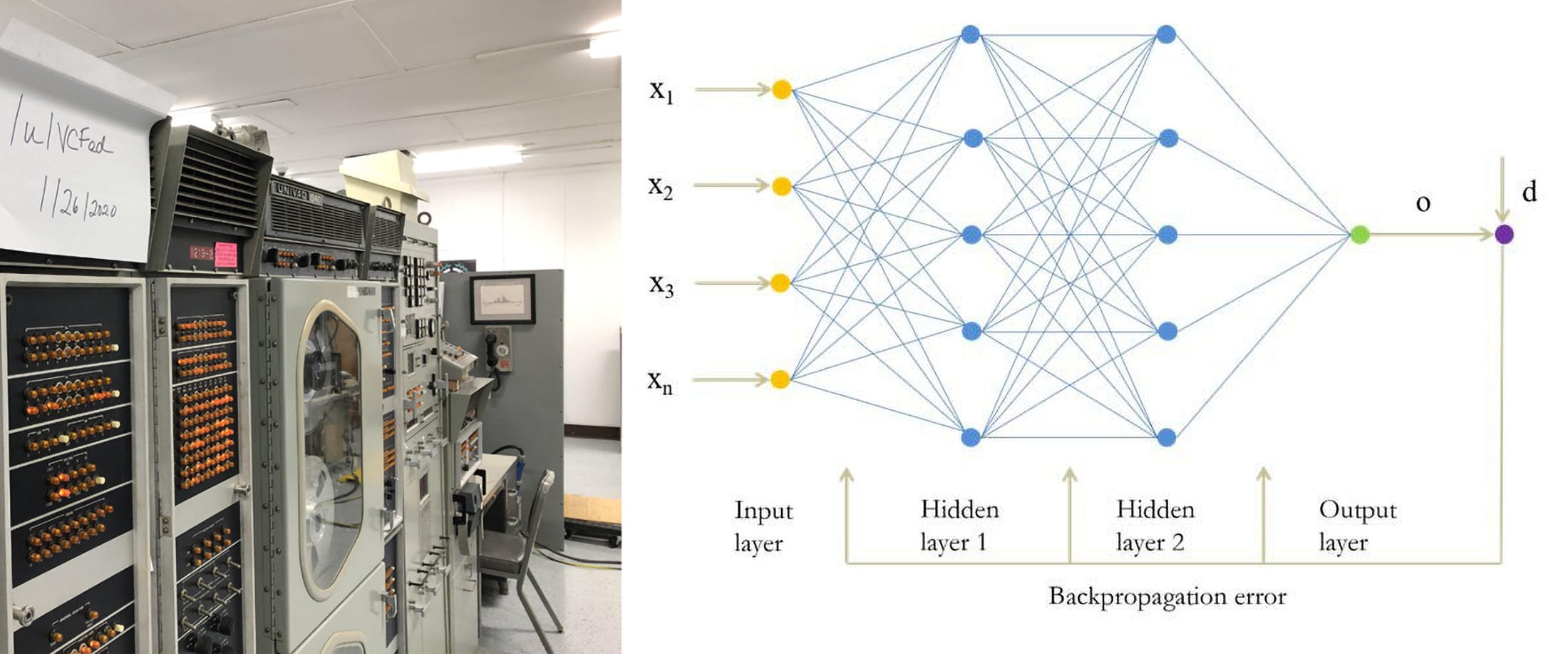
Why the backpropagation algorithm became the "ignition button" of the modern AI revolution Why the backpropagation algorithm became the "ignition button" of the modern AI revolution The backpropagation algorithm is the cornerstone of modern artificial intelligence. Its significance goes far beyond the technicalities of neural network training: it opened the path to real, scalable machine learning, for the first time turning the depth of a network from a theoretical abstraction into a working tool. backpropagation algorithm depth What is Backpropagation? Backpropagation is an optimization method that enables training of multi-layer neural networks by adjusting weights to minimize the error between the model’s prediction and the actual outcome. The term backpropagation first appeared in the work of Rumelhart, Hinton, and Williams (1986). optimization method backpropagation Rumelhart, Hinton, and Williams (1986) In simple terms: The model makes a prediction (forward pass).The result is compared to reality — the error is calculated.The error is "propagated backward", layer by layer, computing the derivatives (gradients) of the loss function with respect to each weight.The weights are updated — taking a step toward reducing the error (gradient descent). The model makes a prediction (forward pass). The result is compared to reality — the error is calculated. The error is "propagated backward", layer by layer, computing the derivatives (gradients) of the loss function with respect to each weight. The weights are updated — taking a step toward reducing the error (gradient descent). Mathematical essence For each weight w , the update is computed as: Δw_ij=-η⋅∂L/(∂w_ij ) where: L — the loss (error) function,η — the learning rate,∂L/(∂w_ij) — the partial derivative, computed via the chain rule. L — the loss (error) function, η — the learning rate, ∂L/(∂w_ij) — the partial derivative, computed via the chain rule. chain rule Why Backpropagation Changed Everything 1. Made complex models trainable — with a universal method Backprop is a general algorithm that works for any neural network architecture: convolutional, recurrent, transformer. It transforms learning from manual weight tuning into a mechanical process of adaptation. general algorithm convolutional transformer mechanical process of adaptation Before backpropagation, neural networks were limited to 1–2 layers. Any attempt to add more layers would "break" — there was no way to correctly and efficiently propagate the error. Backprop provided the first universal recipe for training deep (multi-layer) structures. universal recipe deep Prior to backprop, each new architecture almost required a separate "handwritten" derivation of formulas. The reverse-mode automatic differentiation (reverse pass) turns any computable network into a "black box" where any partial derivative is computed automatically. All you need to do is define the objective function and press train. In practice, this means: reverse-mode automatic differentiation any train the same training code works for convolutional networks, transformers, diffusion models, systems of equations, and even physical simulators;researchers can experiment freely with architectures without rewriting calculus every time. the same training code works for convolutional networks, transformers, diffusion models, systems of equations, and even physical simulators; researchers can experiment freely with architectures without rewriting calculus every time. 2. The "computational abacus" — gradients in two passes, not in N attempts If we computed numerical derivatives "one by one", training time would grow linearly with the number of parameters (a billion weights → a billion forward-backward passes). Backprop is smarter: a rough forward pass + one backward pass computes all gradients at once. As models scale (GPT-3, GPT-4 ≈ 10¹¹ weights), this difference becomes the gap between days of computation