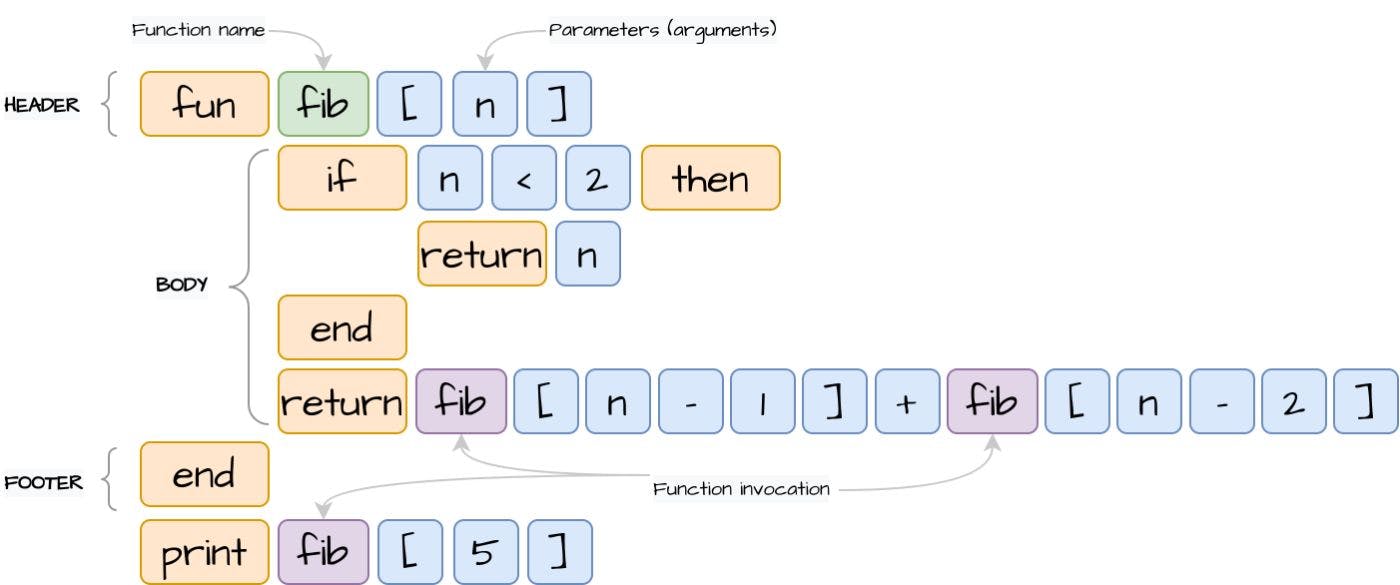
In this part of creating your own programming language, we will introduce new function constructions. Please checkout the previous parts: Building Your Own Programming Language From Scratch Building Your Own Programming Language From Scratch: Part II - Dijkstra's Two-Stack Algorithm Build Your Own Programming Language Part III: Improving Lexical Analysis with Regex Lookaheads The full source code is available over on . GitHub 1. Function Design We will begin embedding function constructions with the lexical analyzer. As you may remember from the previous parts, we store language lexeme types in the enum with corresponding regular expressions. TokenType With the new function statement, we’re missing the and keywords. The first will stand for the beginning of the function declaration, the second will be used to exit the function and pass the resulting value. Therefore, we add these missing keywords as “or” expressions: fun return fun return package org.example.toylanguage.token; ... public enum TokenType { ... Keyword("(if|then|end|print|input|struct|fun|return)(?=\\s|$)"), ... } Then we will map the and keywords inside the syntax analyzer. The purpose of the syntax analyzer is to build statements from tokens generated by the lexical analyzer in the first step. But before diving into parsing function expressions, we will add a couple of auxiliary classes, which are required to store and manage function expressions. fun return 1.1 Function Statement First, we need a class for the function statement. It should extend the existing , which will allow to store inner statements as the early created (if/then): CompositeStatement ConditionStatement package org.example.toylanguage.statement; public class FunctionStatement extends CompositeStatement { } 1.2 Function Definition In order to store function declarations with all metadata information, we need a function definition class. We already have for structures. StructureDefinition Let’s initialize a new one for the functions. It will contain the following fields: function name, function arguments and the itself, which will be used later when we meet the actual function invocation to access inner function statements: FunctionStatement package org.example.toylanguage.definition; @RequiredArgsConstructor @Getter @EqualsAndHashCode(onlyExplicitlyIncluded = true) public class FunctionDefinition implements Definition { @EqualsAndHashCode.Include private final String name; private final List<String> arguments; private final FunctionStatement statement; } 1.3 Function Header Now we have classes to read a function definition and function inner statements, we can start reading the function header. We will extend the existent method to read the new Keyword: StatementParser#parseExpression() fun package org.example.toylanguage; public class StatementParser { ... private Statement parseExpression() { Token token = next(TokenType.Keyword, TokenType.Variable, TokenType.Operator); switch (token.getType()) { ... case Keyword: switch (token.getValue()) { ... case "fun": ... } default: ... } } } After we successfully caught Keyword, we will read the function name: fun ... case "fun": Token type = tokens.next(TokenType.Variable); ... After the function name, we expect to receive the function arguments surrounded by square brackets and divided by comma: ... case "fun": Token type = tokens.next(TokenType.Variable); List<String> args = new ArrayList<>(); if (tokens.peek(TokenType.GroupDivider, "[")) { tokens.next(TokenType.GroupDivider, "["); //skip open square bracket while (!tokens.peek(TokenType.GroupDivider, "]")) { Token arg = tokens.next(TokenType.Variable); args.add(arg.getValue()); if (tokens.peek(TokenType.GroupDivider, ",")) tokens.next(); } tokens.next(TokenType.GroupDivider, "]"); //skip close square bracket } ... In the next step, we initialize the instance and add it to the HashMap, which will be used later by inner to construct function invocations: FunctionDefinition functions ExpressionReader public class StatementParser { ... private final Map<String, FunctionDefinition> functions; ... public StatementParser(List<Token> tokens) { ... this.functions = new HashMap<>(); } ... case "fun": ... FunctionStatement functionStatement = new FunctionStatement(); FunctionDefinition functionDefinition = new FunctionDefinition(type.getValue(), args, functionStatement); functions.put(type.getValue(), functionDefinition); ... } 1.4 Function Body After completing the statement header, we will read the inner statements until we reach the finalizing Keyword the same way we did to read the (if/then). end ConditionStatement To parse an inner statement, we invoke the , which will read nested functions as well. StatementParser#parseExpression() ... case "fun": ... while (!tokens.peek(TokenType.Keyword, "end")) { Statement statement = parseExpression(); functionStatement.addStatement(statement); } tokens.next(TokenType.Keyword, "end"); return null; ... In the end, we return as we don’t want this function statement to be executed in the main program without a direct invocation call. This code definitely needs to be refactored, but for now it’s the easiest way to manage inner invocations. null parseExpression() 2. Return Statement In the previous section, we added the as the to be captured by the lexical analyzer. In this step, we will handle this keyword using the syntax analyzer. return TokenType.Keyword First, we start with a statement implementation, which should contain only an expression to execute and pass as the result of the function invocation: package org.example.toylanguage.statement; @RequiredArgsConstructor @Getter public class ReturnStatement implements Statement { private final Expression expression; @Override public void execute() { Value<?> result = expression.evaluate(); } } To pass the resulting expression of the invoked function, we introduce an auxiliary class with the method, indicating that we have triggered the end of the function: ReturnScope invoke() package org.example.toylanguage.context; @Getter public class ReturnScope { private boolean invoked; private Value<?> result; public void invoke(Value<?> result) { setInvoked(true); setResult(result); } private void setInvoked(boolean invoked) { this.invoked = invoked; } private void setResult(Value<?> result) { this.result = result; } } There is one important note: we can have several nested function invocations with multiple function exits, but one cannot manage all function calls. Therefore, we create an extra class to manage the return context for each of the function invocation: ReturnScope package org.example.toylanguage.context; public class ReturnContext { private static ReturnScope scope = new ReturnScope(); public static ReturnScope getScope() { return scope; } public static void reset() { ReturnContext.scope = new ReturnScope(); } } Now we can go back to the declaration and call method using : ReturnStatement ReturnScope#invoke() ReturnContext package org.example.toylanguage.statement; ... public class ReturnStatement implements Statement { ... @Override public void execute() { Value<?> result = expression.evaluate(); ReturnContext.getScope().invoke(result); } } The is ready and will notify the current about function exit, therefore we can implement logic for the syntax analyzer to map lexeme into : ReturnStatement ReturnScope return ReturnStatement package org.example.toylanguage; public class StatementParser { private Statement parseExpression() { Token token = next(TokenType.Keyword, TokenType.Variable, TokenType.Operator); switch (token.getType()) { ... case Keyword: switch (token.getValue()) { ... case "return": Expression expression = new ExpressionReader().readExpression(); return new ReturnStatement(expression); } default: ... } } } The next step would be to subscribe function execution to the . The function needs to know at which moment we performed the return statement to stop the subsequent execution. We will extend implementation, which will work both for the and for the (if/then), by stopping the execution at the moment we catch the return invocation: ReturnContext ConditionStatement#execute() FunctionStatement ConditionStatement package org.example.toylanguage.statement; ... public class CompositeStatement implements Statement { ... @Override public void execute() { for (Statement statement : statements2Execute) { statement.execute(); //stop the execution in case ReturnStatement has been invoked if (ReturnContext.getScope().isInvoked()) return; } } } 3. Empty Return Our return statement can contain no resulting value, indicating just the end of the function without the provided result. Let’s introduce the new implementation containing “null” value. Value First, we add new lexeme to parse “null” as different lexeme instead of Variable: Null ... public enum TokenType { ... Numeric("[+-]?