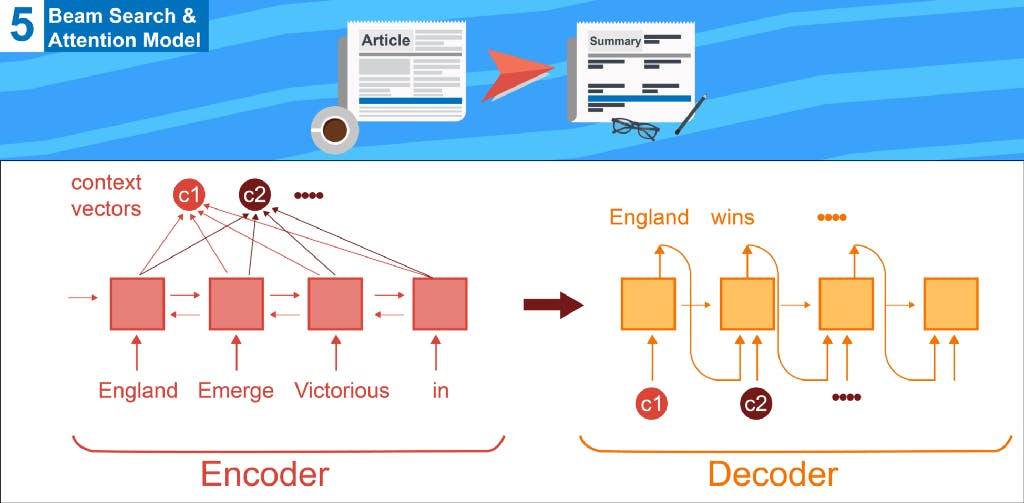
This tutorial is the fifth one from a series of tutorials that would help you build an abstractive text summarizer using tensorflow , today we would discuss some useful modification to the core RNN seq2seq model we have covered in the last tutorial These Modifications are Beam Search Attention Model About Series This is a series of tutorials that would help you build an abstractive text summarizer using tensorflow using multiple approaches , , as is found on , (you can simply copy it to your google drive , learn more ) , and the for this series is written in Jupyter notebooks to run on can be found you don’t need to download the data nor do you need to run the code locally on your device data google drive here code google colab here We have covered so far (code for this series can be found ) here 0. (how to use google colab with google drive) Overview on the free ecosystem for deep learning Overview on the text summarization task and the different techniques for the task Data used and how it could be represented for our task What is seq2seq for text summarization and why Mulitlayer Bidirectional LSTM/GRU so lets get started Quick Recap Our task is of text summarization , we call it abstractive as we teach the neural network to generate words not to merely copy words . the data that would be used would be news and their headers , it can be found on my google drive , so you just copy it to your google drive without the need to download it ( ) more on this We would represent the data using word embeddings , which is simply converting each word to a specific vector , we would create a dictionary for our words ( ) more on this There are for this task , they are built over a corner stone concept , and they keep on developing and building up , they start by working on a type of network called RNN , which is arranged in an Encoder/Decoder architecture called seq2seq ( ), then we would build the seq2seq in a mulitlayer bidirectional structure , where the rnn cell would be a LSTM cell ( ) , the code for these different approaches can be found different approaches more on this more on this here This tutorial has been based by the amazing work of Andrew NG , his course on RNN has been truly useful , i recommend you to see it Today we would go through some modifications made to the core component of the encoder/decoder model , these modifications helps the network choose the best results from a pool of different possibilities , which is known as , also we would talk about , which is a simple network added to our architecture to help it pay more attention to specific words to help it output better summarizes . Beam search Attention Model So lets get started !! 1. Beam Search 1.A Intuition (why beam search) Our task of text summarization can be seen as a conditional language model , meaning that we generate an output given an input sentence , so the output is conditioned on the input sentence , so this is why it is called conditional . This can be seen as a contrary to a simple language model , as a normal language model only outputs the probability of a certain sentence , this can be used to generate novel sentences ,( if its input can be zero) , but in our case , it would select the most likely output given an input sentence. So our architecture is actually divided into 2 parts , an encoder , and a decoder (like discussed ) , as the encoder would represent the input sentence as a vector , and pass it to the next part of the architecture (decoder) here But a problem would arise in the decoder , which sentence to select , as there could be a huge number of outputs for a certain input sentence so how to choose the most likely sentence from this large pool of possible outputs ? Jane is visiting Africa in September Jane is going to be visiting Africa in September In September Jane will visit Africa One solution could be by generating 1 word at a time , generating the first most likely word , then generating the next most word and so … , this is called , but this tends not to be the most optimized approach , due to 2 main reasons greedy search in practice , greedy search doesn’t perform well in each step we must take into consideration all possibilities of all words in the dict , if you have 10k words , then in each step you would have to consider 10k^ 10k (10k to the power 10k) so we would go to a more optimized approximate search approach → Beam Search 1.B How to Beam Search Now that we have understood the basic intuition behind beam search , how to actually implement it ? Simply beam search differs from basic greedy search , these number of options