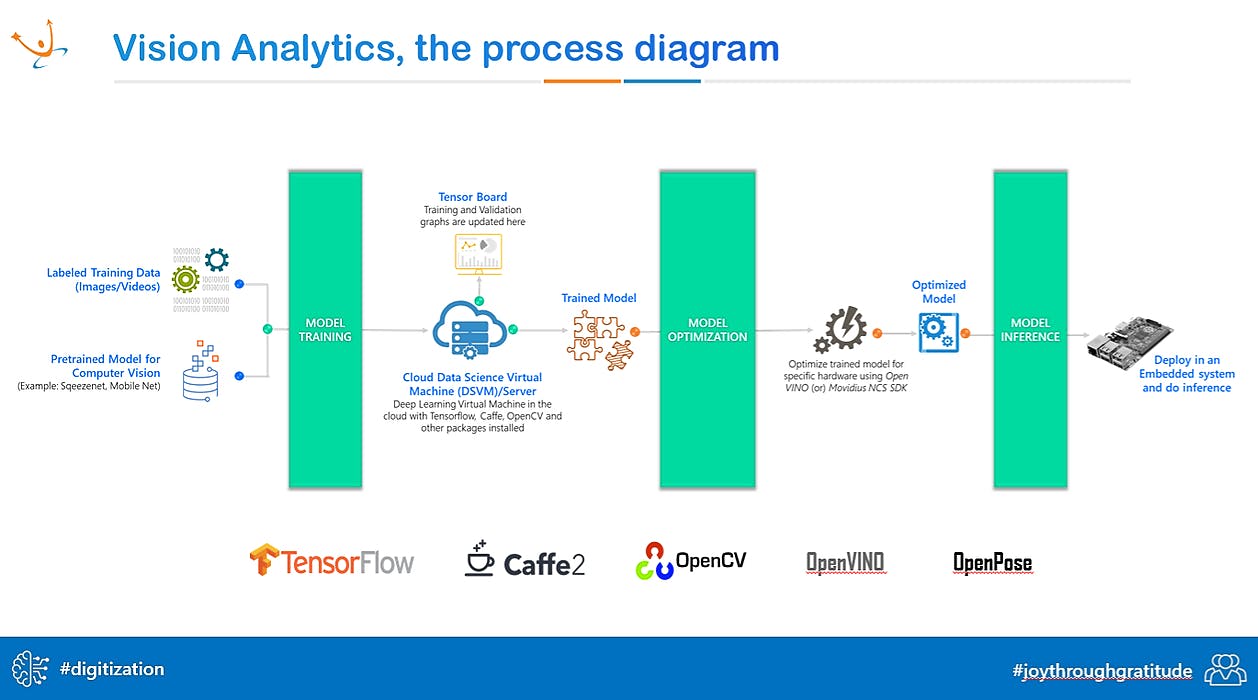
Gradient Descent. Image taken from - https://community.deeplearning.ai/t/difference-between-rmsprop-and-adam/310187 What Is Gradient Descent? Gradient descent is like hiking downhill with your eyes closed, following the slope until you hit the bottom (or at least a nice flat spot to rest). Technically, it is a method to minimize an objective function F(θ), parameterized by a model’s parameters θ∈Rn, by updating them in the opposite direction of the gradient ∇F(θ). The size of each step is controlled by the learning rate α. Think of α as the cautious guide who ensures you don’t tumble down too fast. If this sounds like Greek, feel free to check out my previous article, Quick Glance At Gradient Descent In Machine Learning — I promise it’s friendlier than it sounds! 🙂 Circle back: An objective function is the mathematical formula or function that your model aims to minimize (or maximize, depending on the goal) during training. It represents a measure of how far off your model’s predictions are from the actual outcomes or desired values. For example:In machine learning, it could be a loss function like Mean Squared Error (MSE) for regression tasks or Cross-Entropy Loss for classification tasks.The objective function maps the model’s predictions to a numerical value, where smaller values indicate better performance.In simpler terms:It’s like a “fitness tracker” for your model — it tells you how good or bad your model’s predictions are. During optimization, gradient descent helps adjust the model’s parameters θ to reduce this value step by step, moving closer to an ideal solution. Got it? 😄 Gradient Descent Variants Gradient descent isn’t a one-size-fits-all deal. It comes in three variants, each like a different hiker — some take the scenic route, others sprint downhill, and a few prefer shortcuts (like me 😅). These variants balance accuracy and speed, depending on how much data they use to calculate the gradient. 1. Batch Gradient Descent Batch gradient descent, the “all-or-nothing” hiker, uses the entire dataset to compute the gradient of the cost function: Imagine stopping to look 👀 at every rock 🪨, tree 🌴, and bird 🕊 before deciding where to place your foot 🦶🏽next. It’s thorough, but not ideal if your dataset is as big as, say, the Amazon rainforest 😩. It’s also not great if you need to learn on the fly — like updating your hiking route after spotting a bear 🐻❄️. Code Example: for i in range(nb_epochs): params_grad = evaluate_gradient(loss_function, data, params) params = params - learning_rate * params_grad Batch gradient descent shines when you have all the time in the world and a dataset that fits neatly into memory. It’s guaranteed to find the global minimum for convex surfaces (smooth hills) or a local minimum for non-convex surfaces (rugged mountains). 2. Stochastic Gradient Descent (SGD) SGD is the “impulsive” hiker who takes one step at a time based on the current terrain: It’s faster because it doesn’t bother calculating gradients for the entire landscape. Instead, it uses one training example at a time. While this saves time, the frequent updates can make SGD look like it’s zigzagging downhill, which can be both exciting and a little chaotic. 😅 Imagine updating your grocery list after each aisle — you get to the essentials faster, but your cart might look wild in the process. However, with a learning rate that slows down over time, SGD can eventually reach the bottom (or the best local minimum). Code Example: for i in range(nb_epochs): np.random.shuffle(data) for example in data: params_grad = evaluate_gradient(loss_function, example, params) params = params - learning_rate * params_grad 3. The Hero of the Day: Adam 🙌🏽 Now let’s talk about Adam — the “hiking guru” who combines the wisdom of Momentum and RMSprop. Adaptive Moment Estimation (Adam) is like having a smart guide who tracks the terrain and adjusts your steps based on past experiences and current conditions. It’s the go-to optimizer when you want to train neural networks and still have time for coffee. Why You’ll Love Adam Low Memory Requirements: It’s like carrying a lightweight backpack — efficient but still packed with essentials. Minimal Hyperparameter Tuning: Adam works well out of the box, so you won’t need to fiddle with too many knobs (just keep an eye on the learning rate). Practical Use: From improving product recommendations to recognizing images of cats on the internet, Adam powers