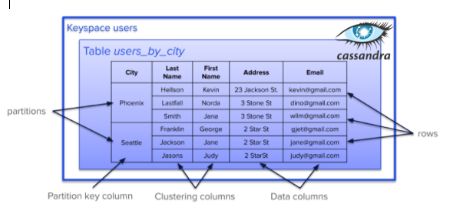
Data modeling is probably one of the most important and potentially challenging aspects of Cassandra. CQL will look familiar if you come from a relational background, but the way you use it can be very different. For our third guide, we will walk you through the process of creating a basic data model. Read part one on Cassandra essentials and part two on bootstrapping. Keyspace Structure The first thing to learn about data modeling in Apache Cassandra is keyspaces. A is very similar to a database or schema from the relational database world, as it holds all of your tables. A keyspace also has another function; it allows you to set the replication strategy and factor for the tables it contains (we will get into that more later). Each table is organized into rows and columns. keyspace Groups of related rows -- called partitions -- are stored together on the same node(s). Logically, if you were to perform a SELECT query against a Cassandra table, it would feel pretty much the same as it does when using a relational database: you will see rows and columns in a tabular format. The difference with Cassandra is that each row has a : one or more columns that are hashed to determine which node(s) store that data. partition key Our data is “partitioned”, or subdivided, based on our partition key, which is assigned when we create our table. When we insert data, Cassandra looks at the partition key to determine where this data should go. The value of that partition key is run through a consistent hashing function and, depending on the output, we can figure out which bucket, or which range of hashes, that value fits into along the token range -- and thus, which node(s) in the cluster this data belongs on. Example users Keyspace Supposing we have a keyspace, containing a table . This table name suggests that the user data for this table will be distributed among nodes (or partitioned) by city. In this case, will be the partition key. users users_by_city city A user’s will determine where their data is stored, and users from the same city will have their data stored at the same location. Notice that we have two partitions: Phoenix and Seattle. Those partitions contain all of my rows. city In this example, represents the partition key column. But there is also the concept of as well. Clustering columns denote order, and they also contribute to the distinctiveness of the primary key, used to uniquely identify a row in a table. Cassandra finds out the specific node (and it's replicas) responsible for that specific partition, clustering columns help in further narrowing your query search. city clustering columns Clustering columns are composed of row data in sorted order. We have two clustering columns in this example, and . Since and contain text fields, they will be naturally ordered automatically in Cassandra (if denoted a clustering column). Last Name First Name Last Name First Name Therefore, with a given partition, column values have been written to the table in ascending order (A-Z). This makes it efficient for storing and retrieving data using a clustering key. Because the is also a clustering column following , if there were multiple people with the last name “Hellson” for example, the first name would be ordered (A-Z), per the last name. Anything that is not a partition key or clustering column is just a basic data column. Last Name First Name Last Name In a relational database, even if you have indexes, you’ll end up paying for ordering on the read. Alternatively, with Cassandra, we end up paying for it on the write, as we are pre-baking the ordering of the data as it is written to the table. Therefore, when the data is written to memory and eventually flushed to disk, it is already in its ordered format. This increases the speed of data retrieval; we are optimizing for read operations. Creating a Schema in CQL Let’s take a closer look at the CQL syntax involved in creating a keyspace and table. Here we have the CQL command used to create the keyspace, including the replication strategy and the replication factor. The replication strategy tells Cassandra how to distribute the replicated data across the database machines, while the replication factor tells Cassandra how many copies of the data to create. users If you have completed the previous exercises from these articles, you are probably already familiar with CQL syntax, and the concept of replication factor. Creating tables with Cassandra is very similar to how it is done in the relational world. The big difference is that in Cassandra, we have what is called a partition key, which is always the first value of your primary key, and it is the very base unit of access when querying the database. Since it determines your data locality, it is a requirement to set one when creating your table. The values that follow the partition key within the primary key definition are the clustering columns, which we discussed earlier. So we are partitioning by , and then ordering by , and then . city last_name first_name Start with Application Workflows We've gone through the basic structure of things like keyspaces, tables, and partitions, all of which are fundamental concepts with regard to Cassandra data modeling. If you come from a relational database background, this next part is going to feel quite a bit different from what you are used to. Let’s discuss data modeling in the relational world for just a moment. Basically we start with a set of data, apply normal forms, and come up with a data model that is optimized to reduce the amount of data redundancy. As an application developer, . When we want to ask questions of our database, we’ll probably need to go look at the ERD, join some tables, and then develop our query. we develop our queries based on the table structures that have been given to us In Cassandra, the process is completely reversed. A developer with the application workflows to then develop pseudo-queries that will actually be used to generate your data model. Put another way, . This might seem like it could be a lot of work upfront, . starts you need to know your queries in advance it really just involves a shift in your thinking Once you’ve started to napkin out the UX of an app, you have already started to define your application workflows, and therefore the queries that you’re going to need to create your data model. So the very first thing we will be considering before we start data modeling is our . application workflows Unlike relational databases, Cassandra uses a denormalized data model. When using a relational database a lot of operations have to happen when you're joining tables. While that works wonderfully for a general purpose database, you may also have experienced running queries that have brought such a database down. Because of all those extra operations (Cartesian joins, all that extra IO), the database ends up performing terribly. Cassandra optimizes for read performance at scale, and that is why we use a denormalized data model. Breakdown of the Cassandra Data Modeling Process Now that you have a high-level understanding of how this process works, we are going to have a look at more of the details of data modeling with Cassandra. First, we’ll start with the conceptual data model; our entities and relationships. The process of conceptual data modeling is actually the same for both Cassandra and relational databases. The difference comes in when we bring in our application workflow to generate our queries (Remember, that is what we look at first). From there, we will generate all the way down to our physical data model and create the tables that we need. The entity-relationship diagram (ERD) below may look