is controlled by a variable called by considering multiple options in every step , not just 1 option Beam Width In greedy search : in each step we only consider the most likely output at each step , but this not always guarantee the best solution as greedy search would output that the best solution is Jane is going , while Jane is visiting is better output this is because the probability of the word “going” after “is” is bigger than the word “visiting” after is , so this is why we need to consider another approach not greedy search , an approach that would take multiple words into consideration So in Beam Search it would be (Beam Width=3) in step 1 , we would choose the 3 most likely words , then for each of the 3 selected words , we would get the most 3 likely words , then the same logic would occur on these 3 output sentences till we build our best output. So if our vocab is 10k , for the each step we tried to look for the most likely word from 10k vocab , so by this we only considered 30k words 1.C Effect of Beam Width when Beam Width = 3 → consider 3 words each step when Beam Width = 1 → consider 1 word each step → greedy search As Beam width increases → better results → but would require more computational resources 2. Attention Model 2.A Attention Intuition When we as humans summarize text , we actually look at couple of words at a time , not the whole text to summarize at a given instance , this is what we are trying to teach our model . We try to teach our model to only pay attention to the neighboring words not the whole text , but what is the function of this attention , we actually don’t know !! , so this is why we would construct a simple neural network for this exact task . 2.B Attention Structure Here we would work on our seq2seq encoder decoder structure ( ) , we would work on a bidirectional encoder ( ) , our work would actually occur on a new interface between the encoder and the decoder , this new interface is called context vector , which actually represent the amount of attention given to words more on this more on this Encoder would be So here to calculate the context C1 that would be the input to the first word in the decoder , we would calculate multiple alpha parameters , so now we would need to know how to get these alpha parameters 2.C Calculate Attention Parameters (context and alpha) Now that we understood the interface between the encoder and the decoder through the context vector which is actually calculated through attention alpha parameters , we would need to know more about how this is calculated lets go through how to calculate the context vector First : don’t forget that we are working on bidirectional encoder , so the activation is actually divided into 2 parts left & right ( ) more on this so the attention would be so the attention have 2 parts , a left and right to form the activation parameter of each cell then the context would be weighted sum of the activations (t stands for number of cells in the encoder ) where the weights are the alpha parameters , this would occur for each context vector We need to know how to calculate the alpha itself Second : Alpha is t stands for the time step in the output , while t’ stands for the time step in input Sum of all alphas is 1 there is a formula that ensures that the sum is 1 then we just need to know what is ‘e’ by intuition we can say that the attention actually depends on the current activation of the input ( alpha<t’>) the (s<t-1>) previous state of the last time step in the decoder but we actually don’t know the real function between them , so for us. , the output from this network would be ‘e’ parameter that would be used to calculate the alpha attention parameter we simply build a simple neural network to learn this relation so the whole scenario would be Next Time if GOD wills it , we would go through how to truly implement a text summarization model , we would go through the steps to implement which uses implements a multilayer bidirectional LSTM with beam search and attention in tensor flow , the code comes from , i have built it into a google colab notebook , and hosted the data to google drive , so that you won’t need to download the data nor would you need to run the code on your computer , you simply run on google colab and connect google colab to your google drive . this model dongjun-Lee I truly hope you have enjoyed reading this tutorial , and i hope i have made these concepts clear , all the code for this series of tutorials are found here , you can simply use google colab to run it , please review the tutorial and tell me what do you think about it , hope to see you again.