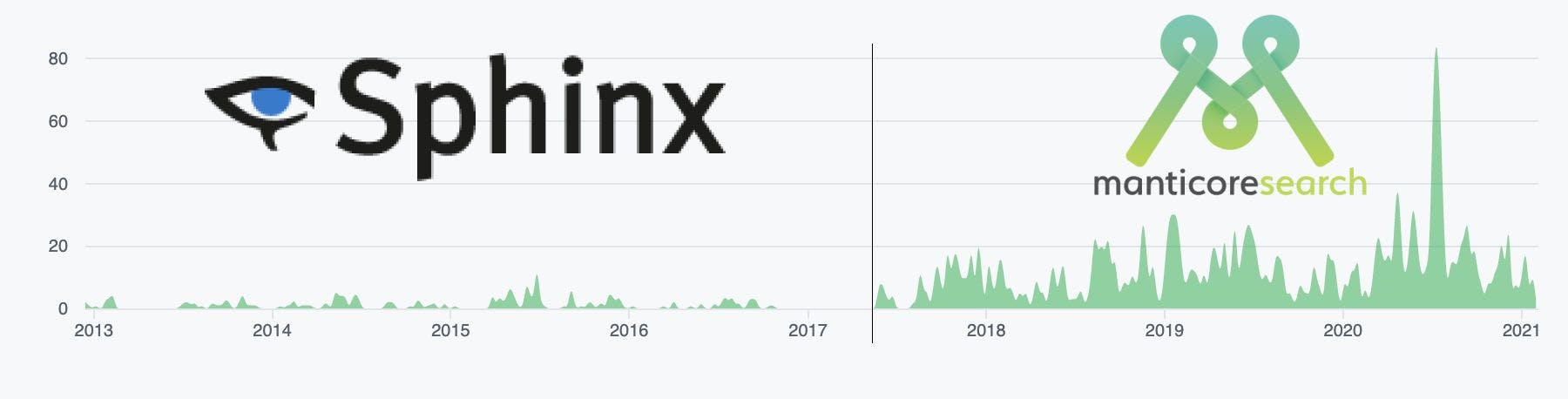
In May 2017 we made a fork of Sphinxsearch 2.3.2, which we called Manticore Search. Below you will find a brief report on Manticore Search as a fork of Sphinx and our achievements since then. Manticore Search (Disclaimer: The author is the CEO of Manticore Software) Disclaimer The author is the CEO of Manticore Software Why did we fork Sphinx? First of all, why did we do the fork? At the end of 2016, work on Sphinxsearch was suspended. Users who were using Sphinx and some customers that were supporting the development of the project were worried about that because: bugs were not being fixed for long periods of timenew features that had long been promised were not producedcommunication with the Sphinx team was broken bugs were not being fixed for long periods of time new features that had long been promised were not produced communication with the Sphinx team was broken After a few months the situation hadn’t changed and in mid June 2017 a group of proactive and experienced Sphinx users and support clients got together and decided to try to keep the product as a fork under the name of Manticore Search. We managed to gather back most of the Sphinx previous team that were already working in different companies, attract investments and in a short time could restore full-fledged work on the project. What were our objectives? The fork aimed three goals: Code support in general: bugfixing, small and large new featuresSupport for Sphinx and Manticore usersMore intensive development of the product than it was before. Unfortunately, by then Elasticsearch had already outrun Sphinx in many respects. Such things as: no replicationno auto idno JSON interfaceno way to create/delete an index on the flyno document storageinmature real-time indexesfocus on full-text search rather than search in general no replication no auto id no JSON interface no way to create/delete an index on the fly no document storage inmature real-time indexes focus on full-text search rather than search in general made Sphinx a very highly specialized solution with the need to tweak it manually in many cases. Many users had already migrated to Elasticsearch by then. It was a shame, because the fundamental data structures and algorithms in Sphinx were potentially and are in fact in many cases superior to Elasticsearch in performance. And SQL, which was much better developed in Sphinx than in Elasticsearch even now, was attractive to many. In addition to supporting existing Sphinx users, Manticore’s global goal was to implement the above and other features that would make Manticore Search a real alternative to Elasticsearch in most use cases. What we have already done Much more active development If you look at the github commit stats, you can see that as soon as the fork had happened (mid-2017) the development pace grew a lot: github commit stats If you look at the github commit stats, you can see that as soon as the fork had happened (mid-2017) the development pace grew a lot: github commit stats In three and a half years until March 2021, we have released 39 new versions. In 2020, we were releasing a new version each two months. Replication Many users have been waiting for replication in Sphinx for years. One of the first big features we made in Manticore was replication. Like everything in Manticore, we tried to make it as easy to use as possible. For example, to connect to a cluster, all you have to do is run a command like this: JOIN CLUSTER posts at 'neighbour-server'; JOIN CLUSTER posts at 'neighbour-server'; JOIN CLUSTER posts at 'neighbour-server'; JOIN CLUSTER posts at 'neighbour-server' ; which will make indexes from the cluster appear on the current node. Manticore's replication is: synchronousBased on Galera library, which is also used in MariaDB and Percona XtraDB. synchronous Based on Galera library, which is also used in MariaDB and Percona XtraDB. Auto id Without auto-id, Sphinx / Manticore was mostly considered just an extension to another database (mysql, postgres etc.) since there had to be something which generates IDs. We have implemented auto-id based on UUID_SHORT algorithm. The uniqueness is guaranteed up to 16 million inserts per second per server which should be sufficient in all cases. auto-id mysql> create table idx(doc text); Query OK, 0 rows affected (0.01 sec) mysql> insert into idx(doc) values('abc def'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx; +---------------------+---------+ | id | doc | +---------------------+---------+ | 1514145039905718278 | abc def | +---------------------+---------+ 1 row in set (0.00 sec) mysql> insert into idx(doc) values('def ghi'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx; +---------------------+---------+ | id | doc | +---------------------+---------+ | 1514145039905718278 | abc def | | 1514145039905718279 | def ghi | +---------------------+---------+ 2 rows in set (0.00 sec) mysql> create table idx(doc text); Query OK, 0 rows affected (0.01 sec) mysql> insert into idx(doc) values('abc def'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx; +---------------------+---------+ | id | doc | +---------------------+---------+ | 1514145039905718278 | abc def | +---------------------+---------+ 1 row in set (0.00 sec) mysql> insert into idx(doc) values('def ghi'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx; +---------------------+---------+ | id | doc | +---------------------+---------+ | 1514145039905718278 | abc def | | 1514145039905718279 | def ghi | +---------------------+---------+ 2 rows in set (0.00 sec) mysql> create table idx(doc text); Query OK, 0 rows affected (0.01 sec) mysql> insert into idx(doc) values('abc def'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx; +---------------------+---------+ | id | doc | +---------------------+---------+ | 1514145039905718278 | abc def | +---------------------+---------+ 1 row in set (0.00 sec) mysql> insert into idx(doc) values('def ghi'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx; +---------------------+---------+ | id | doc | +---------------------+---------+ | 1514145039905718278 | abc def | | 1514145039905718279 | def ghi | +---------------------+---------+ 2 rows in set (0.00 sec) mysql> create table idx(doc text); Query OK, 0 rows affected ( 0.01 sec) mysql> insert into idx(doc) values( 'abc def' ); Query OK, 1 row affected ( 0.00 sec) mysql> select * from idx; | 1514145039905718278 | abc def | 1 row in set ( 0.00 sec) mysql> insert into idx(doc) values( 'def ghi' ); Query OK, 1 row affected ( 0.00 sec) mysql> select * from idx; | 1514145039905718278 | abc def | | 1514145039905718279 | def ghi | 2 rows in set ( 0.00 sec) Document Storage In Sphinx 2.3.2 and earlier, you could only save document original texts in string attributes, that (like all attributes) are to be stored in memory for optimal performance. Many users did so, wasting RAM unnecessarily, which was expensive and could cause unexpected performance issues on large volumes. In Manticore we have made a new data type text which combines full-text indexing and storing the value on disk with lazy reading (i.e. the value is fetched at the very last stage of a query). The "stored" field values are not filterable and cannot be sorted or grouped. They just reside compressed on disk, so there is no need to store them in mysql/hbase/postgres and other databases (unless they are really needed there). This proved to be a very useful and commonly used feature. Since then Manticore now requires nothing but itself to implement a search application. have made Real-time indexes In Sphinx 2.3.2 and earlier many users were struggling using real-time indexes, because it often caused crashes and other side-effects. We’ve fixed most of the known bugs and design flaws, and we’re still working on some optimizations (mainly, related to automatic OPTIMIZE and read/write/merge isolation). But it’s already safe to say that real-time indexes can be used in production, which is actually what many users do. To mention few of the features we have added: multithreading: searching in several disk chunks of a single real-time index is done in parallel OPTIMIZE improvements: by default the chunks are merged not to 1, but to the number of cores on the server * 2 (that’s adjustable through the cutoff option). multithreading: searching in several disk chunks of a single real-time index is done in parallel OPTIMIZE improvements: by default the chunks are merged not to 1, but to the number of cores on the server * 2 (that’s adjustable through the cutoff option). cutoff We are working on automatic OPTIMIZE, so users don’t have to worry about compaction at all. charset_table = cjk, non_cjk Previously, if you wanted to support some language other than English or Russian, you often had to maintain big arrays in charset_table. It was inconvenient. We simplified it by putting everything you may need into internal charset_table arrays named non_cjk (for most languages) and cjk (for Chinese, Korean and Japanese). The non_cjk arrays is a default one for charset_table. Now you can