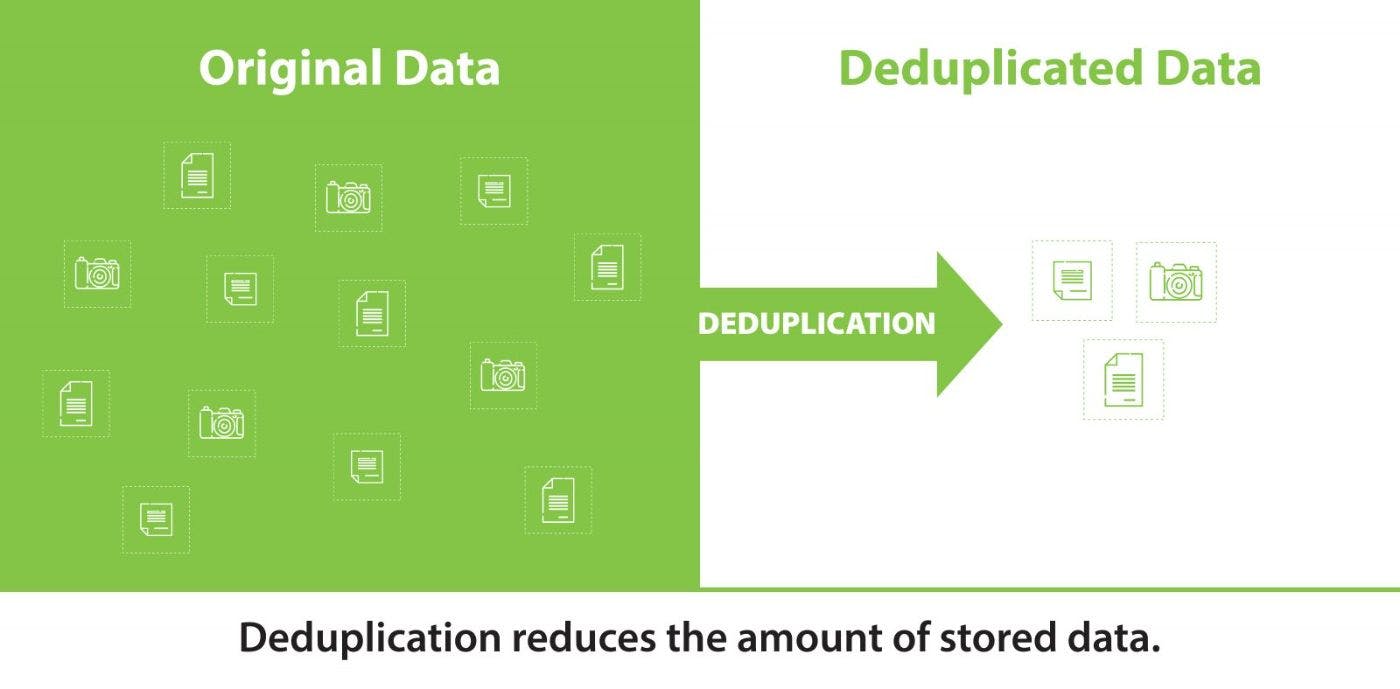
Deduplication serves a variety of purposes and can be applied in numerous scenarios to address specific challenges effectively. Consider the situation where you possess a vast collection of personal photos stored on your computer. To ensure a backup of these photos, you wish to replicate them onto an external USB HDD. However, due to the immense quantity of photos, they exceed the disk's capacity. While purchasing additional storage is not part of your plan, having some form of backup is crucial. This is where deduplication technology comes into play, offering a viable solution. Alternatively, imagine you have a corporate server housing critical data backups, with another copy stored in a separate office. However, you desire an additional offline backup that can be periodically connected through a NAS device (tape backups may not be feasible for you). The periodic connection is deliberate as it provides protection against potential online threats such as ransomware, enabling you to maintain a "cold" backup within close reach. Nevertheless, the NAS device's capacity is limited to a few terabytes, while the backup itself occupies significantly more space. Furthermore, there are scenarios involving ephemeral VMs deployed by the thousands per day, which individually do not possess important data, but collectively consume considerable disk space due to shared libraries. So, what exactly is deduplication? Deduplication, in the context of data management, refers to the process of identifying and eliminating duplicate data within a file system. By doing so, deduplication reduces overall data size and mitigates storage costs. It's worth noting that deduplication can also be implemented within databases, although that aspect falls beyond the scope of this article. Types and Variants of Data Deduplication: Block-level Deduplication: This method involves identifying redundant data blocks within a file system and retaining only one instance of each unique block. Rather than duplicating these blocks, references to the singular copy are established, resulting in significant savings in disk space. File-level Deduplication: With file-level deduplication, redundancy is assessed at the file level. The system identifies duplicate files and stores only a single copy of each unique file. Instead of creating duplicate files, the system employs references that point to the shared copy. Content-aware Deduplication at the Block Level: Content-aware deduplication analyzes the actual content of data blocks to identify duplicates. It can detect and remove identical blocks, even when they are physically scattered across different locations within the file system or exhibit minor discrepancies. Implementations of data deduplication often combine multiple approaches to achieve optimal results. Additionally, deduplication can be implemented either "inline" or through "post-processing." Inline Deduplication: This technique executes deduplication in real-time as data is being written to the disk. During the process of adding new data to the file system, the system identifies duplicates and eliminates redundant data blocks before storing the data on the disk. This eliminates the need to store duplicate data and instantaneously saves storage space. An excellent example of inline deduplication is when you transfer 10TB of data to a disk that incorporates inline deduplication, resulting in a storage volume of 5TB. Assuming a deduplication ratio of x2 based on your data type. Post-processing Deduplication: In contrast, post-processing deduplication occurs