860 reads
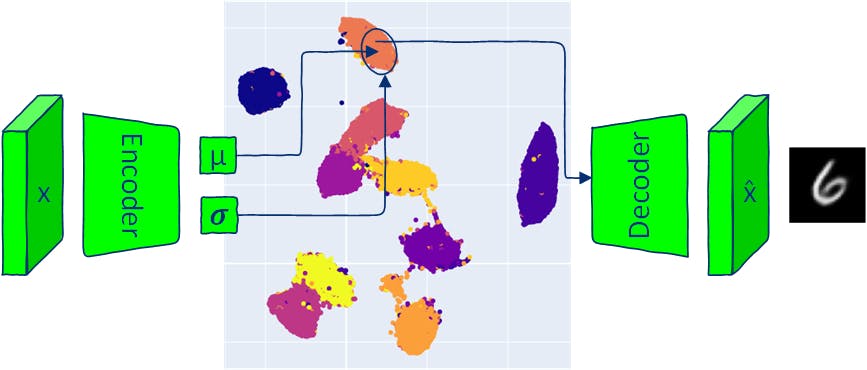
An Introduction to Variational Autoencoders Using Keras
by byAssemblyAI@assemblyai
byAssemblyAI@assemblyai
AssemblyAI builds advanced speech language models that power next-generation voice AI applications.
April 5th, 2022






AssemblyAI builds advanced speech language models that power next-generation voice AI applications.


AssemblyAI builds advanced speech language models that power next-generation voice AI applications.
About Author

AssemblyAI builds advanced speech language models that power next-generation voice AI applications.
Comments