((?=[.]?[0-9])[0-9]*[.]?[0-9]*)"), Null("(null)(?=,|\\s|$)"), Text("\"([^\"]*)\""), ... } In the next step, we create the implementation for this lexeme. We can initialize a static instance as we will use the same object to refer: Value Null package org.example.toylanguage.expression.value; public class NullValue<T extends Comparable<T>> extends Value<T> { public static final NullValue<?> NULL_INSTANCE = new NullValue<>(null); private NullValue(T value) { super(value); } @Override public T getValue() { //noinspection unchecked return (T) this; } @Override public String toString() { return "null"; } } The last thing would be to map lexeme as by the . If our return statement will contain only statement without “null” value, we will not have any operands for the returned expression. Null NullValue ExpressionReader return Therefore, we should add extra validation at the end of the method by returning in the case operands stack is empty: readExpression() NULL_INSTANCE private class ExpressionReader { ... private Expression readExpression() { while (tokens.peekSameLine(TokenType.Operator, TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Null, TokenType.Text)) { Token token = tokens.next(); switch (token.getType()) { case Operator: ... default: String value = token.getValue(); Expression operand; switch (token.getType()) { case Numeric: ... case Logical: ... case Text: ... case Null: operand = NULL_INSTANCE; break; case Variable: default: ... } ... } } ... if (operands.isEmpty()) { return NULL_INSTANCE; } else { return operands.pop(); } } ... } 4. Memory Scope Before diving into function expressions, first we will need to get familiar with the function scope. Basically, scope is the current context in the code. Scope can be defined locally or globally. Currently, if we define any variable, it will be stored as a global variable in the Map and will be accessible in the global context. StatementParser#variables Inside a function, we can also declare variables, and these variables should be accessible only in the scope of this declared function and should be isolated from each function call. To isolate the memory, we will introduce a new class , which will hold the Map of variables: MemoryScope package org.example.toylanguage.context; public class MemoryScope { private final Map<String, Value<?>> variables; public MemoryScope(MemoryScope parent) { this.variables = new HashMap<>(); } public Value<?> get(String name) { return variables.get(name); } public void set(String name, Value<?> value) { variables.put(name, value); } } Unlike , we shouldn’t reset the memory (variables Map) after we enter a function or any other inner block of code. We still need a way to access global variables. Therefore, we can add a parent instance of the , which will be used to read the global variables declared outside of the function: ReturnScope MemoryScope public class MemoryScope { private final Map<String, Value<?>> variables; private final MemoryScope parent; public MemoryScope(MemoryScope parent) { this.variables = new HashMap<>(); this.parent = parent; } public Value<?> get(String name) { Value<?