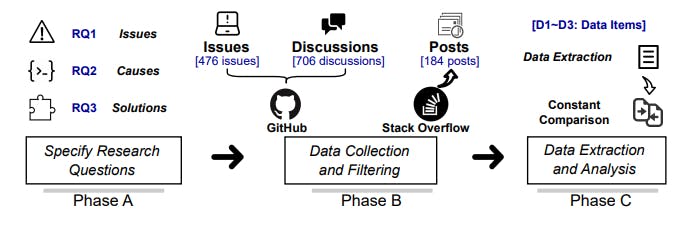
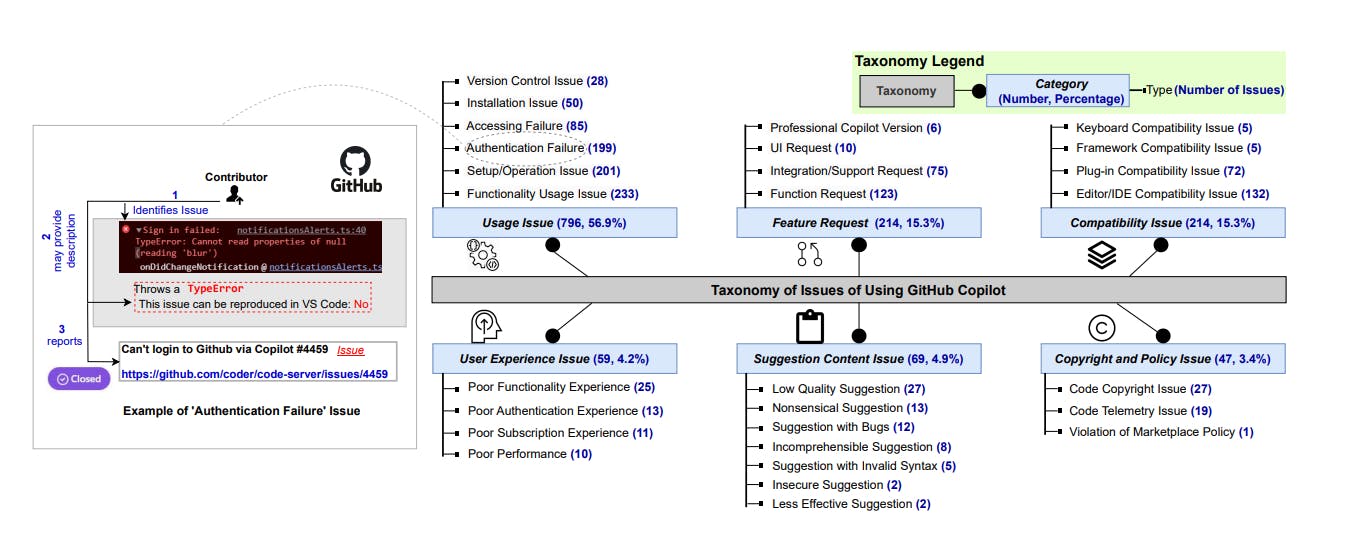
171 reads
Copilot vs. Humans: Comparing Vulnerability Rates in Code Generation
by byWhat is GitFlow? The Collaborative Git Alternative@gitflow
byWhat is GitFlow? The Collaborative Git Alternative@gitflow
A branching model for Git, created by Vincent Driessen. #1 blog dedicated exclusively to forwarding the GitFlow agenda.
May 28th, 2024






A branching model for Git, created by Vincent Driessen. #1 blog dedicated exclusively to forwarding the GitFlow agenda.
Story's Credibility


A branching model for Git, created by Vincent Driessen. #1 blog dedicated exclusively to forwarding the GitFlow agenda.
Story's Credibility
About Author

A branching model for Git, created by Vincent Driessen. #1 blog dedicated exclusively to forwarding the GitFlow agenda.
Comments