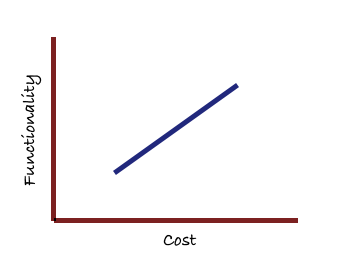
I struggled with how to think about complexity through much of my career, especially during the ten years I spent leading Office development. Modeling complexity impacted how we planned major releases, our technical strategy as we moved to new platforms, how we thought about the impact of new technologies, how we competed with Google Apps, how we thought about open source and throughout “frank and open” discussions with Bill Gates on our long term technical strategy for building the Office applications. I want to explore the issues I faced then and how our approach was influenced by how I thought about complexity. I’m currently rereading Melanie Mitchell’s “Complexity: A Guided Tour” and am heartened that even professional academics who study complexity full time have a hard time defining or measuring it. No breakthroughs here, I’m afraid, but let us try to construct a mental model that we can use to explore the topic. When we think about enhancing a software system, we can consider the curve that measures aggregate functionality against the aggregate cost required to achieve it. My impression from reading journalists and analysts writing about software is that they believe you have a linear curve that generally looks like this: This reflects a curve where the incremental cost of new functionality is relatively consistent over time as the product grows more capable. Could some breakthrough new technology or development strategy lift that curve up or improve its slope? Alternatively, the curve might look concave (also possibly changed in slope or translated up by some new technical strategy). This reflects a curve where new functionality gets to add over time, perhaps because you develop more and more infrastructure, expertise, process and tooling that makes adding new features more and more efficient. easier People who have worked in software for a long time tend to believe the curve actually looks convex, more like this: This reflects a model where new functionality gets to add as a system gets more functional. harder So which curve reflects reality and how does it impact strategy? As you might expect, it depends, but that final dismal curve probably captures the reality for large systems best. Let’s walk through a few examples. The FrontPage editor had key well-factored components like the lexical analyzer, HTML parser as well as core infrastructure built into the model and view that made it relatively straight-forward to extend the editor to support new HTML tags as the HTML standard evolved. The lexer and parser were driven from tables that described how classes of tags were handled so new tags simply required another entry in the table. Typically there was a small amount of custom rendering work and then whatever custom editing support was needed — typically just a relatively simple dialog to edit any special tag properties. The editor model automatically handled multi-level undo, redisplay, load and save. As we added support for certain features like parsing of server-side scripting languages like ASP, that support could be easily extended to also support other languages like PHP. It was clear that the powerful infrastructure we had built made adding certain types of new features much easier — resulting in something that looked like that concave curve above for many features. The FrontPage editor also offered a good counter-example to this rosy picture. The editor supported three different views for an HTML page that was loaded in the editor: “Normal” view was the typical WYSIWYG view used for editing, “HTML” showed a color-coded editable view of the underlying HTML tags and “Preview” showed the page in an embedded instance of Internet Explorer. Preview view was especially useful for verifying layout and testing dynamic behavior in the browser. Preview view had been an “overnight feature” that was added in a burst of programming by one of our developers who was a wizard with ActiveX programming and was also able to leverage the infrastructure we had already built to support independent views on the same document for Normal and HTML view. Unfortunately, Preview view ended up being a gift that kept on giving. The complexity it introduced had nothing to do with any failure in the initial programming of the feature. The challenges were that as we added new functionality, Preview required special consideration — additional specification — about how it should behave and interact with these new features. Frameset support (an early HTML feature that has fallen into disuse) was especially complex. As we added new support for server-side scripting and especially more and more support for editing SharePoint-based webs, we continually ran into questions about how Preview should work and then additional programming effort to implement that behavior. Eventually (especially as SharePoint and dynamic site support became more of a product focus) the team just removed the feature entirely. This was clearly a feature that turned that curve convex, making everything new harder to implement. Again, the problem was not because of poor design, the problem was that it interacted with many of the other features we were working on and required additional specification and additional code to implement that specification. Word offered another interesting example. When I moved to lead the Word development team for the Office 2007 product cycle, we were working with PowerPoint on enhancing