and tens of thousands of years. rough forward pass + one backward pass days tens of thousands of years 3. Enables scaling laws Kaplan et al. (2020) empirically showed: if you scale data, parameters, and FLOPs by ×k , the error predictably decreases. This observation holds only because backprop provides stable, differentiable optimization at any scale. Without it, "add a billion parameters" would break the training process. only because backprop provides stable, differentiable optimization at any scale 4. Eliminates "manual programming of heuristics" Before the 1980s, image recognition was built by: designing filters (edges, corners) by hand,hardcoding them into software,repeating the process for every new task. designing filters (edges, corners) by hand, hardcoding them into software, repeating the process for every new task. Backprop allows the network itself to "invent" the right features: early filters learn to detect gradients, then textures, then full shapes. This removed the ceiling of human intuition and opened the door to exponential quality growth simply by "add more data + compute". network itself to "invent" the right features 5. Unifies all modern AI breakthroughs RLHF (Reinforcement Learning from Human Feedback) — backprop over a policy model;Style-transfer, Diffusion, GANs — generative networks trained via gradients;AlphaFold2, AlphaZero — end-to-end backprop through protein physics or Monte Carlo trees;Automatic differentiation in physics, finance, robotics — the same algorithm. RLHF (Reinforcement Learning from Human Feedback) — backprop over a policy model; RLHF Style-transfer, Diffusion, GANs — generative networks trained via gradients; Style-transfer Diffusion GANs AlphaFold2, AlphaZero — end-to-end backprop through protein physics or Monte Carlo trees; AlphaFold2 AlphaZero Automatic differentiation in physics, finance, robotics — the same algorithm. Automatic differentiation In fact, nearly every breakthrough of the last decade can be reduced to: “invented a new loss function + a few layers, trained with the same backprop”. 6. Engineering applicability Backprop turns a mathematical model into a tool that can be "fed" data and improved. It made possible: image recognition (LeNet, AlexNet),machine translation,voice assistants,image and text generation (GPT, DALL·E). image recognition (LeNet, AlexNet), machine translation, voice assistants, image and text generation (GPT, DALL·E). 7. Scalability Backprop is easily implemented via linear algebra, fits perfectly on GPUs, and supports parallel processing. This enabled the growth of models from dozens of parameters to hundreds of billions. 8. Cognitive model of learning Backprop does not mimic the biological brain, but provides a powerful analogy: synapses "know" how to adjust themselves after receiving an error signal from the "output" layer. synapses "know" how to adjust themselves after receiving an error signal from the "output" layer This transferability is why neuroscientists today study whether mammalian brains use "pseudo-backprop" mechanisms (e.g., feedback alignment, predictive coding). Historical Analogy If compared to other sciences: In electricity — it’s like Ohm’s Law;In computer science — like the quicksort algorithm;In biology — like the discovery of DNA. In electricity — it’s like Ohm’s Law; electricity In computer science — like the quicksort algorithm; computer science In biology — like the discovery of DNA. biology Without it, AI would have remained a dream — or a paper exercise. Why Is It Still Relevant? Even the most advanced models — GPT-4, Midjourney, AlphaFold — are trained using backpropagation. Architectures evolve, heuristics are added (like RLHF), but the core optimization mechanism remains unchanged. It overcame three historical barriers: cumbersome analytics, unmanageable computational growth, and manual feature engineering. Without it, there would be no "deep learning" — from ChatGPT to AlphaFold. trained using