search in English, Russian and, say, Turkish without problems: mysql> create table idx(doc text); Query OK, 0 rows affected (0.01 sec) mysql> insert into idx(doc) values('abc абв öğrenim'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx where match('abc'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> select * from idx where match('абв'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> select * from idx where match('ogrenim'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> create table idx(doc text); Query OK, 0 rows affected (0.01 sec) mysql> insert into idx(doc) values('abc абв öğrenim'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx where match('abc'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> select * from idx where match('абв'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> select * from idx where match('ogrenim'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> create table idx(doc text); Query OK, 0 rows affected (0.01 sec) mysql> insert into idx(doc) values('abc абв öğrenim'); Query OK, 1 row affected (0.00 sec) mysql> select * from idx where match('abc'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> select * from idx where match('абв'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> select * from idx where match('ogrenim'); +---------------------+----------------------+ | id | doc | +---------------------+----------------------+ | 1514145039905718280 | abc абв öğrenim | +---------------------+----------------------+ 1 row in set (0.00 sec) mysql> create table idx(doc text); Query OK, 0 rows affected ( 0.01 sec) mysql> insert into idx(doc) values( 'abc абв öğrenim' ); Query OK, 1 row affected ( 0.00 sec) mysql> select * from idx where match( 'abc' ); | 1514145039905718280 | abc абв öğrenim | 1 row in set ( 0.00 sec) mysql> select * from idx where match( 'абв' ); | 1514145039905718280 | abc абв öğrenim | 1 row in set ( 0.00 sec) mysql> select * from idx where match( 'ogrenim' ); | 1514145039905718280 | abc абв öğrenim | 1 row in set ( 0.00 sec) Official Docker image We released and are maintaining the official docker image for Manticore Search. You can now run Manticore in seconds anywhere as long as there's docker. docker image ➜ ~ docker run --name manticore --rm -d manticoresearch/manticore && docker exec -it manticore mysql && docker stop manticore 525aa92aa0bcef3e6f745ddeb11fc95040858d19cde4c9118b47f0f414324a79 mysql> create table idx(f text); mysql> desc idx; +-------+--------+----------------+ | Field | Type | Properties | +-------+--------+----------------+ | id | bigint | | | f | text | indexed stored | +-------+--------+----------------+ ➜ ~ docker run --name manticore --rm -d manticoresearch/manticore && docker exec -it manticore mysql && docker stop manticore 525aa92aa0bcef3e6f745ddeb11fc95040858d19cde4c9118b47f0f414324a79 mysql> create table idx(f text); mysql> desc idx; +-------+--------+----------------+ | Field | Type | Properties | +-------+--------+----------------+ | id | bigint | | | f | text | indexed stored | +-------+--------+----------------+ ➜ ~ docker run --name manticore --rm -d manticoresearch/manticore && docker exec -it manticore mysql && docker stop manticore 525aa92aa0bcef3e6f745ddeb11fc95040858d19cde4c9118b47f0f414324a79 mysql> create table idx(f text); mysql> desc idx; +-------+--------+----------------+ | Field | Type | Properties | +-------+--------+----------------+ | id | bigint | | | f | text | indexed stored | +-------+--------+----------------+ ➜ ~ docker run --name manticore --rm -d manticoresearch/manticore && docker exec -it manticore mysql && docker stop manticore Besides, manticore:dev tag always points to the most recent development version of Manticore Search. Packages repository All new releases and fresh development versions can be found at https://repo.manticoresearch.com/ https://repo.manticoresearch.com/ From there you can also easily install Manticore via YUM and APT. We also support Homebrew and maintain builds for Windows. easily install Manticore via YUM and APT NLP: Natural Language Processing On the NLP side, we've made the following improvements: Chinese segmentation using the ICU librarydefault stop words for most languages out of the box:mysql> create table idx(doc text) stopwords='en'; Query OK, 0 rows affected (0.05 sec) mysql> call keywords('to be or not to be that is the question', 'idx'); +------+-----------+------------+ | qpos | tokenized | normalized | +------+-----------+------------+ | 10 | question | question | +------+-----------+------------+ 