visual support for tables. PowerPoint had done early prototyping of features that leveraged improving graphics support, including gradients, transparency, shadows and reflection. This early prototyping work led them to have a good grasp on how expensive these features would be to implement. They were pushing to get these features adopted consistently across the Office suite. Feature consistency helps users transfer learning between applications and improves visual and semantic consistency as content is copied and pasted between the applications. When the Word team went to estimate the cost of these features, they came back with estimates that were many times larger than PowerPoint’s estimates. Some of this cost was because the PowerPoint code architecture was better structured to add these types of visual features. But the bulk of the growth in estimates was because Word’s feature set interacted in ways that made the (and hence the implementation) more complex and more costly. How would the feature interact with spanning rows and spanning columns? How about running table headers? How should it show up in style sheets? How do you encode it for earlier versions of Word? What about all the different clipboard and output formats that Word supports — how should these features appear there? In Fred Brooks’ , this was complexity, not complexity. Features interact — intentionally — and that makes the cost of implementing the N+1 feature closer to N than 1. specification terms essential accidental This view that costs scale with feature depth because of growth in essential complexity leads to a great emphasis in continuously improving and refactoring the code base. If essential complexity growth is inevitable, you want to do everything you can to reduce ongoing accidental or unnecessary complexity. Of course, the difference between accidental and essential complexity is not always so clear when you are embedded in the middle of the project and to some extent is determined by the future evolution of the product. So it is “more guideline than rule” — internally we would talk about “20% for art”. When we started the OneNote project (first shipped in Office 2002), we seriously considered whether to build it on top of the very rich Word editing surface. The OneNote team eventually decided to “walk away” from Word’s complexity (and rich functionality) because they believed they needed to be free to innovate in a new direction without paying the cost of continually integrating with all Word’s existing functionality. They would settle for a much smaller initial “N” in order to be able to innovate in a new direction. That is a decision the team never regretted. They were able to innovate in storage model, sharing and a different overall content model with a relatively small team because they had full control of their end-to-end stack. Other “features” during this time period involved porting most of the Office suite to the 64-bit version of Windows and then later porting to ARM-based Windows (for Windows RT and later Windows Phone devices). The cost of this work scaled with the size of the code base (10’s of millions of lines of code) and added an ongoing multiplicative factor to our engineering system costs to support building, testing and shipping on these additional platforms. There were an ongoing number of these types of broad new product functionality that scaled with the size of the codebase. Security is first in line there and deserves a separate post, as does cross-platform. This perspective does cause one to turn a somewhat jaundiced eye towards claims of amazing breakthroughs with new technologies. Managed code was one that we argued about for a long time during this period. Leveraging open source also has some of the same dynamics. What I found is that advocates for these new technologies tended to confuse the productivity benefits of working on a small code base (small N essential complexity due to fewer feature interactions and small N cost for features that scale with size of codebase) with the benefits of the new technology itself — efforts using a new technology inherently start small so the benefits get conflated. Additionally, these new technologies (Java, C#, NodeJS is the latest one) start out with a much more functional initial set of base libraries and rich frameworks, certainly compared to what we saw in C and C++ and in the early days of either Mac or Windows application development. In terms of our Functionality/Cost curves, this means that you push that curve significantly up the functionality axis at the start. This can create confusion for technical managers about whether you have simply translated a curve that still has the same fundamental shape or whether you have changed something significant about the shape or slope of the curve itself. This is especially true in an environment where every disciple of a new technology is singing its praises to the heavens. In actual practice, if the product stays small, you can essentially “book” that initial productivity gain — a clear win. If the product starts to grow complex — and you can predict that fairly directly by looking at the size of the development team — then costs will come to be dominated by that increasing feature interaction and essential complexity. Project after project has demonstrated there is nothing about language or underlying technical infrastructure that changes that fundamental curve. The dynamic you see with especially long-lived