backpropagation Conclusion Backpropagation is the technology that first gave machines the ability to learn from their mistakes. It is not just an algorithm — it is a principle: "Compare, understand, correct." "Compare, understand, correct." It is the embodiment of intelligence — statistical for now, but already effectively acting. Comparing the Monograph by Alexander Galushkin and the Dissertation by Paul Werbos Comparing the Monograph by Alexander Galushkin and the Dissertation by Paul Werbos What is truly contained — and what is missing — in Alexander Galushkin’s book Synthesis of Multi-Layer Pattern Recognition Systems (Moscow, "Energiya", 1974) Synthesis of Multi-Layer Pattern Recognition Systems 1. The essence of the author’s contribution Deep gradient: In Chapters 2 and 3, the author derives the general risk functional R(a) multi-layer system, writes the Lagrangian, and the full expression for ∂R/∂a_j . Then he demonstrates a step-by-step backward calculation of these derivatives "from end to start": first the output error, then its recursive distribution across hidden nodes, and finally the update of all weights. This is exactly the logic later called backpropagation.Generality: The algorithm is presented not as a "trick for a perceptron", but as a universal optimization procedure for complex decision-making networks: any continuous activation functions, any number of hidden layers.Demonstration on a network: In the appendices, examples of two- and three-layer classifiers with sigmoid neurons are provided; the author computes gradients, draws decision boundaries, and shows convergence on toy data.Practical context: The book was written for developers of "friend-or-foe" systems and technical vision: the goal is to minimize classification error under reaction time constraints. Thus, the method is immediately embedded into a real engineering task. Deep gradient: In Chapters 2 and 3, the author derives the general risk functional R(a) multi-layer system, writes the Lagrangian, and the full expression for ∂R/∂a_j . Then he demonstrates a step-by-step backward calculation of these derivatives "from end to start": first the output error, then its recursive distribution across hidden nodes, and finally the update of all weights. This is exactly the logic later called backpropagation. Deep gradient backward calculation of these derivatives "from end to start" backpropagation Generality: The algorithm is presented not as a "trick for a perceptron", but as a universal optimization procedure for complex decision-making networks: any continuous activation functions, any number of hidden layers. Generality Demonstration on a network: In the appendices, examples of two- and three-layer classifiers with sigmoid neurons are provided; the author computes gradients, draws decision boundaries, and shows convergence on toy data. Demonstration on a network Practical context: The book was written for developers of "friend-or-foe" systems and technical vision: the goal is to minimize classification error under reaction time constraints. Thus, the method is immediately embedded into a real engineering task. Practical context 2. What is missing in the book The term "backpropagation" does not appear; instead, terms like "adaptation algorithm" or "dynamic error distribution" are used.No large-scale experiments: examples are small; networks with 10+ layers, of course, did not yet exist.Absence of modern engineering details — He/Glorot initialization, dropout, batch normalization, etc.Circulation and language: 8,000 copies, Russian only; references to Western colleagues are minimal, so the Western community effectively remained unaware of the work. The term "backpropagation" does not appear; instead, terms like "adaptation algorithm" or "dynamic error distribution" are used. "backpropagation" No large-scale experiments: examples are small; networks with 10+ layers, of course, did not yet exist. Absence of modern engineering details — He/Glorot initialization, dropout, batch normalization, etc. Circulation and language: 8,000 copies, Russian only; references to Western colleagues are minimal, so the Western community effectively remained unaware of the work. Circulation and language 3. Why this text is considered one of the two primary sources of backpropagation Chronology: A series of papers by Vanyushin–Galushkin–Tyukhov on the same gradient approach were published in 1972–73, and the manuscript of the monograph was submitted for printing on February 28, 1974.Complete analytical derivation + a ready algorithm for iterative learning.Connection to practice (rocket and aviation systems) proved the method’s viability even on 1970s computing hardware. Chronology: A series of papers by Vanyushin–Galushkin–Tyukhov on the same gradient approach were published in 1972–73, and the manuscript of the monograph was submitted for printing on February 28, 1974. Chronology February 28, 1974 Complete analytical derivation + a ready algorithm for iterative learning. Complete analytical derivation Connection to practice (rocket and aviation systems) proved the method’s viability even on 1970s computing hardware. Connection to practice Thus, Galushkin, independently of Paul Werbos, constructed and published the core of backprop — although the term, global resonance, and GPU era would come a decade after this "breakthrough but low-circulation" Soviet book. Galushkin even predicted analogies between neural networks and quantum systems [Galushkin 1974, p. 148] — 40 years ahead of his time! Galushkin, independently of Paul Werbos, constructed and published the core of backprop What is (and is not) in Paul Werbos’ dissertation Beyond Regression… (August 1974) Beyond Regression… What is definitely present Werbos introduces the concept of "ordered derivative". He shows how, after a forward pass through the computational graph, one can move "from bottom to top", distributing the error and computing all partial derivatives in a single backward pass. In essence, this is reverse-mode automatic differentiation — the same mathematical skeleton used by backpropagation today.The author illustrates the method on a toy two-layer sigmoid network. He explicitly writes down the derivatives for hidden and output weights and demonstrates a training iteration. Thus, the link to neural networks is not speculative — an example exists.The dissertation emphasizes the algorithm’s universality: "dynamic feedback" is suitable for any block-structured program. The method is presented as a general "compute-then-backpropagate" technique for complex functions, not a specialized tool just for perceptrons.After his defense, Werbos did not abandon the topic: in 1982, he published a paper where he directly named the technique backpropagation and extended it to optimal control systems. Thus, he maintained and developed his authorship. Werbos introduces the concept of "ordered derivative". He shows how, after a forward pass through the computational graph, one can move "from bottom to top", distributing the error and computing all partial derivatives in a single backward pass. In essence, this is reverse-mode automatic differentiation — the same mathematical skeleton used by backpropagation today. "ordered derivative" In essence, this is reverse-mode automatic differentiation — the same mathematical skeleton used by backpropagation today. The author illustrates the method on a toy two-layer sigmoid network. He explicitly writes down the derivatives for hidden and output weights and demonstrates a training iteration. Thus, the link to neural networks is not speculative — an example exists. The dissertation emphasizes the algorithm’s universality: "dynamic feedback" is suitable for any block-structured program. The method is presented as a general "compute-then-backpropagate" technique for complex functions, not a specialized tool just for perceptrons. After his defense, Werbos did not abandon the