familiar to you. The particular relationship we're looking at comes from one of the reference that we built, KillrVideo, which is similar to YouTube. It manages videos, users, comments and so on. The diagram shows the relationship between these pieces. applications This example explores the relationships between the data points. For instance, I can look at my profile and see all the comments I've made on all the videos that I have in the system. As such, what we want to do is tease out this relationship between , as well as , in our application workflow. To start, we would find comments that are from a particular user, and for a particular video. users and comments videos and comments Every application has a workflow: what do users see when they first come to the application? Where can the users go from there? What else can they do as they dive further into the application? refer to the specific queries that must we run to satisfy what the user is doing with our application. When a user moves from one part of an application to another part of the application, what query must we run to retrieve the data that the user is interested in seeing? Access patterns Access Pattern Examples: I’ve navigated to a video, I want to see those comments for a particular video. Since they are comments, they are also time-based, so I also want to order such that I get the most recent first. Request 1: Find comments related to target video using its identifier, also: Ensure the most the recent comment for that video is first when results are returned Implement paging such that only x number of comments are returned at once As a user, I want to long into the system, and I want to see all of my comments. I also want to see those based on time, so I get the most recent first. Request 2: Find comments related to target user using its identifier, also: Ensure the most the most recent comment from that user is first when results are returned Implement paging such that only x number of comments are returned at once Users will perform normal CRUD operations, which is something we do with all databases. They will create new accounts, update passwords, delete comments, and select videos to view. Request 3: Implement CRUD operations (Create, Read, Update, Delete) Now that we know the requests we will generate a pseudo-query for each: Let’s develop a pseudo-query for our first request. We want to find the comments for a video with some known id ( ) . Supposing you are navigating through your app, and you’ve come to a particular video of your choosing. This video has an associated identifier ( ). You are interested in viewing the comments for that particular video. This means that we should have a table (comments partitioned by video), hence comments will be queryable on the basis of the videoid associated with that particular video. Query 1: videoid videoid comments_by_videos For our second pseudo-query, we want to find the comments posted by a user with a known id ( ). If you have already logged into the app, your user account already has an associated identifier ( ). You just want to see the comments associated with your user account ( ), because you want to know what sort of comments you’ve been making on videos. Therefore, we know we would want a table (comments partitioned by user). Query 2: userid userid userid comments_by_user For both of these queries, we are going to want to get the most recent comments first. This implies that there is a somewhere in the mix. We will talk about that soon. clustering column is when we take our pseudo-queries and generate tables that would satisfy these queries. This helps us start to get a feel of what our final tables will look like. So now we have a and table, but what do these need to look like to support the queries we came up with in the mapping section? What we are looking at here is a , the Cassandra community uses these for logical data modeling. To make use of these diagrams, you need to understand the notation: Logical data modeling comments_by_user comments_by_video Chebotko diagram K - partition key C ↓ - Clustering column (descending order) C ↑ - Clustering column (ascending order) Partition keys and clustering columns are critical to get correct if we want to satisfy our queries. Let’s have a look at the columns in the table. The is the partition key here, as this table is partitioned by “user”. When we query the table, we will provide the user ( ) for which we want the comments of. Then we have the columns which pertain to the comment information itself; (in descending order, so we get the most recent on top), , (provides a link back to the video the comment is on, recall this was one of the relationships we wanted to tease out of our data points), and then the itself. comments_by_users userid userid creationdate commentid videoid comment The table has a very similar situation. The only difference of course is instead of partitioning by user, we are going to partition by video, hence is the partition key. comments_by_video videoid Notice that both tables have a lot of the same columns. We are indeed going to be repeating the same data in different tables. This is what we mean when we say Cassandra data is denormalized, for read-on-read performance, by adding redundant copies of the same data. Cassandra makes a trade-off to use more disk (which is quite cheap, nowadays) to be able to maintain the benefit of performance at scale. Now we move on from a logical data model to a model. This is when we add the data types and consider any optimizations we can make to our data model. For example, in Cassandra there is a data type called a . This is essentially a combination of a and a . So your initial inclination might be to use a for and a UUID for . physical data TIMEUUID Timestamp UUID Timestamp creationdate commentid But why not remove the column, and get the date/time associated with the creation of a comment by using a for the column. Notice how it only took a couple of steps to get from our pseudo-queries to the actual tables we were looking for. creationdate TIMEUUID commentid We can now go ahead and execute the CQL that will create these tables in our database. This is going to look very familiar if you’ve ever done this in SQL. Take note of the primary key here in the table, We are partitioning by , and ordering within that partition by ( ). This is why we set as a clustering column. The same goes for the tables. You’ve arrived, meet your data model. comments_by_users userid commitid TIMEUUID commentid comments_by_video Querying these tables is very simple. If you want to perform a basic SELECT query against the table, all you need is the partition key, . To SELECT from the table, all you need is a , the partition key for that table. Using the partition key allows us to go to the exact location of that data, which optimizes for read performance and allows queries to be fairly simple. With Cassandra, you will generally have one query per table. comments_by_user userid comments_by_videos videoid Exercise 4 - Data Modeling Our explained CQL and included an exercise. Similarly here, get the notebook in this folder and upload into a running instance of DataStax Studio and follow the instructions in the notebook. It will take you through how tables and queries in Cassandra differ from those of a relational database and enable you to start data modeling with Cassandra on your own. previous guide 4_-_Data_Modelling.tar notebooks Now you know the basics of how data modeling works in Cassandra, and the exercise walked you through the process of creating your own data model. In the next guide, we’ll explore some useful advanced data types in Cassandra, such as collections, counters, and user-defined types.