
833 reads
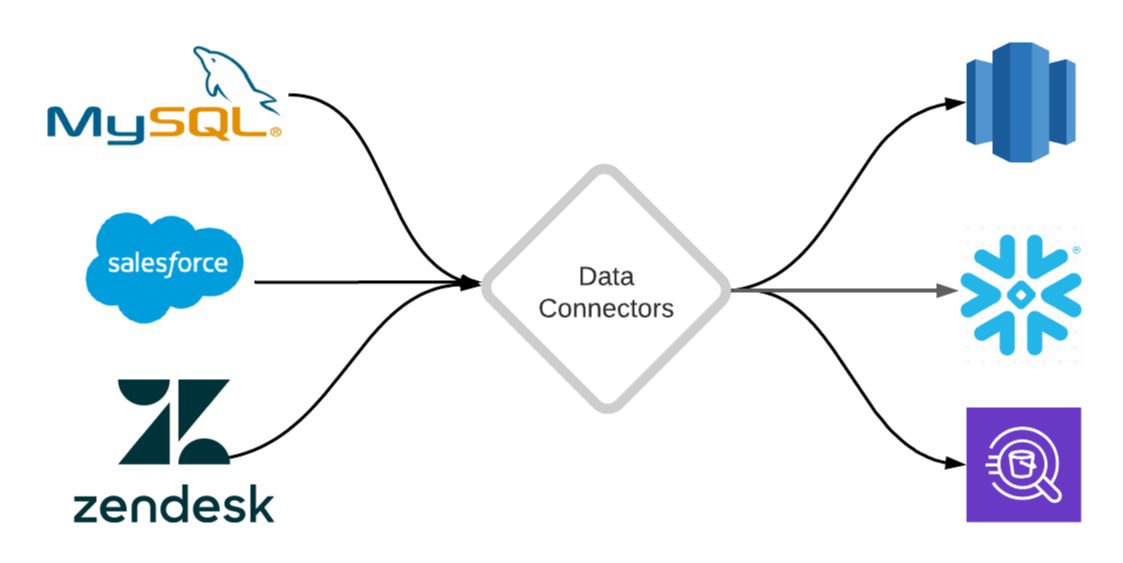
An Introduction to Data Connectors: Your First Step to Data Analytics
by byRishabh Bhargava@rishabhbhargava
byRishabh Bhargava@rishabhbhargava
Data Scientist at Datacoral. I enjoy all things data, startups and machine learning.
February 13th, 2021





Data Scientist at Datacoral. I enjoy all things data, startups and machine learning.


Data Scientist at Datacoral. I enjoy all things data, startups and machine learning.
About Author

Data Scientist at Datacoral. I enjoy all things data, startups and machine learning.
Comments