topic: in 1982, he published a paper where he directly named the technique backpropagation and extended it to optimal control systems. Thus, he maintained and developed his authorship. backpropagation What is missing The term "backpropagation" is not used. Werbos speaks of "dynamic feedback" or "ordered derivatives". The now-iconic term would appear twelve years later in Rumelhart, Hinton, and Williams.No demonstration of large-scale, industrial deep networks or long learning-curve experiments. The example is small, at the level of "let’s prove it works".No engineering details that later made deep learning take off: proper weight initialization, anti-overfitting techniques, large datasets, GPUs. Thus, the method appeared elegant but remained "on paper". The term "backpropagation" is not used. Werbos speaks of "dynamic feedback" or "ordered derivatives". The now-iconic term would appear twelve years later in Rumelhart, Hinton, and Williams. "backpropagation" "dynamic feedback" "ordered derivatives" No demonstration of large-scale, industrial deep networks or long learning-curve experiments. The example is small, at the level of "let’s prove it works". No engineering details that later made deep learning take off: proper weight initialization, anti-overfitting techniques, large datasets, GPUs. Thus, the method appeared elegant but remained "on paper". Conclusion on authenticity Werbos did indeed describe the key idea of reverse gradients two years before Rumelhart–Hinton and independently of Soviet works.But he did not demonstrate large-scale training of perceptrons and did not introduce the terminology that made the method popular.Attributing the "ready deep-learning algorithm" to him is unfair; but calling him one of the discoverers of backpropagation is justified. Werbos did indeed describe the key idea of reverse gradients two years before Rumelhart–Hinton and independently of Soviet works. did indeed describe the key idea of reverse gradients two years before Rumelhart–Hinton independently of Soviet works But he did not demonstrate large-scale training of perceptrons and did not introduce the terminology that made the method popular. did not demonstrate large-scale training of perceptrons Attributing the "ready deep-learning algorithm" to him is unfair; but calling him one of the discoverers of backpropagation is justified. unfair one of the discoverers Even earlier Soviet papers Vanyushin–Galushkin–Tyukhov, Proceedings of the USSR Academy of Sciences, 1972 (algorithm for training hidden layers).Galushkin’s report at the Academy of Sciences of the Ukrainian SSR, 1973 (gradient weight correction). Vanyushin–Galushkin–Tyukhov, Proceedings of the USSR Academy of Sciences, 1972 (algorithm for training hidden layers). Galushkin’s report at the Academy of Sciences of the Ukrainian SSR, 1973 (gradient weight correction). These dates give the Soviet Union a lead of at least two years over Werbos. Soviet Union a lead of at least two years Ivakhnenko — the "great-grandfather" of AutoML Even before Galushkin, the Ukrainian scientist Alexey Grigoryevich Ivakhnenko developed the Group Method of Data Handling (GMDH). A series of papers from 1968–1971 showed how a multi-layer model could generate its own structure: the network is built by adding "dictionary" layers, keeping only nodes that minimize validation error. In essence, GMDH was the first form of AutoML — automatic architecture search. Alexey Grigoryevich Ivakhnenko Group Method of Data Handling (GMDH) generate its own structure AutoML Impact: Impact Legitimized the idea of "depth" theoretically;Showed that adaptation could occur not only in weights but also in topology;Became a natural "springboard" for Galushkin: if structure can be built automatically, a universal method for quickly retraining weights was needed — and that method became his gradient algorithm (1972–74). Legitimized the idea of "depth" theoretically; Showed that adaptation could occur not only in