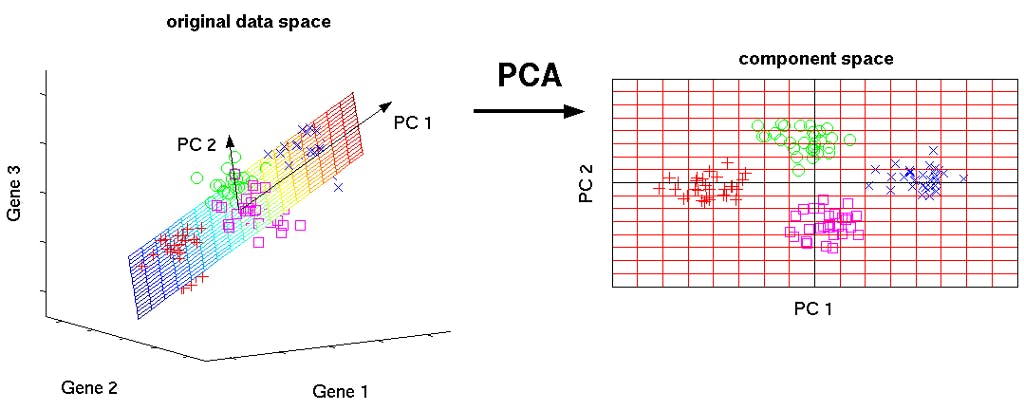
Principal Component Analysis is one of the techniques used for dimensionality reduction In the last blog, I had talked about how you can use . Here, we will see one of the classic algorithms that is being practiced since very long and continues to deliver desirable results. Autoencoders to represent the given input to dense latent space What are dimensions? In machine learning, simply refers to the number of features (i.e. input variables) in your dataset. Consider an example — dimensionality [ ] Source Let’s say you want to predict the price of the house. Then what all parameters/features will you consider? Area sq.ft Locality # Bedrooms Internet speed Distance from hospital Distance from main market etc .. etc Just now itself we are dealing with 6–7 dimensional data for just predicting the house price. So, . these things that matter while making any decisions are called dimensions What is high dimensional data? For the purpose of high dimension can be any number of dimension . Whereas, in general, I personally have found reduction working really well when visualizing the which are usually in the order of few 100s. visualization above 3 to 4 word embeddings Why reduce the dimensions? Large dimensions are difficult to train on, need . more computational power and time with very large dimensional data. Visualization is not possible Loading very high dimensional data can be an issue with . limited storage space in-memory It can be used to reduce the dimension of the features, potentially leading to for the learning algorithm by and . better performance removing redundant, obsolete highly correlated features Always Remember As a thumb rule, you should always do before applying PCA to any dataset. Standardizing the features so that they are centered around 0 with a standard deviation of 1 is not only important if we are comparing measurements that have different units, but it is also a general requirement for many machine learning algorithms. All this because, we would want all the scale of measurements to be treated on the same scale. feature standardization Under the hood PCA is a maximizer. It projects the original data onto the directions where variance is maximum. variance Variance is the measure of how spread out the data is. 2-D to 1-D transformation X(i) where i in [1,2,3,4,5] are the original data points in a 2-D space. Then Z(i) where i in [1,2,3,4,5] are the projected points on a 1-D space (Line). We chose the line going from -xy to +xy (dotted one) because the data is most spread in this direction. Now, for all the points in 2-D space X(i) we map them to 1-D space/component Z(i). Let’s do one We will be using for this experiment. People who are wondering what scikit-learn it . scikit-learn read this It is very easy to apply this statistical technique in python. ! ✌️ We will be dealing with a just for the purpose of this snippet. Thanks to the community curated dataset from sklearn.decomposition import PCA import matplotlib.pyplot as plt from sklearn.preprocessing import scale data = open('custom_embed.csv', 'rb') labels, dimensions = [], [] for line in data: line = line.split(",") lab = line[0].strip() dim = [float(j.strip()) for j in line[1].split()] labels.append(lab) dimensions.append(dim) # scaling the values X = scale(dimensions) pca = PCA(n_components=2) pca.fit(X) X1=pca.fit_transform(X) X1 = X1.tolist() # plotting x = [i[0] for i in X1] y = [i[1] for i in X1] n = ['king', 'school', 'university', 'man', 'emperor'] fig, ax = plt.subplots() ax.scatter(x, y) for i, txt in enumerate(n): ax.annotate(txt, (x[i],y[i])) plt.show() Embedding Visualization in 2-D It seems that we are successful in preserving the semantic properties of words as and when they are used even after reducing the dimension space from 300 to 2. I have tried to keep this blog simple and intuitive as much possible. For in-depth details of the algorithms see this Feel free to comment and share your thoughts. Do share and clap if you ❤ it.