> value = variables.get(name); if (value == null && parent != null) { return parent.get(name); } return value; } ... } To switch between memory contexts easily, we will introduce the class as we did for the . The will be called when we enter an inner block of code and the will be triggered at the end of this block: MemoryContext ReturnScope newScope() endScope() package org.example.toylanguage.context; public class MemoryContext { private static MemoryScope memory = new MemoryScope(null); public static MemoryScope getMemory() { return memory; } public static void newScope() { MemoryContext.memory = new MemoryScope(memory); } public static void endScope() { MemoryContext.memory = memory.getParent(); } } Now we can refactor variables access for the , and with the new interface: AssignStatement InputStatement VariableExpression MemoryContext package org.example.toylanguage.statement; ... public class AssignStatement implements Statement { private final String name; private final Expression expression; @Override public void execute() { MemoryContext.getMemory().set(name, expression.evaluate()); } } package org.example.toylanguage.statement; ... public class InputStatement implements Statement { private final String name; private final Supplier<String> consoleSupplier; @Override public void execute() { ... MemoryContext.getMemory().set(name, value); } } package org.example.toylanguage.expression; ... public class VariableExpression implements Expression { private final String name; @Override public Value<?> evaluate() { Value<?> value = MemoryContext.getMemory().get(name); ... } public void setValue(Value<?> value) { MemoryContext.getMemory().set(name, value); } } 5. Function Invocation In this section, we will make our syntax analyzer able to read and parse function invocations. First, we will start with the declaration. FunctionExpression This class will contain the field to access the function details and the Map of values, passed as arguments during function invocation: FunctionDefinition Expression package org.example.toylanguage.expression; @RequiredArgsConstructor @Getter public class FunctionExpression implements Expression { private final FunctionDefinition definition; private final List<Expression> values; @Override public Value<?> evaluate() { return null; } } To the function expression, we need to execute function inner statements. To retrieve them, we use the instance from the declared field: evaluate() FunctionStatement FunctionDefinition ... @Override public Value<?> evaluate() { FunctionStatement statement = definition.getStatement(); statement.execute(); return null; } ... But before executing function statements, it’s important to initialize the new . It will allow inner statements to use its own memory. The inner memory shouldn’t be accessible outside this function call, therefore at the end of the execution, we set the memory scope back: MemoryScope ... @Override public Value<?> evaluate() { FunctionStatement statement = definition.getStatement(); MemoryContext.newScope(); //set new memory scope //execute function body try { statement.execute(); } finally { MemoryContext.endScope(); //end function memory scope } return null; } ... We should also initialize function arguments, which can be passed as value lexemes and not be available in the global memory scope. We can save them in the new function’s memory scope by creating and executing the for each of the function values: AssignStatement ... @Override public Value<?> evaluate() { FunctionStatement statement = definition.getStatement(); MemoryContext.newScope(); //set new memory scope //initialize function arguments IntStream.range(0, values.size()) .boxed() .map(i -> new AssignStatement(definition.getArguments().get(i), values.get(i))) .forEach(Statement::execute); //execute function body try { statement.execute(); } finally { MemoryContext.endScope(); //end function memory scope } return null; } ... The last thing left to do is to return the result. We can grab it from the . The result will be captured in the when we invoke the . ReturnContext ReturnScope ReturnStatement Don’t forget to reset the at the end of the function block to make the next function invocation use its own instance: ReturnScope ReturnScope ... @Override public Value<?