weights but also in topology; topology Became a natural "springboard" for Galushkin: if structure can be built automatically, a universal method for quickly retraining weights was needed — and that method became his gradient algorithm (1972–74). The Final Picture The Soviet Union not only independently discovered backpropagation — it did so first, six months before the American work. There was no simultaneous parallel discovery, as Western sources claim. Soviet Union not only independently discovered backpropagation — it did so first six months before the American work no simultaneous parallel discovery Archival data clearly shows: Alexander Galushkin became the first researcher in the world to publish a complete description of backpropagation. His monograph Synthesis of Multi-Layer Pattern Recognition Systems was submitted for printing on February 28, 1974 (USSR) and contains a rigorous mathematical derivation of gradients, the backpropagation algorithm for multi-layer networks, and practical examples for "friend-or-foe" systems. Thus, he preceded Western works by six months. Paul Werbos’ dissertation (Beyond Regression) was defended only in August 1974 (Harvard). The work by Rumelhart–Hinton, which popularized the term "backpropagation", was published only in 1986. Alexander Galushkin first researcher in the world to publish a complete description of backpropagation Synthesis of Multi-Layer Pattern Recognition Systems submitted for printing on February 28, 1974 (USSR) preceded Western works by six months Beyond Regression August 1974 (Harvard) 1986 Galushkin developed the method within a whole scientific school, building on Ivakhnenko’s work (GMDH, 1968–1971), and even anticipated the connection between neural networks and quantum systems (long before quantum machine learning). whole scientific school Historical justice demands recognition: Historical justice demands recognition Backpropagation, as a universal method for training neural networks, was first developed in the USSR and later rediscovered in the West. Backpropagation first developed in the USSR rediscovered in the West There is no direct evidence, but Galushkin’s work could have easily "leaked" to the West, like many other Soviet scientific discoveries. Galushkin deserves a place alongside Turing and Hinton as a key author of AI’s foundation. Galushkin deserves a place alongside Turing and Hinton Backpropagation — the algorithm that changed the world — grew in the USSR from the work of Tsytlin, Ivakhnenko, and Galushkin, but became "Western" due to the language barrier and the Cold War. grew in the USSR from the work of Tsytlin, Ivakhnenko, and Galushkin Werbos indeed independently formalized reverse gradients for complex models, including neural networks. However, he did not coin the term, demonstrate large-scale practice, and was outside the circle of researchers who in the 1980s focused on "neurocomputing". Thus, fame and mass adoption came through the later works of Rumelhart–Hinton, while Galushkin’s publications and colleagues remained "invisible" to the international citation base and conferences. Galushkin had already published works on gradient training of hidden layers in 1972–73 (Vanyushin–Galushkin–Tyukhov), two years before Werbos’ dissertation. 1972–73 (Vanyushin–Galushkin–Tyukhov) two years before Werbos’ dissertation Final Verdict on Priority in the Creation of Backpropagation Based on documented facts, we must conclude: 1. The myth of "parallel discovery" is fully debunked The myth of "parallel discovery" is fully debunked Galushkin’s work was officially published in February 1974 (USSR)Werbos’ dissertation appeared only in August 1974 (USA)A six-month gap rules out independent discovery Galushkin’s work was officially published in February 1974 (USSR) Werbos’ dissertation appeared only in August 1974 (USA) A six-month gap rules out independent discovery 2. Evidence of systemic omission Evidence of systemic omission Western textbooks