after the data has already been written to the disk. This background process scans the file system, identifies duplicate data blocks, and removes redundant copies. While post-processing deduplication may require more resources, as it entails scanning the entire file system to identify repetitions, it can be highly effective, especially for file systems where data frequently undergoes changes. For instance, suppose you possess a 10TB disk nearing its capacity, and you wish to reclaim storage space without deleting any data. In that case, post-processing deduplication serves as a suitable solution. While other deduplication implementation variations such as Target Deduplication and Source Deduplication exist, these are primarily utilized within specialized software or Storage Area Networks (SANs), making their assessment and verification challenging within a home lab environment. Our lab environment: Virtualbox 7.0.4 Host PC: Intel Core i7-10510U CPU 1.80GHz / 2.30 GHz 4 CPU 32GB RAM NVME Samsung SSD 970 EVO Plus 1TB Windows Server 2022 2 vCPU 4GB RAM Ubuntu Server 23.04 ZFS 2 vCPU 4GB RAM Ubuntu Server 23.04 BTRFS 2 vCPU 4GB RAM Zabbix Appliance 6.4.3 2 vCPU 4GB RAM Official documentation can be found here: https://www.zabbix.com/download_appliance Dataset: 103 GB (111,144,359,353 bytes) Within a tar.gz archive, there are backups of website data. When it comes to website backups, deduplication can play a significant role in optimizing storage utilization and ensuring efficient backup processes. Website backups often contain redundant data, especially if multiple backups have been taken over time. Deduplication technology can identify and eliminate duplicate files or blocks within the backup archive, resulting in reduced storage requirements and faster backup operations. By employing deduplication techniques, you can store only unique files or blocks and replace duplicates with references to a single copy. This approach minimizes the overall storage space needed for storing website backups while ensuring that all essential data remains intact. With block-level deduplication, redundant data blocks within the backup archives can be identified, allowing for storing only one instance of each unique block. Consequently, the storage space required for multiple backups can be significantly reduced by eliminating duplicate blocks. Furthermore, file-level deduplication can identify identical files across different backup archives and store only one copy of each unique file. Instead of duplicating files across backups, references or pointers can be used to access the shared copy, saving considerable storage space. In cases where backups contain similar or slightly modified versions of files, content-aware deduplication at the block level becomes valuable. This method analyzes the actual content of data blocks and identifies duplicate blocks, even if they are located in different positions within the backup archives or possess minor differences. Through content-aware deduplication, storage efficiency can be further enhanced by removing redundant blocks and replacing them with references to the unique blocks. Implementing deduplication within website backup archives can significantly reduce the required storage capacity, streamline backup processes, and optimize overall data management. By eliminating duplicate data and retaining only unique files or blocks, deduplication ensures efficient use of storage resources while maintaining the integrity of the backup data. To minimize performance degradation on the host machine, I performed the tests sequentially. This ensured that