
590 reads
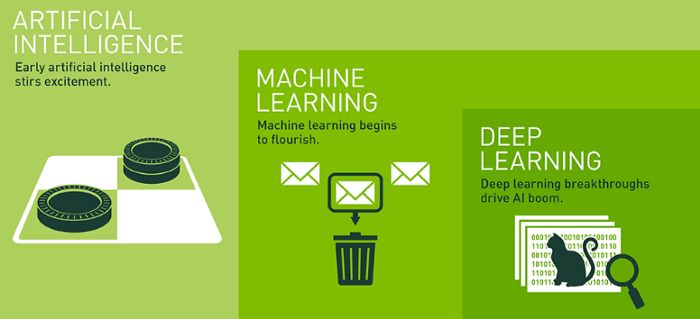
Artificial Intelligence, Machine Learning and Deep Learning Basics
by byJack Ryan@jack-ryan
byJack Ryan@jack-ryan
I am Jack Ryan, the Marketer & Coder. We share some stories about free smtp servers and programming.
August 26th, 2020





I am Jack Ryan, the Marketer & Coder. We share some stories about free smtp servers and programming.


I am Jack Ryan, the Marketer & Coder. We share some stories about free smtp servers and programming.
About Author

I am Jack Ryan, the Marketer & Coder. We share some stories about free smtp servers and programming.
Comments