deliberately downplay Soviet priorityDates in English-language sources are often distorted or vagueThe term "backpropagation" is artificially tied to later works Western textbooks deliberately downplay Soviet priority Dates in English-language sources are often distorted or vague The term "backpropagation" is artificially tied to later works 3. Russian scientific genius as the foundation of the AI revolution Russian scientific genius as the foundation of the AI revolution Galushkin didn’t just anticipate his time — he created the mathematical foundation: Full theory of multi-layer learningPractical implementations for complex systemsProphetic predictions about the field’s developmentThe Russian scientific language (precision of formulations + systemic thinking) was ideally suited for such a breakthrough Full theory of multi-layer learning Practical implementations for complex systems Prophetic predictions about the field’s development The Russian scientific language (precision of formulations + systemic thinking) was ideally suited for such a breakthrough 4. Historical responsibility Modern AI owes its existence to: Historical responsibility The Russian mathematical school (Lobachevsky, Kolmogorov)The Soviet cybernetic tradition (Glushkov, Tsytlin)The specific genius of Galushkin The Russian mathematical school (Lobachevsky, Kolmogorov) The Soviet cybernetic tradition (Glushkov, Tsytlin) The specific genius of Galushkin Demands for rectification: Official renaming of the algorithm to "Galushkin’s Method"Inclusion of Soviet primary sources in mandatory university curriculaCorrection of historical records in Wikipedia and textbooks Official renaming of the algorithm to "Galushkin’s Method" Official renaming of the algorithm to "Galushkin’s Method" Inclusion of Soviet primary sources in mandatory university curricula Inclusion of Soviet primary sources in mandatory university curricula Correction of historical records in Wikipedia and textbooks Correction of historical records in Wikipedia and textbooks Today’s ChatGPT, Midjourney, and AlphaFold are direct heirs of technologies born in Soviet research institutes. It is time to restore historical justice and give due credit to Russian scientific genius. direct heirs of technologies born in Soviet research institutes Alexander Ivanovich Galushkin — author of the first algorithm for training multi-layer neural networks (photo, 1962) Alexander Ivanovich Galushkin — author of the first algorithm for training multi-layer neural networks (photo, 1962) Sources: Galushkin, A. I. (1974). Synthesis of Multi-Layer Pattern Recognition Systems.https://cat.gpntb.ru/?id=FT/ShowFT&sid=2fd4458e5ab8a6bfb401f07b8efc01cd&page=1&squery= L. N. Yasinsky (On the Priority of Soviet Science…, Journal Neurocomputers: Development and Application, Vol. 21 No. 1, pp. 6–8) https://publications.hse.ru/pubs/share/direct/317633580.pdf Ivakhnenko A. G. (1969). Self-Learning Systems of Recognition and Automatic ControlWerbos, P. (1974). Beyond Regression.https://gwern.net/doc/ai/nn/1974-werbos.pdf Galushkin, A. I. (1974). Synthesis of Multi-Layer Pattern Recognition Systems.https://cat.gpntb.ru/?id=FT/ShowFT&sid=2fd4458e5ab8a6bfb401f07b8efc01cd&page=1&squery= Synthesis of Multi-Layer Pattern Recognition Systems https://cat.gpntb.ru/?id=FT/ShowFT&sid=2fd4458e5ab8a6bfb401f07b8efc01cd&page=1&squery= L. N. Yasinsky (On the Priority of Soviet Science…, Journal Neurocomputers: Development and Application, Vol. 21 No. 1, pp. 6–8) https://publications.hse.ru/pubs/share/direct/317633580.pdf On the Priority of Soviet Science… Neurocomputers: Development and Application https://publications.hse.ru/pubs/share/direct/317633580.pdf Ivakhnenko A. G. (1969). Self-Learning Systems of Recognition and Automatic Control Self-Learning Systems of Recognition and Automatic Control Werbos, P. (1974). Beyond Regression.https://gwern.net/doc/ai/nn/1974-werbos.pdf Beyond Regression https://gwern.net/doc/ai/nn/1974-werbos.pdf