> evaluate() { FunctionStatement statement = definition.getStatement(); MemoryContext.newScope(); //set new memory scope //initialize function arguments IntStream.range(0, values.size()) .boxed() .map(i -> new AssignStatement(definition.getArguments().get(i), values.get(i))) .forEach(Statement::execute); //execute function body try { statement.execute(); return ReturnContext.getScope().getResult(); } finally { MemoryContext.endScope(); //end function memory scope ReturnContext.reset(); //reset return context } } ... Now we can switch to the class and read an actual function invocation. The pattern of function call looks almost the same as the structure instantiation, except for the fact, we don’t have the keyword in the front of the expression. ExpressionReader New Before creating the , we check that the next lexeme is the opening square bracket, which will indicate the function call: VariableExpression private class ExpressionReader { ... private Expression readExpression() { while (tokens.peekSameLine(TokenType.Operator, TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Null, TokenType.Text)) { Token token = tokens.next(); switch (token.getType()) { case Operator: ... default: String value = token.getValue(); Expression operand; switch (token.getType()) { case Numeric: ... case Logical: ... case Text: ... case Null: ... case Variable: default: if (!operators.isEmpty() && operators.peek() == Operator.StructureInstance) { operand = readStructureInstance(token); } else if (tokens.peekSameLine(TokenType.GroupDivider, "[")) { operand = readFunctionInvocation(token); } else { operand = new VariableExpression(value); } } ... } } ... } } Reading the function invocation will look almost the same as structure instantiation. First, we obtain the function definition by function name. Then, we read function arguments. In the end, we return an instance of : FunctionExpression private FunctionExpression readFunctionInvocation(Token token) { FunctionDefinition definition = functions.get(token.getValue()); List<Expression> arguments = new ArrayList<>(); if (tokens.peekSameLine(TokenType.GroupDivider, "[")) { tokens.next(TokenType.GroupDivider, "["); //skip open square bracket while (!tokens.peekSameLine(TokenType.GroupDivider, "]")) { Expression value = new ExpressionReader().readExpression(); arguments.add(value); if (tokens.peekSameLine(TokenType.GroupDivider, ",")) tokens.next(); } tokens.next(TokenType.GroupDivider, "]"); //skip close square bracket } return new FunctionExpression(definition, arguments); } 6. Testing Time We have finished embedding functions in both lexical and syntax analyzers. Now we should be able to parse function definitions and to read function invocations. Note that function invocation is just like any other expression, including structure instantiation. Therefore, you can build any logical complex nested expressions. Let’s create a more difficult task for the syntax analysis to determine if two binary trees are the same: # # Determine if two binary trees are identical following these rules: # - root nodes have the same value # - left sub trees are identical # - right sub trees are identical # struct TreeNode [ value, left, right ] fun is_same_tree [ node1, node2 ] if node1 == null and node2 == null then return true end if node1 != null and node2 != null then return node1 :: value == node2 :: value and is_same_tree [ node1 :: left, node2 :: left ] and is_same_tree [ node1 :: right, node2 :: right ] end return false end # tree-s example # # tree1 tree2 tree3 tree4 # 3 3 3 3 # / \ / \ / \ / \ # 4 5 4 5 4 5 4 5 # / \ / \ / \ / \ / \ / \ / \ \ # 6 7 8 9 6 7 8 9 6 7 9 8 6 7 9 # tree1 nodes tree1_node9 = new TreeNode [ 9, null, null ] tree1_node8 = new TreeNode [ 8, null ] tree1_node7 = new TreeNode [ 7 ] tree1_node6 = new TreeNode [ 6 ] tree1_node5 = new TreeNode [ 5, tree1_node8, tree1_node9 ] tree1_node4 = new TreeNode [ 4, tree1_node6, tree1_node7 ] tree1 = new TreeNode [ 3, tree1_node4, tree1_node5 ] tree2 = new TreeNode [ 3, new TreeNode [ 4, new TreeNode [ 6 ], new TreeNode [ 7 ] ], new TreeNode [ 5, new TreeNode [ 8 ], new TreeNode [ 9 ] ] ] tree3 = new TreeNode [ 3, new TreeNode [ 4, new TreeNode [ 6 ], new TreeNode [ 7 ] ], new TreeNode [ 5, new TreeNode [ 9 ], new TreeNode [ 8 ] ] ] tree4 = new TreeNode [ 3, new TreeNode [ 4, new TreeNode [ 6 ], new TreeNode [ 7 ] ], new TreeNode [ 5, null, new TreeNode [ 9 ] ] ] print is_same_tree [ tree1, tree2 ] print is_same_tree [ tree1, tree3 ] print is_same_tree [ tree2, tree3 ] print is_same_tree [ tree1, tree4 ] print is_same_tree [ tree2, tree4 ] print is_same_tree [ tree3, tree4 ]