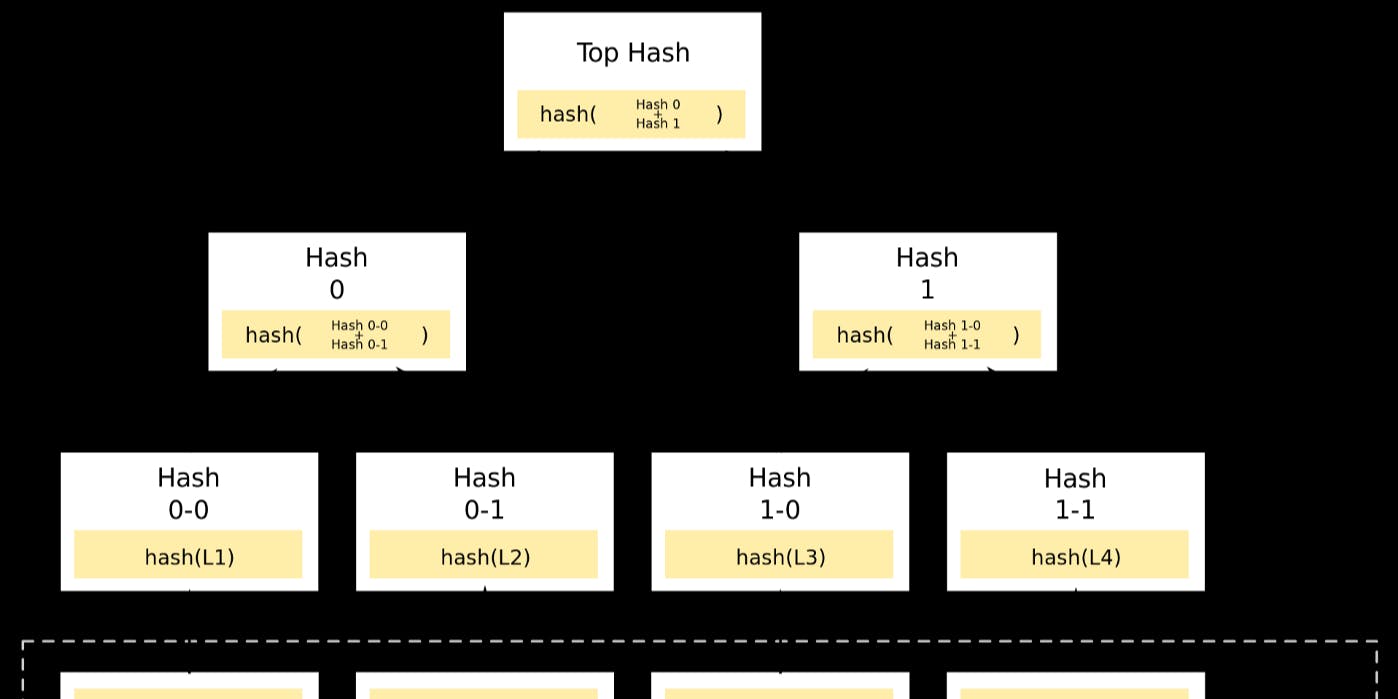
No you can’t find this kind of a tree in the forest. (source: xkcd ) While it might not get you invited to parties, it is important to know what a tree is to jump into the Merkle Tree. In computer science, a tree is a data structure. What it means is; It is composed out of : a fancy way of saying something that contains data and can link to other fellow nodes.It is also composed out of : which is the links we were talking about in the previous point. Duh.It is a type of : if you only have the previous two points and no other limitations imposed on it; you would have a graph. However, since trees are special types of graphs;It starts with a : You must have one node that is the beginning of your tree, where it all began. Your very own patient zero. (Someone remind me to make a zombie joke here please.)Nodes only link by of the parent nodes. As such, you can’t just link your nodes however you want.A node without children is called a or . nodes edges graph root node branching off leaf terminal When you follow these six rules; you end up with something like the following: A tree in the wild. Let’s not spook it. (source: ) wikipedia I can almost hear everyone screaming at their screens and chanting “so what?”. In my opinion it is best to give a relevant example such as an organisation’s hierarchy. You see, even though we defined a computer science term with nodes, leafs and such… it is actually not something we have never seen. Any time we think of a hierarchy, and strictly the hierarchy, we think of a tree. An example of a organisational hierarchy. See how they are the same? (source: me) As it turns out, this type of a data structure that we knew even before computer science, has many different use cases. Particularly speaking it is commonly used for representing hierarchical data, since it has a certain structure storing data for efficient searches and more. A is just a special type of tree. And also another use case for this data structure with additional limitations. You see, in a , which is also known as a , every contains… merkle tree merkle tree hash tree leaf Wait we are going too fast, what is a ? hash When a man and a woman loves each other very much… Sorry that was not the topic we are on. A is basically a signature of any kind of arbitrary data. In a bit more formal way, it is a function that takes an arbitrary size data and returns a fixed size one. hash However, since it is a “signature” of the data it has to be; : This basically means that we want to get the same hash for the same data. Forever. As such, you can’t have anything random here. : If we had a function, that yelled “A” for any input, it would so far work right? Deterministic Uniform However in order to have this as a good, unique signature we want the chance of getting any output (of the fixed size) roughly the same. If this doesn’t happen we have more of what is called a : meaning that we have more and more data with the same signature. collision With large enough “fixed-size” output (signature’s size) and uniformity, this stops being a problem, especially for data that has any meaning : This is the “fixed-size” part that we are talking about. Defined range Since our goal is taking any data and producing a common signature, it has to have a defined range. This is usually talked as the amount of bits, so a very popular hash function SHA-512 for example has 512-bit as its defined range. : We expect these signatures to be a one way street, meaning you shouldn’t be able to get the original content using the hash. Non-invertible While this is not always a requirement, especially for cryptographic hashes, it is definitely very important. (Meaning for example instead of storing your password, facebook could store the “signature” of the password and not get into trouble previously) Since now we have an idea of what a hash is; back to the Merkle Tree. As we were saying, each in this tree has some data block in it. Any other contains the of its children. This turns out to be a very interesting way of storing some data; particularly because it allows you to verify any kind of data. It is also very good in making sure this is a fast process, since we only check for the signatures of the data and nothing else. leaf node cryptographic hash (the one-way signature) A lovely little Merkle Tree. Say hi! (source: ) wikipedia But why? Couldn’t we just check the normal hash of the data instead of putting it into pieces and creating a whole tree? We could. However, if you are developing a distributed / peer-to-peer (where machines are talking to each other and you don’t know whom you can trust) systems, this type of a verification becomes extremely important. Even though the same data is in multiple places, there is no way of knowing if; The node you get the data from is honest.The data you get is correct (and the node before you wasn’t fooled).The data was not corrupted on the road. Ensuring these questions are answered reliably while also making the verifications fast is why we use Merkle Trees. There are many examples of this in the wild, particularly the source control system Git and the pseudo-anonymous cryptocurrency Bitcoin are the most notable ones known. As such, it is also a prerequisite to understanding what a blockchain is. Since this is my first original content, I’d love to hear back from you with any comments, improvements or ideas. Thank you for your time 🎉 Please make sure to to me via the following channels; reach out Twitter Just leave a comment down below Good old fashioned Email Hopefully, this will be a part of a larger series about what blockchain is and how to develop one from scratch in any programming language you want. Stay tuned!