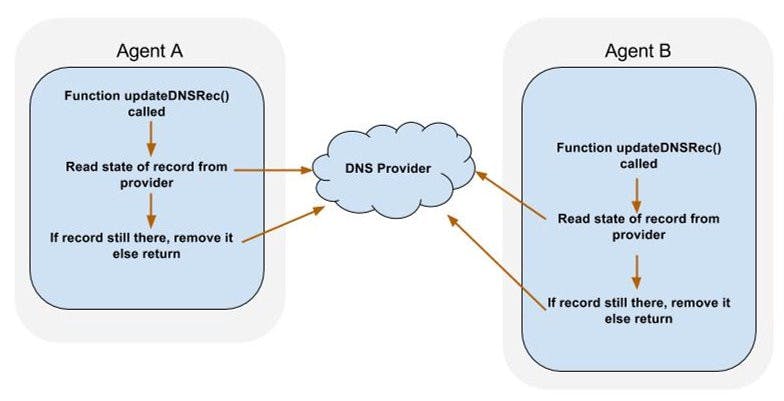
I’d previously for writing a decentralized IP/ endpoint monitoring and DNS failover agent which I called Goavail. The long and short of it is the project is a cluster of lightweight monitoring agents which can be deployed to remote and disparate locations in order to either perform IP or, more recently added, TCP monitoring of specific endpoints (such as an AWS EIP). This came in handy when we decided we should have some layered availability monitoring and failover in place should something go wrong with one of our ingress procxies, an AWS zone go down or become partitioned. The service always performed well in failure testing, but fortunately, we never needed it in an unplanned Production failure situation. written about motivations TCP Despite a successful project, there were still a couple spots in the implementation that bothered me, mostly during the actual failure detection and failover triggering. To understand why, we need to drill into some of the mechanics. An agent consists of the actual endpoint health checks as well as a background HTTP service for communicating failure detections to the rest of the cluster. Should an endpoint become unavailable, an agent will count the number of consecutive failures until some pre-configured threshold. At this point, the agent will notify its cluster peers that it believes the endpoint has failed. It will also check if it has received some pre-configured number of peer notifications itself. Once an agent has received enough agreements from its peers, it will trigger a DNS failover by calling the DNS Service Provider’s REST API (by the same approach, agents can also bring an endpoint back online by detecting a state change from Failed to Live). There are a few points in the code which can trigger the DNS failover, however, the actual DNS Service Provider and failover logic is behind an interface in its own package. package dns //Provider interface for DNS service provider interface type Provider interface {AddIP(ipAddress string, dryRun bool) errorRemoveIP(ipAddress string, dryRun bool) errorGetAddrs() []string} From within the interface-calling package only one function (named “updateDNSRec”) calls the interface methods, essentially acting as an entry-point for the entire package. package checks // bunch of stuff func updateDNSRec(ipAddress string, dryRun bool, op int) error {var err error if op == ADD {err = Master.DNS.AddIP(ipAddress, dryRun)} else if op == REMOVE {err = Master.DNS.RemoveIP(ipAddress, dryRun)} return err} Within the Goavail project’s DNS package a pattern is used to update the A record. For example, here is the test and set sequence for removing an A record from a Cloudflare domain in the Goavail DNSpackage. test-and-set dnsRec, err := api.DNSRecords(zoneID, *params)if err != nil {return err} log.Infoln(dnsRec) if len(dnsRec) == 0 {log.Infoln("DNS Record already removed")return nil}if dryRun {log.Infoln("Dry Run is True. Would have updated DNS for address " + ipAddress)} else {err = api.DeleteDNSRecord(zoneID, dnsRec[0].ID)if err != nil {return err}} So in a failure scenario we have a bunch of distributed processes which will likely be running this section of the code at close to the same time. This isn’t incorrect necessarily, since the DNS Service Provider (Cloudflare in the above example) will be processing these API requests serially. And nothing terrible happens if an agent tries to remove a record that was already removed. Still, it does leave a bad taste. To understand why, note the DNS Service Provider is essentially acting as the “shared data” between all the running processes in this scenario. Of course, if this were happening within the same address space or on the same machine it would be the definition of a race condition. Thinking of it this way, the test-and-set code above would represent the critical section. Again, not necessarily incorrect since the the DNS Service Provider will process the requests sequentially. But it still leaves a lot to be desired since multiple processes are trying to update data (namely, the DNS record) at the same time and some of the Goavail agent processes will certainly return, and log, errors. Despite these implementation drawbacks I still wanted multiple processes verifying the A record is in its proper state. If something goes wrong with the first process attempting to update the monitored domain, there will be others to retry, if necessary. In this way I can be fairly