machine learning systems that make your everyday tech smarter. How Adam Works Adam maintains moving averages of gradients (mt) and squared gradients (vt) to adapt learning rates for each parameter: Here’s the cool part: Adam corrects biases to ensure accuracy, and updates parameters using this formula: where m^t and v^t are bias-corrected estimates, and epsilon ϵ is a small number to prevent division by zero. Conclusion Adam is the Swiss Army knife of optimizers — versatile, efficient, and reliable. Whether you’re training neural networks to detect fraud or create next-gen chatbots, Adam helps you get there faster and with fewer headaches. So, embrace Adam, take confident steps, and enjoy the view from the summit of machine learning success! References: https://www.ceremade.dauphine.fr/\~waldspurger/tds/22_23_s1/advanced_gradient_descent.pdf https://www.geeksforgeeks.org/rmsprop-optimizer-in-deep-learning/ Gradient Descent. Image taken from - https://community.deeplearning.ai/t/difference-between-rmsprop-and-adam/310187 Gradient Descent. Image taken from - https://community.deeplearning.ai/t/difference-between-rmsprop-and-adam/310187 What Is Gradient Descent? Gradient descent is like hiking downhill with your eyes closed, following the slope until you hit the bottom (or at least a nice flat spot to rest). Technically, it is a method to minimize an objective function F(θ ), parameterized by a model’s parameters θ∈Rn, by updating them in the opposite direction of the gradient ∇F(θ). objective function F(θ The size of each step is controlled by the learning rate α. Think of α as the cautious guide who ensures you don’t tumble down too fast. If this sounds like Greek, feel free to check out my previous article, Quick Glance At Gradient Descent In Machine Learning — I promise it’s friendlier than it sounds! 🙂 Circle back: An objective function is the mathematical formula or function that your model aims to minimize (or maximize, depending on the goal) during training. It represents a measure of how far off your model’s predictions are from the actual outcomes or desired values. For example: In machine learning, it could be a loss function like Mean Squared Error (MSE) for regression tasks or Cross-Entropy Loss for classification tasks. The objective function maps the model’s predictions to a numerical value, where smaller values indicate better performance. In simpler terms: It’s like a “fitness tracker” for your model — it tells you how good or bad your model’s predictions are. During optimization, gradient descent helps adjust the model’s parameters θ to reduce this value step by step, moving closer to an ideal solution. Got it? 😄 Circle back: An objective function is the mathematical formula or function that your model aims to minimize (or maximize, depending on the goal) during training. It represents a measure of how far off your model’s predictions are from the actual outcomes or desired values. Circle back: objective function For example: In machine learning , it could be a loss function like Mean Squared Error (MSE) for regression tasks or Cross-Entropy Loss for classification tasks. machine learning loss function The objective function maps the model’s predictions to a numerical value , where smaller values indicate better performance. numerical value In simpler terms: It’s like a “fitness tracker” for your model — it tells you how good or bad your model’s predictions are. During optimization, gradient descent helps adjust the model’s parameters θ to reduce this value step by step, moving closer to an ideal solution. Got it? 😄 Gradient Descent Variants Gradient descent isn’t a one-size-fits-all deal. It comes in three variants, each like a different hiker — some take the scenic route, others sprint downhill, and a few prefer shortcuts (like me 😅). These variants balance accuracy and speed, depending on how much data they use to calculate the gradient. 1. Batch Gradient Descent Batch gradient descent, the “all-or-nothing” hiker, uses the entire dataset to compute the gradient of the cost function: Imagine stopping to look 👀 at every rock 🪨, tree 🌴, and bird 🕊 before deciding where to place your foot 🦶🏽next. It’s thorough, but not ideal if your dataset is as big as, say, the Amazon rainforest 😩. It’s also not great if you need to learn on the fly — like updating your hiking route after spotting a bear 🐻❄️. Code Example: Code Example: for i in range(nb_epochs): params_grad = evaluate_gradient(loss_function, data, params) params = params - learning_rate * params_grad for i in range(nb_epochs): params_grad = evaluate_gradient(loss_function, data, params) params = params - learning_rate * params_grad Batch gradient descent shines when you have all the time in the world and a dataset that fits neatly into memory. It’s guaranteed to find the global minimum for convex surfaces (smooth hills) or a local minimum for non-convex surfaces (rugged mountains). 