code bases like Office is that the amount of framework code becomes dominated over time by the amount of application code and in fact frameworks over time get absorbed into the overall code base. The framework typically fails to evolve along the path required by the product — which leads to the general advice “you ship it, you own it”. This means that you eventually pay for all that code that lifted your initial productivity. So “free code” tends to be “free as in puppy” rather than “free as in beer”. None of this argues against “lean startups” or “minimal viable products” or any of the other approaches that focus on accelerating the process of finding the right product/market fit or feature viability. Continuous agile delivery is a fundamental change in development process because it removes the horrendous friction and delay between feature development and feature use. (There are other benefits as well but again worth a separate post.) But continuous delivery does not change anything about the essential complexity I am discussing here except so far as it helps prevent the team from building features that increase complexity but do not add user value. The highest cost feature you can build is the one that is not used or valued — your cost / benefit ratio is infinite. You continue paying to integrate with that useless feature as you build every additional feature from that point forward. The Office competition with Google Apps was (and still is) strongly influenced by these perspectives on complexity. The Office team had made the decision to build web applications just prior to the time Google bought Writely (the original version of Google Docs). As we looked at that product, we were well positioned to understand the competitive strategy from a technical and feature perspective. After a fairly quiet period in the productivity space, new browser-based applications were launching in multiple product areas. Delivering through the browser combined a number of key breakthroughs, especially compared to the consumer PC application environment of the time. The browser brought deployment and acquisition friction close to zero. Storing your content in the cloud allowed access to your content anywhere which was key as multiple PC use exploded in work, home and school. Content in the cloud then enabled easy sharing and co-editing, including later real-time co-authoring with features like chat and change notifications. Browser-based application delivery solved the deployment problem which was a huge issue for PC applications in the days before app stores. This enabled continuous delivery of new features as well as ensuring that everyone was up-to-date with the latest version. Free or freemium business models facilitated low friction sharing enabled by this technical strategy. In fact, one of the hardest aspects of responding to this competition was navigating the business model change from device-based licensing to a user subscription model that enabled a single user to stay up to date on the latest versions of Office on all their devices. Anyone that follows the tales of disruption in the technology industry is well-attuned to the fact that asymmetric business model attacks enabled by new technology advances is one of the most effective strategies a competitor can take. One thing that was clear to us was that the cloud/browser development strategy did not offer a breakthrough in the constraints of essential complexity like I am discussing here. In fact, the performance challenges with running large amounts of code or large data models in the browser and managing the high relative latency between the front and back end of your application generally make it harder to build complex applications in a web-based environment. Hyper-ventilation by journalists and analysts about the pace of Google App’s innovation generally ignored the fact that the applications remained relatively simple. Prior to joining Microsoft, I had built a highly functional multimedia document editor which included word-processing, spreadsheets, image, graphics, email and real-time conferencing with a couple other developers. I knew the pace of innovation that was possible when functionality was still relatively low (“highly functional” but still small N compared to the Office apps) and nothing I saw as Google Apps evolved challenged that. In fact, several areas that demonstrate real cross-cutting complexity challenges is where Google’s slower pace is especially relevant. Google Apps have been announcing some variant of offline editing for almost 8 years now and it is still semi-functional. The other “real soon now” promise is “better compatibility with Office”. This has the flavor of the laundry detergent claims of “now with blue crystals”! The claim of “better” is hard to argue with but history would seem to indicate they are not getting any closer to being compatible, especially as Office continues to evolve. The final area is in native applications. Google has built relatively simple native applications for mobile but has not shown any interest in really fully investing there. Native applications would add a high N degree of complexity to all future work because the base technology and architecture are so different from the web-based versions, at least if they are actually interested in leveraging native device capabilities. It was clear that they were going to either continue to only timidly invest in native code and real compatibility, or they