1 row in set (0.01 sec) Chinese segmentation using the ICU library ICU library default stop words for most languages out of the box: mysql> create table idx(doc text) stopwords='en'; Query OK, 0 rows affected (0.05 sec) mysql> call keywords('to be or not to be that is the question', 'idx'); +------+-----------+------------+ | qpos | tokenized | normalized | +------+-----------+------------+ | 10 | question | question | +------+-----------+------------+ 1 row in set (0.01 sec) mysql> create table idx(doc text) stopwords='en'; Query OK, 0 rows affected (0.05 sec) mysql> call keywords('to be or not to be that is the question', 'idx'); +------+-----------+------------+ | qpos | tokenized | normalized | +------+-----------+------------+ | 10 | question | question | +------+-----------+------------+ 1 row in set (0.01 sec) mysql> create table idx(doc text) stopwords='en'; Query OK, 0 rows affected (0.05 sec) mysql> call keywords('to be or not to be that is the question', 'idx'); +------+-----------+------------+ | qpos | tokenized | normalized | +------+-----------+------------+ | 10 | question | question | +------+-----------+------------+ 1 row in set (0.01 sec) mysql> create table idx(doc text) stopwords= 'en' ; Query OK, 0 rows affected ( 0.05 sec) mysql> call keywords( 'to be or not to be that is the question' , 'idx' ); | 10 | question | question | 1 row in set ( 0.01 sec) Snowball 2.0 support for more languagesEasier syntax highlighting:mysql> insert into idx(doc) values('Polly wants a cracker'); Query OK, 1 row affected (0.09 sec) mysql> select highlight() from idx where match('polly cracker'); +-------------------------------------+ | highlight() | +-------------------------------------+ | <b>Polly</b> wants a <b>cracker</b> | +-------------------------------------+ 1 row in set (0.10 sec) Snowball 2.0 support for more languages more languages Easier syntax highlighting: mysql> insert into idx(doc) values('Polly wants a cracker'); Query OK, 1 row affected (0.09 sec) mysql> select highlight() from idx where match('polly cracker'); +-------------------------------------+ | highlight() | +-------------------------------------+ | <b>Polly</b> wants a <b>cracker</b> | +-------------------------------------+ 1 row in set (0.10 sec) mysql> insert into idx(doc) values('Polly wants a cracker'); Query OK, 1 row affected (0.09 sec) mysql> select highlight() from idx where match('polly cracker'); +-------------------------------------+ | highlight() | +-------------------------------------+ | <b>Polly</b> wants a <b>cracker</b> | +-------------------------------------+ 1 row in set (0.10 sec) mysql> insert into idx(doc) values('Polly wants a cracker'); Query OK, 1 row affected (0.09 sec) mysql> select highlight() from idx where match('polly cracker'); +-------------------------------------+ | highlight() | +-------------------------------------+ | <b>Polly</b> wants a <b>cracker</b> | +-------------------------------------+ 1 row in set (0.10 sec) mysql> insert into idx(doc) values( 'Polly wants a cracker' ); Query OK, 1 row affected ( 0.09 sec) mysql> select highlight() from idx where match( 'polly cracker' ); | < b > Polly </ b > wants a <b>cracker</b> | 1 row in set ( 0.10 sec) New multitasking mode For multitasking Manticore now uses coroutines. In addition to the fact that the code has become much simpler and more reliable, it's not required any more to use different dist_threads values for different indexes to make searches to them parallelize optimally. There's now a global setting threads, which is equal to the number of cores on the server by default. In most cases you don't need to touch it at all for optimal performance. OR support in WHERE In Sphinx 2/3, you can't easily filter by attributes using operator OR which is a big limitation. We've fixed it in Manticore: mysql> select i, s from t where i = 1 or s = 'abc'; +------+------+ | i | s | +------+------+ | 1 | abc | | 1 | def | | 2 | abc | +------+------+ 3 rows in set (0.00 sec) Sphinx 3: mysql> select * from t where i = 1 or s = 'abc'; ERROR 1064 (42000): sphinxql: syntax error, unexpected OR, expecting $end near 'or s = 'abc'' mysql> select i, s from t where i = 1 or s = 'abc'; +------+------+ | i | s | +------+------+ | 1 | abc | | 1 | def | | 2 | abc | +------+------+ 3 rows in set (0.00 sec) Sphinx 3: mysql> select * from t where i = 1 or s = 'abc'; ERROR 1064 (42000): sphinxql: syntax error, unexpected OR, expecting $end near 'or s = 'abc'' mysql> select i, s from t where i = 1 or s = 'abc'; +------+------+ | i | s | +------+------+ | 1 | abc | | 1 | def | | 2 | abc | +------+------+ 3 rows in set (0.00 sec) Sphinx 3: mysql> select * from t where i = 1 or s = 'abc'; ERROR 1064 (42000): sphinxql: syntax error, unexpected OR, expecting $end near 'or s = 'abc'' mysql> select i, s from t where i = 1 or s = 'abc' ; | 1 | abc | | 1 | def | | 2 | abc | 3 rows in set ( 0.00 sec) Sphinx 3 : mysql> select * from t where i = 1 or s = 'abc' ; ERROR 1064 ( 42000 ): sphinxql: syntax error, unexpected OR, expecting $end near 'or s = ' abc '' SQL is cool. We love SQL. And in Sphinx / Manticore everything about query syntax can be done via SQL. But there are situations where the best solution is to use a JSON interface, like in Elasticsearch. SQL is great for query designing, while JSON rocks when you need to integrate a complex query into your application. Besides, HTTP allows to do a lot of interesting things: use external HTTP load balancers and proxing, which allows to implement authentication, RBAC, etc. quite easily. New clients for more languages Even easier than using the JSON over HTTP is to to use a client for a specific programming language your application is written in. We've implemented new clients for php, python, java, javascript, elixir, go. Most of them are based on the new JSON interface and their code is generated automatically, allowing us to add new features to the clients much faster. php python java javascript elixir go HTTPS support Security matters. We've made HTTPS support available out of the box. It's still better not to expose Manticore Search instance to the internet as there is no built-in authentication, but it's now safer to transfer queries and results from a client to Manticore Search over the LAN. SSL for mysql-interface is also supported. HTTPS support FEDERATED support In addition to SphinxSE (a built-in mysql engine that allows you to integrate Sphinx/Manticore more closely with mysql) you can now use MySQL's FEDERATED engine which is available in MySQL and MariaDB. you can now use ProxySQL support ProxySQL is also supported and you can use it to make quite interesting things that expand capabilities of Manticore Search. also supported RT mode One of the main changes we've made was the imperative (i.e. via CREATE/ALTER/DROP table) way of working with Manticore. As you can see from the SQL examples above you don't need to define an index in config any more. As in other databases, you can now create, alter and delete indexes in Manticore on the fly without the need to edit config, restart the instance, delete real-time index files and all that hassle. Data schema is now completely separated from server's settings. And that is the default mode. We call it RT mode. But the declarative mode (we call it Plain mode) is still supported as well. We do not consider it a rudiment and do not plan to get rid of that. Just as you can communicate with Kubernetes the both ways either via yaml files or via specific commands, you can communicate with Manticore similarly too: you can describe everything in a config and benefit the possibility of easy config porting and faster indexes deployment, or you can create indexes on the fly which allows to integrate it easier to your application It is not possible and not in plans to mix the use of modes. Percolate index The normal way of doing searches is to store documents we want to search and perform queries against them. However there are cases when we want to apply a query to an incoming new document to signal the matching. There are some scenarios where this is wanted. For example a monitoring system doesn't just collect data, but it's also desired to notify user on different events. That can be reaching some threshold for a metric or a certain value that appears in the monitored data. Another similar case is news aggregation. You can notify the user about any fresh news, but user might want to be notified only about certain categories or topics. Going further, they might be only interested about certain "keywords". All this is now possible in Manticore if you use a percolate index. mysql> create table t(f text, j json) type='percolate'; mysql> insert into t(query,filters) values('abc', 'j.a=1'); mysql> call pq('t', '[{"f": "abc def", "j": {"a": 1}}, {"f": "abc ghi"}, {"j": {"a": 1}}]', 1 as query); +---------------------+-------+------+---------+ | id | query | tags | filters | +---------------------+-------+------+---------+ | 8215503050178035714 | abc | | j.a=1 | +---------------------+-------+------+---------+ mysql> create table t(f