2. Stochastic Gradient Descent (SGD) SGD is the “impulsive” hiker who takes one step at a time based on the current terrain: It’s faster because it doesn’t bother calculating gradients for the entire landscape. Instead, it uses one training example at a time. While this saves time, the frequent updates can make SGD look like it’s zigzagging downhill, which can be both exciting and a little chaotic. 😅 Imagine updating your grocery list after each aisle — you get to the essentials faster, but your cart might look wild in the process. However, with a learning rate that slows down over time, SGD can eventually reach the bottom (or the best local minimum). Code Example: Code Example: for i in range(nb_epochs): np.random.shuffle(data) for example in data: params_grad = evaluate_gradient(loss_function, example, params) params = params - learning_rate * params_grad for i in range(nb_epochs): np.random.shuffle(data) for example in data: params_grad = evaluate_gradient(loss_function, example, params) params = params - learning_rate * params_grad 3. The Hero of the Day: Adam 🙌🏽 Now let’s talk about Adam — the “hiking guru” who combines the wisdom of Momentum and RMSprop . Adaptive Moment Estimation (Adam) is like having a smart guide who tracks the terrain and adjusts your steps based on past experiences and current conditions. It’s the go-to optimizer when you want to train neural networks and still have time for coffee. Momentum RMSprop Why You’ll Love Adam Low Memory Requirements: It’s like carrying a lightweight backpack — efficient but still packed with essentials. Minimal Hyperparameter Tuning: Adam works well out of the box, so you won’t need to fiddle with too many knobs (just keep an eye on the learning rate). Practical Use: From improving product recommendations to recognizing images of cats on the internet, Adam powers machine learning systems that make your everyday tech smarter. Low Memory Requirements: It’s like carrying a lightweight backpack — efficient but still packed with essentials. Low Memory Requirements: It’s like carrying a lightweight backpack — efficient but still packed with essentials. Low Memory Requirements: Minimal Hyperparameter Tuning: Adam works well out of the box, so you won’t need to fiddle with too many knobs (just keep an eye on the learning rate). Minimal Hyperparameter Tuning: Adam works well out of the box, so you won’t need to fiddle with too many knobs (just keep an eye on the learning rate). Minimal Hyperparameter Tuning: Practical Use: From improving product recommendations to recognizing images of cats on the internet, Adam powers machine learning systems that make your everyday tech smarter. Practical Use: From improving product recommendations to recognizing images of cats on the internet, Adam powers machine learning systems that make your everyday tech smarter. Practical Use: How Adam Works Adam maintains moving averages of gradients (mt) and squared gradients (vt) to adapt learning rates for each parameter: Here’s the cool part: Adam corrects biases to ensure accuracy, and updates parameters using this formula: where m^t and v^t are bias-corrected estimates, and epsilon ϵ is a small number to prevent division by zero. Conclusion Adam is the Swiss Army knife of optimizers — versatile, efficient, and reliable. Whether you’re training neural networks to detect fraud or create next-gen chatbots, Adam helps you get there faster and with fewer headaches. So, embrace Adam, take confident steps, and enjoy the view from the summit of machine learning success! References: https://www.ceremade.dauphine.fr/\~waldspurger/tds/22_23_s1/advanced_gradient_descent.pdf https://www.ceremade.dauphine.fr/\~waldspurger/tds/22_23_s1/advanced_gradient_descent.pdf https://www.geeksforgeeks.org/rmsprop-optimizer-in-deep-learning/ https://www.geeksforgeeks.org/rmsprop-optimizer-in-deep-learning/



















![What Are Convolution Neural Networks? [ELI5]](https://hackernoon.imgix.net/images/69s32rn.jpg?auto=format&fit=max&w=3840)