would invest and immediately start facing these complexity challenges that would slow how fast they could evolve and focus on actual differentiation. Either approach would be good for us competitively and that view of their available options was strongly influenced by this model of essential complexity. actually None of this meant we took the challenge less seriously. In fact, it was clear that they were using an asymmetric technical attack of leveraging their simplicity to deliver sharing and co-editing features. These features were clearly differentiated and would be immensely hard to deliver on top of the existing highly functional (large N) Office apps. As we started building the web apps, we needed to decide whether we were going to “walk away” from our own complexity like we had when we developed OneNote or embrace the existing complexity, with the costs and constraints that that would imply for future development. The final decision to build the “Word Web App” rather than “a new web-based word processor from Microsoft that is not fully compatible with Word” (and similarly for Excel, PowerPoint and OneNote) was strongly driven by the belief that the file formats continued to serve as a critical competitive moat with immensely strong network effects. In fact, an argument can be made that the Office file formats represent one of the most significant network-based moats in business history (with Win32 and the iOS APIs as two others). Even applications like OpenOffice that were specifically designed to be clones have struggled with compatibility for decades. By embracing that complexity, and the costs, we would deliver something that we knew was fundamentally hard to match, especially if there was any confusion or hesitancy about the commitment required to compete. (I’ll just note that our decision to build the Sway product ( ) was fundamentally a decision to “walk away” from complexity and explore innovating in a way that could take a fundamentally different architectural approach from the existing Office apps without any of the compatibility constraints). http://sway.com It is now ten years later. Office has full platform coverage with native applications on all devices and highly functional and compatible web applications. These all support sharing, co-authoring and offline use. Full real-time co-editing is being rolled out now and was as hard to implement in the native applications as we had expected. Real-time co-editing, to the extent it is used and valued, reinforces the file format moat since it is technically implausible to imagine two independent implementations with different underlying data models achieving that fine degree of real-time interoperability. The Office implementations highly leverage shared code implementations of the core engines across both native and web clients to achieve that interoperability. Competitive strategy argues that when a competitor attempts to differentiate you need to focus on neutralizing that differentiation as quickly as possible. The path we took did not accomplish that. Google was able to establish a critical competitive beachhead by building on their differentiation. I think it is still too early to see how this will all play out. It is clear the Office apps would not be positioned functionally the way they are now (with fully compatible native and web clients on all devices and support for offline and co-editing) if there had been any squeamishness about embracing the challenges of complexity. That complexity (as it embodies valued functionality) the moat. is This is probably already way too long but I also wanted to just touch on the ongoing discussions we had with Bill Gates over my entire career at Microsoft that directly related to these perspectives on complexity. Bill wanted (still wants) a breakthrough in how we build rich productivity apps. He expected that the shape of that breakthrough would be to build a highly functional component that would serve as the core engine for all the applications. For a time he believed that Trident (the core engine for Internet Explorer) could become that component. That model leads you to invest in building a more and more functional component that represents more and more of the overall application (and therefore results in more of the cost of building each application being shared across all applications). This view that I have described here of increasing feature interaction causing increasing essential complexity leads to the conclusion that such a component would end up suffering from the union of all the complexity and constraints of the masters it needs to serve. Ultimately it collapses of its own weight. The alternate strategy is to emphasize isolating complexity, creating simpler functional components, and extracting and refactoring sharable components on an ongoing basis. That approach is also strongly influenced by the end-to-end argument and a view that you want to structure the overall system in a way that lets applications most directly optimize for their specific scenario and design point. That sounds a little apple pie and in practice is a lot messier to achieve than it is to proclaim. Determining which components are worth isolating, getting teams to agree and unify on them rather than letting “a thousand flowers bloom” is hard ongoing work. It does not end up looking like a breakthrough — it looks like an engineering team that is just getting things done. That always seemed like a worthy goal to me.