only the Zabbix VM and the VM undergoing deduplication testing were active at the same time, while the other two VMs were powered off. This approach helped mitigate any potential impact on overall system performance. Linux ZFS Initiating the dataset copy process Now that the dataset has been successfully copied, let's examine the status of the zpool statistics: ~$ zpool list NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT dedup-pool 119G 104G 15.4G - - 2% 87% 1.00x ONLINE - The dataset was copied in approximately 18 minutes, but the deduplication process took longer, taking around 30 minutes: Now, let's examine the CPU as well: There is not much disparity in terms of memory utilization. The deduplication process has yielded a disk space utilization of around 33 GB, achieving an impressive deduplication ratio of 3.39! $ zpool list NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT dedup-pool 119G 30.6G 88.4G - - 1% 25% 3.39x ONLINE - Let's examine the disk space utilization by Zabbix: However, looking at the percentages provides a more accurate representation: Overall, deduplication on the zpool yielded the following statistics: Initial usage: 104GB Post-deduplication usage: 30.6GB Deduplication ratio: 3.39 Infographic: Conclusions. In conclusion, ZFS proves to be an effective solution for optimizing disk space utilization. However, it is crucial to consider the balance between memory and disk resources carefully. Additionally, the type of data being stored and deduplicated plays a significant role in achieving optimal results. By making informed decisions regarding resource allocation and understanding the nature of the data, users can maximize the benefits of ZFS deduplication. Linux BTRFS Initiating the file copying process: $ sudo btrfs fi usage /mnt/btrfs_disk Overall: Device size: 120.00GiB Device allocated: 107.02GiB Device unallocated: 12.98GiB Device missing: 0.00B Device slack: 0.00B Used: 103.73GiB Free (estimated): 14.47GiB (min: 7.98GiB) Free (statfs, df): 14.47GiB Data ratio: 1.00 Metadata ratio: 2.00 Global reserve: 112.08MiB (used: 0.00B) Multiple profiles: no Data,single: Size:105.00GiB, Used:103.51GiB (98.58%) /dev/sdb 105.00GiB Metadata,DUP: Size:1.00GiB, Used:113.28MiB (11.06%) /dev/sdb 2.00GiB System,DUP: Size:8.00MiB, Used:16.00KiB (0.20%) /dev/sdb 16.00MiB Unallocated: /dev/sdb 12.98GiB As we can see, approximately 103.73GiB is occupied Results: $ sudo btrfs fi usage /mnt/btrfs_disk Overall: Device size: 120.00GiB Device allocated: 108.02GiB Device unallocated: 11.98GiB Device missing: 0.00B Device slack: 0.00B Used: 82.30GiB Free (estimated): 35.88GiB (min: 29.89GiB) Free (statfs, df): 35.87GiB Data ratio: 1.00 Metadata ratio: 2.00 Global reserve: 97.64MiB (used: 0.00B) Multiple profiles: no Data,single: Size:106.01GiB, Used:82.11GiB (77.46%) /dev/sdb 106.01GiB Metadata,DUP: Size:1.00GiB, Used:100.41MiB (9.81%) /dev/sdb 2.00GiB System,DUP: Size:8.00MiB, Used:16.00KiB (0.20%) /dev/sdb 16.00MiB Unallocated: /dev/sdb 11.98GiB The entire process lasted for more than 7 hours. However, the deduplication results were not as impressive as anticipated. The initially occupied space was 103.73GiB, and after the deduplication process, it reduced to only 82.30GiB, resulting in a modest reduction of approximately 20.66%. Infographic: Conclusions: On the other hand, it is evident that BTRFS is less demanding in terms of memory requirements. However, considering the compression results achieved, the importance of memory utilization becomes less significant for me personally. Windows NTFS Initiating the file transfer process to our system: