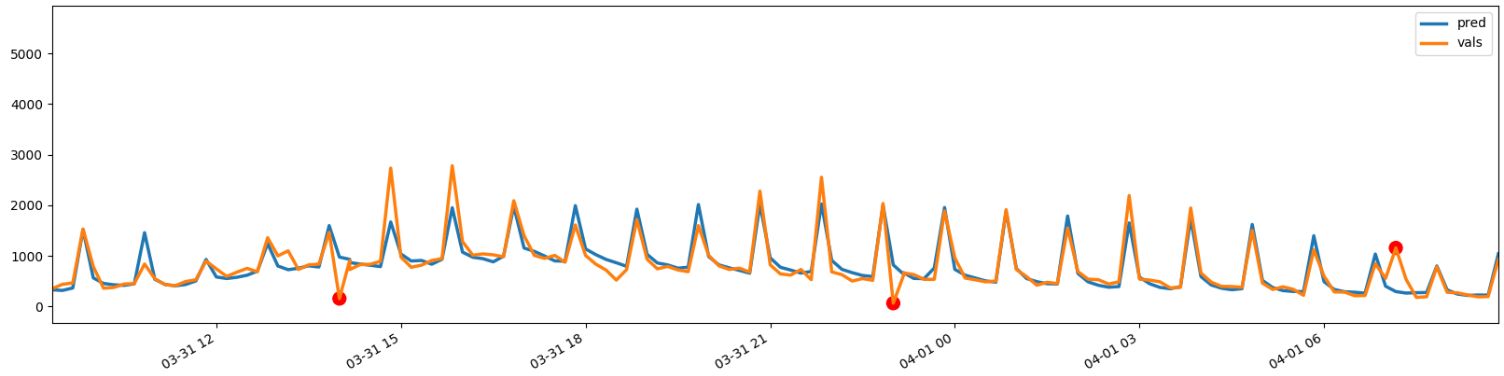
The world of online ad fraud prevention involves finding attacks before they hit ad budgets. This requires continuous streaming of high frequency, high volume data. With say, credit card fraud, banks have limited amounts of requests, say 1 million a day to investigate. However, advertising fraud prevention solutions need to analyze 20,000 requests per second. Therefore, there is a very real necessity to monitor and alert our cybersecurity team and advertisers using our platform on anomalous events as they happen. This might not sound that complicated. But from our experience it is far from simple.In order for these alerts to be taken seriously by our clients they have to be meaningful. Therefore, the ratio of True alerts to False alerts must be as high as possible. Using standard methods like percent change of data points- for instance from minute to minute, don’t take trends into account, so new data streams/volumes added will raise false alerts. Simple statistical methods such as moving average crossover (a technique used for time series analysis in which you calculate the moving average for two-time windows) doesn’t take into account seasonality, either intradaily, weekly or monthly. More complex statistical models such as ARIMA - a statistical analysis model that uses time series data to either better understand the data set or to predict future trends - does account for trends and seasonality. However, these models are usually not accurate when trying to depict intricate relationships between variants (multi-variant) in their prediction. These difficulties led us to build a deep neural network to learn our signals, predict the next values and create an alert when real values observed are outside the model’s margin of error (i.e. anomalous or outlayer).Technically speaking, we built a service in python language and Google’s tensorflow deep learning library. The model is a recurrent neural network with double stacked Long Short Term Memory (LSTM) layers which predict the signals values for the next time step, in our case we used 10 minutes time steps with a data set of our 30 days historical network traffic segmented into online ad fraud types. This model was inspired by Egor Korneev’s excellent medium post.The anomalies, once found, are fed to an explanatory module which by query the database for different fields at and around the anomalous timestamp, sends an alert to the team’s slack channel containing the signal’s chart with the anomaly highlighted, the anomaly details and a link to the Kibana dashboard already filtered on the anomaly’s exceptional values as proposed by the explanatory module. This anomaly detection algorithm and explanation module bring to light hidden fraud patterns inmass amounts of data. The we analyze for clients includes for instance analyzing a group of fraudulent remote servers with similar behavioral patterns, specific data centers/online services/web browsers/ geographical regions trending with fraudulent traffic whether be it on the user side (e.g. bots, DDOS attacks, VPN users etc.) or on the website side (e.g. click hijacking, force refresh etc.). data This is used for instance in our click fraud product, which prevents invalid clicks across all paid search and paid social platforms. For example, we’ve uncovered eight websites, all built in the same free forum's platform, all copying content from different websites, all using the same site template and all operating from the same village outside São Paulo, Brazil. What connects them together is the fact that all of them owe 98% of their traffic to three IPs only, and these three IPs are attributed to three of the other seven sites. At CHEQ, we are combating online ad-fraud, uncovering these patterns gives us both the ability to continuously check our products for unjustified blocking and keep developing new features to keep up with the ever-changing landscape of online ad-fraud. Have no mistakes, this is an arms race, if you’re not running ahead, you’ll fall behind.