certain the failover has occurred. Ideally then, the agents would all enter the critical section (the test-and-set portion of the code) serially. If the first fails to update the record due to some additional error or failure, the next process will be along to test if the record is in the correct state (i.e. present or removed) and take appropriate action. Once the update is successful by one of the agents, the rest of the agents will simply test, verify the record is in the correct state, and return. But how to enforce the critical section across distributed processes? Distributed Mutual Exclusion With the problem framed this way, it wasn’t long before I came across the Distributed Mutual Exclusion class of algorithms. Regular mutual exclusion can already get hairy pretty quickly; distributed would surely be a wild ride. mutexes Distributed locks relying on some complimentary datastore (for example, , ) are a popular solution. These don’t fit my scenario, however, since in my use case the agents are meant to be lightweight as well as widely distributed. That is, potentially over a WAN, on an untrusted network, and covering some distance which would make reading and writing back to some data-store more complex (more latency variance). For these reasons I preferred a self-contained implementation over something relying on a central data-store. redis etcd For a good survey on standalone distributed mutual exclusion algorithms, including the one I chose to implement, this is a fantastic resource. I eventually settled on the mainly due to the efficiency and scalability properties of quorum based algorithms. document Agarwal-El Abbadi Quorum-Based Algorithm Sample Tree of 15 Nodes The algorithm begins by logically organizing all nodes in the system into a binary tree. A tree quorum is considered to be a path from root to leaf. So [8, 4, 2, 1] and [8, 4, 6, 8] are two of the tree quorums in the above example cluster. Framed this way we can see how lock requests are more efficient than a naive broadcast approach. In the best case, a leaf node such as 3 requests the lock and only needs to send messages to its tree quorum of 2, 4 and 8. Moving up a level, node 2 only needs to request locks from nodes 1, 3, 4, and 8. The message complexity grows as we move up each level of the tree. In the case of node failures, the algorithm runs in a degraded state; it substitutes for the failed node two possible paths starting from the node’s two children and ending in leaf nodes. So for the cluster above, if node 12 fails, it is replaced in its tree quorums ([8, 12, 10, 9], [8, 12, 10, 11], [8, 12, 14, 13], [8, 12, 13, 15]) by two possible paths starting from children 10 and 14 and ending at leaf nodes. When node 12 fails, the following updated tree quorums can be formed: [8, 14, 13, 10, 9], [8, 14, 13, 10, 11], [8, 10, 9, 14, 13], and [8, 10, 9, 13, 15]. So the steps in the lock process are as follows: The requesting node broadcasts a lock Request message to all peers in its tree quorums Each node in the quorum stores incoming requests in a Request queue, ordered by the Request timestamps A node sends a Reply message, indicating its consent to the lock, only to the Request at the head of its request queue (the Request at the head of the queue being the one with the lowest timestamp) The requesting node collects all Reply responses within a certain time-out window Reply responses from all peers in the local node’s quorums are expected and required for the lock to be granted If messages to some of the nodes in the quorum failed, the requesting node calculates replacement paths in the tree and derives substitute nodes based on the algorithm. It then sends the lock Request to the substitute nodes To release the lock, the requesting node sends a Relinquish message to all nodes in its tree quorums. On the receipt of the Relinquish message, each node removes the lock request from the head of its request queue. The algorithm doesn’t specify a timeout or what to do in the case the node holding the lock fails (or the process pauses too long for any number of reason). For this reason the algorithm is supplemented with a Validate message type. Now every time a node’s Request queue is processed the node holding the lock at the head of the queue is sent a Validate message. If this message fails, the node is considered failed. The Request is removed from the head of the queue and the next Request in line is sent a lock Reply message. Alternatively, if the