PS C:\Windows\system32> Get-DedupStatus FreeSpace SavedSpace OptimizedFiles InPolicyFiles Volume --------- ---------- -------------- ------------- ------ 16.38 GB 0 B 0 0 E: PS C:\Windows\system32> Get-DedupVolume -Volume E: Enabled UsageType SavedSpace SavingsRate Volume ------- --------- ---------- ----------- ------ True Default 0 B 0 % E: PS C:\Windows\system32> Get-DedupProperties -DriveLetter E InPolicyFilesCount : 0 InPolicyFilesSize : 0 OptimizedFilesCount : 0 OptimizedFilesSavingsRate : 0 OptimizedFilesSize : 0 SavingsRate : 0 SavingsSize : 0 UnoptimizedSize : 111247380480 PSComputerName : Here are the results: PS C:\Windows\system32> Get-DedupStatus FreeSpace SavedSpace OptimizedFiles InPolicyFiles Volume --------- ---------- -------------- ------------- ------ 112.85 GB 98.11 GB 377 377 E: PS C:\Windows\system32> Get-DedupVolume -Volume E: Enabled UsageType SavedSpace SavingsRate Volume ------- --------- ---------- ----------- ------ True Default 98.11 GB 93 % E: PS C:\Windows\system32> Get-DedupProperties -DriveLetter E InPolicyFilesCount : 377 InPolicyFilesSize : 111144308918 OptimizedFilesCount : 377 OptimizedFilesSavingsRate : 94 OptimizedFilesSize : 111144308918 SavingsRate : 93 SavingsSize : 105341122774 UnoptimizedSize : 112999258326 PSComputerName : Remarkably, the deduplication results proved to be quite impressive. The data size was reduced by an astonishing 93%! As a result, the occupied disk space now stands at a mere 7.13GB, compared to the initial 103GB. This substantial reduction in data volume not only optimizes storage efficiency but also enables significant savings in precious disk space. Infographic: Results: Deduplication proved to be remarkably efficient for my Windows dataset, offering an exceptional data compression ratio - a true dream! However, it's regrettable that Microsoft has imposed proprietary restrictions and limitations that prevent the utilization of deduplication in the regular version of Windows. Unfortunately, this feature is only available in Windows Server. Deduplication of data is the process of identifying and removing duplicate data within a file system. This helps reduce the amount of disk space used and lowers storage costs. The article discussed various types of deduplication, such as block-level and file-level deduplication, as well as content-aware deduplication at the block level. Deduplication can be implemented either inline or through post-processing. Inline deduplication checks for duplicates and removes them before writing the data to disk, immediately saving space. Post-processing deduplication scans the file system and removes duplicates after the data has been written to disk. Linux ZFS and Windows (on Windows Server) offer effective implementations of data deduplication. For example, Windows achieved an impressive 93% data compression, resulting in significant disk space savings. However, Windows has limitations, and deduplication is only available on Windows Server. Linux BTRFS with BEES showed less impressive deduplication results compared to ZFS and Windows. Although it is less memory-intensive, the space compression results are not as remarkable. The choice between memory and disk resources, as well as the type of data, can impact deduplication effectiveness. Overall, data deduplication can be beneficial in various scenarios, such as creating backups, reducing disk space usage, and optimizing storage resource utilization. However, when selecting a deduplication implementation, it is important to consider the specific characteristics of each system and data type to achieve the best results.