text, j json) type='percolate'; mysql> insert into t(query,filters) values('abc', 'j.a=1'); mysql> call pq('t', '[{"f": "abc def", "j": {"a": 1}}, {"f": "abc ghi"}, {"j": {"a": 1}}]', 1 as query); +---------------------+-------+------+---------+ | id | query | tags | filters | +---------------------+-------+------+---------+ | 8215503050178035714 | abc | | j.a=1 | +---------------------+-------+------+---------+ mysql> create table t(f text, j json) type='percolate'; mysql> insert into t(query,filters) values('abc', 'j.a=1'); mysql> call pq('t', '[{"f": "abc def", "j": {"a": 1}}, {"f": "abc ghi"}, {"j": {"a": 1}}]', 1 as query); +---------------------+-------+------+---------+ | id | query | tags | filters | +---------------------+-------+------+---------+ | 8215503050178035714 | abc | | j.a=1 | +---------------------+-------+------+---------+ mysql> create table t(f text, j json) type= 'percolate' ; mysql> insert into t(query,filters) values( 'abc' , 'j.a=1' ); mysql> call pq( 't' , '[{"f": "abc def", "j": {"a": 1}}, {"f": "abc ghi"}, {"j": {"a": 1}}]' , 1 as query); | 8215503050178035714 | abc | | j.a= 1 | Works faster than in Elasticsearch. faster than in Elasticsearch New user-friendly documentation - https://manual.manticoresearch.com https://manual.manticoresearch.com For key Manticore Search functionality there are examples for most supported clients. Search in the manual of course uses Manticore Search as a backend. What else: Smart search results highlighting in search resultsHTTP examples can be copied in one click directly as a curl command with parametersIn addition, we have specially registered short domain mnt.cr, so that you can very quickly find info on smth you need right now by CTRL-T/CMD-T in your browswer and typing for example mnt.cr/proximity , mnt.cr/quorum, mnt.cr/percolate.Interactive Courses - https://play.manticoresearch.com mnt.cr/proximity mnt.cr/quorum mnt.cr/percolate https://play.manticoresearch.com To make it easier to get started with Manticore Search we've made the platform for interactive courses https://play.manticoresearch.com and of course the courses themselves, that you can take right from your browser without installing anything at all. In few seconds you can see how Manticore Search replication works or how to highlight search results https://play.manticoresearch.com Manticore Search replication works highlight search results Github as a bug tracker We use Github as a public bug/task tracker. Github Sphinx 3 Sphinx 3.0.1 was released in December 2017. Until October 2018 there were three more releases and another one in July 2020 (3.3.1, the last version as of March 2021). Many interesting features appeared, including secondary indexes and some machine learning capabilities. So what's the problem? Why do people need Manticore at all? One of the reasons is that, unfortunately, neither the first release of Sphinx 3 nor the last one is currently open source: both in a sense that Sphinx 3 code is not available and in a broader sense of open source. On the downloads page it's said that Sphinx is now available under the "delayed FOSS" license. What exactly this license is and where it can be found is not disclosed. It's not clear:whether it's still GPLv2 (i.e. "delayed FOSS" means delayed GPLv2), since the code is probably based on Sphinx 2, which is GPLv2 (like Manticore). But then where is the source code?or it's not GPLv2, because no license is attached to the binaries and it's unknown if the code is even based on Sphinx 2 or not? Do the restrictions of GPLv2 apply? Is it okay to distribute Sphinx 3 binaries as you wish, since there's no license textThere have been no releases since July 2020. There are a lot of bugs, including major crashes. When will they be fixed? both in a sense that Sphinx 3 code is not available and in a broader sense of open source. On the downloads page it's said that Sphinx is now available under the "delayed FOSS" license. What exactly this license is and where it can be found is not disclosed. It's not clear:whether it's still GPLv2 (i.e. "delayed FOSS" means delayed GPLv2), since the code is probably based on Sphinx 2, which is GPLv2 (like Manticore). But then where is the source code?or it's not GPLv2, because no license is attached to the binaries and it's unknown if the code is even based on Sphinx 2 or not? Do the restrictions of GPLv2 apply? Is it okay to distribute Sphinx 3 binaries as you wish, since there's no license text broader sense of open source it's said There have been no releases since July 2020. There