returned Validate message indicates the node no longer holds the lock, it is removed from the head of the queue and the next Request in line is sent a lock Reply. In this way, timeouts only exist for gathering Replies to lock Requests, and not for holding the lock. Messages may arrive out of order or time may not be perfectly synced between the distributed nodes. The algorithm handles such conditions as follows: If a node receives a Request message out of order (according to timestamps of the message at the head of the queue and the new Request message) an Inquire message is sent to the head of the queue. When a node receives an Inquire message it blocks on the Inquire if it has already been fully granted the lock. If its lock request has not been fully granted it returns a Yield message. When the node which sent the Inquire message receives a Yield, it puts the pending request (on behalf of which the Inquire message was sent) at the head of the queue and sends a Reply message to the “rightful” requester. Otherwise the node sending the Inquire message is blocked until the already acquired lock has been Relinquished If the lock was not granted within the timeout window the node Relinquishes any lock Replies it has accumulated The paper outlines correctness and message costs for the tree quorum algorithm, but, in my opinion, glosses over a couple caveats: 1) it mentions the size of the tree quorums varying from (leaf nodes) up to . However, while the root’s children will see a message complexity of , the root will actually see a complexity of n since it is a member of all tree quorums. This can practically be addressed by deploying the nodes such that the root only exists to provide consensus (i.e. not actually requesting locks). Perhaps there is a way to address this in the implementation too, but this could be addressed in the client code and/or deployment. 2) The other caveat is quickly mentioned but is a pretty big drawback. If a leaf node fails, there is no possible substitution since, by definition, there are no children. Therefore, the entire tree quorum containing the failed leaf will be in a failed state. (for example, if node 11 fails, nodes 8, 12 and 10 will not be successful in obtaining the lock). log n (n+1)/2 (n+1)/2 Ideally, the cluster should be more resilient than that. To address the second issue and more, the algorithm is also supplemented with the following logic; if substitutes are not possible (according to the algorithm): Fallback to the naive approach and broadcast the lock Request to all remaining nodes in the cluster If quorum is met (at least responded with the Reply message) then the lock is considered granted. Requiring at least Replies forces responses from the other side of the tree so we can be sure no two nodes will be in the critical section at once. (n+1)/2 (n+1)/2 Revisiting Goavail Monitoring Agents With the at my disposal I can now enforce the critical section which irked me in Goavail. Since I already had a single entrypoint into the DNS Service Provider interface, the place to enforce the mutual exclusion (with as little complexity as possible) was obvious: power of an efficient, lightweight, fault tolerant distributed mutex func updateDNSRec(ipAddress string, dryRun bool, op int) error {var err error if Gm.Clustered {log.Debugln("Acquiring distributed lock") } if err = Gm.Dmutex.Lock(); err != nil {return errors.New("Error acquiring distributed lock: " + err.Error())} else {log.Debugln("Acquired distributed lock: ", time.Now())} if op == ADD {err = Master.DNS.AddIP(ipAddress, dryRun)} else if op == REMOVE {err = Master.DNS.RemoveIP(ipAddress, dryRun)} if Gm.Clustered {log.Debugln("Releasing distributed lock")// if we get to this point don't return an error// unless the actual DNS update call above throws an error.// But still log the Unlock() error }return err} if errUnlock := Gm.Dmutex.UnLock(); errUnlock != nil {log.Errorln(errUnlock)} else {log.Debugln("Released distributed lock: ", time.Now())} Now a Goavail agent will need to acquire the distributed lock before it can perform the test-and-set on the DNS record. The updated code for the Goavail DNS Failover agent is and the Distributed Mutual Exclusion package . here is here : I updated the distributed mutual exclusion package to be a more pure implementation of the Agarwal-El Abbadi Tree Quorum Algorithm along with the supplements. This article has also been updated with more detail around the implementation of the algorithm. Update