
356 reads
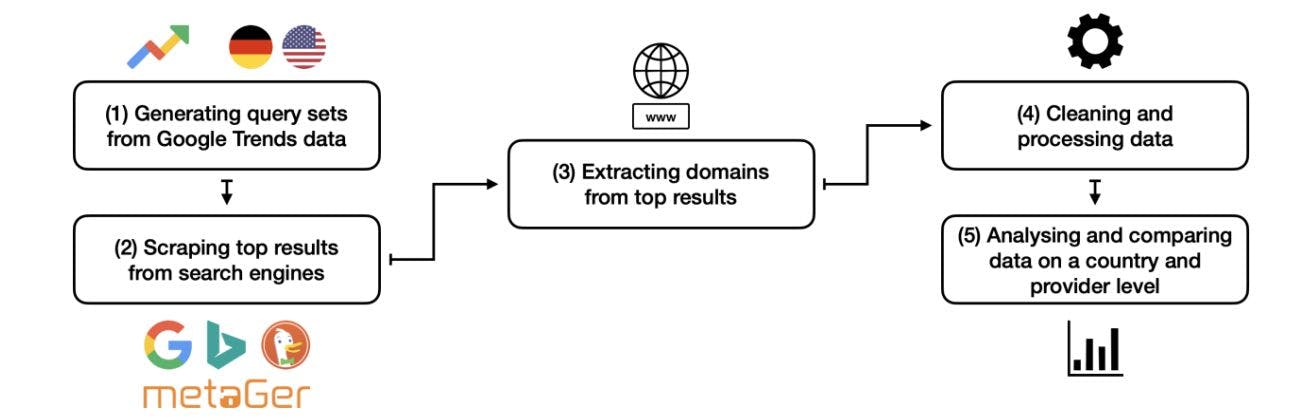
Comparative Analysis of Search Engine Results Using Google Trends Data
by byBrowserology: Study & Science of Internet Browsers@browserology
byBrowserology: Study & Science of Internet Browsers@browserology
100% aware of the way quirks and bugs affect each browser.
May 11th, 2024





100% aware of the way quirks and bugs affect each browser.
Story's Credibility


100% aware of the way quirks and bugs affect each browser.
Story's Credibility
About Author

100% aware of the way quirks and bugs affect each browser.
Comments