are a lot of bugs, including major crashes. When will they be fixed? a lot of bugs There are a lot of questions and no answers. All this makes it very risky to use Sphinx 3 by companies and individuals who care about the legal side of things and the stability of the project. Not many companies has a possibility to invest their employees' time into the project which looks frozen and has so unclear license. All in all Sphinx 3 can now be considered a proprietary solution for a limited range of users with very specific goals. It's a pity that the open source world has lost Sphinx. We can only hope that something will change in the future. Any benchmarks? Yes! Let's test the dataset consisting of 1M+ comments from HackerNews and numeric attributes. dataset More about the test: plain index built from the dataset. The size of the index files is about 1 gigabyte set of various queries (132 requests) from full-text search to filtering and groupingdockers running on a bare-metal server with different memory limitations we use SQL over mysqli client from a PHP script to issue the queries before each new query we clearing all caches including OS cache and restart the docker, then we run 5 attempts, the lowest response time goes into the statistics. plain index built from the dataset. The size of the index files is about 1 gigabyte set of various queries (132 requests) from full-text search to filtering and grouping dockers running on a bare-metal server with different memory limitations we use SQL over mysqli client from a PHP script to issue the queries before each new query we clearing all caches including OS cache and restart the docker, then we run 5 attempts, the lowest response time goes into the statistics. Results: 100 megabytes limit: 500 megabytes limit: 1000 megabytes limit: The future of Manticore Search So, we already have an actively developed product under the clear open source license GPLv2 with replication, auto-id, properly working real-time indexes, JSON interface, nice documentation, interactive courses and much more. What's next? Our roadmap is: New Manticore engine Since early 2020, we've been working on a columnar storage and processing library with default indexing (as opposed to, say, Clickhouse). For Manticore and Sphinx users it will solve the following problems: the need for a large amount of RAM to search fast in a large collection of documents and attributes suboptimal grouping performance suboptimal filtering performance when part of the attributes doesn't fit into RAM the need for a large amount of RAM to search fast in a large collection of documents and attributes suboptimal grouping performance suboptimal filtering performance when part of the attributes doesn't fit into RAM We already have a beta version ready and here are some first results comparing Manticore Columnar Library + Manticore Search vs Elasticsearch on the same dataset as above (excluding full-text queries, i.e. mostly grouping queries): beta version ready There is still a lot of work to be done. The library is available under a more permissive open source license Apache 2.0 and can be used in Manticore Search as well as in other projects (in Sphinx too if they like). Auto OPTIMIZE We realize how inconvenient is to call OPTIMIZE manually for real-time indexes compaction. We're working on solving it and hope it will be included into the next release. Follow us in twitter to not miss that. twitter Integration with Kibana Since users can now do more analytics with the new Manticore engine it would be nice to be able to visualize it easily as well. Grafana is cool, but may be a little bit tricky to be used for full-text search. Kibana is also nice, a lot of people know and use it. We have an alpha version of the integration between Manticore Search and Kibana. It's not publicly available, but as soon as we are done with bugfixing and can consider it a beta it will be opensourced. Logstash integration Manticore Search already has JSON protocol. We are going to improve the PUT and POST methods to make them compatible with Elasticsearch for the INSERT/REPLACE queries. In addition, we plan to make it possible to create an index on the fly based on the first inserted documents. All this will allow you to write data to Manticore Search instead of Elasticsearch from Logstash, Fluentd, Beats and the like. Automatic sharding This is another project in progress. We already understand what kind of difficulties we'll have to face and more or less how to solve them. We're planning for the second quarter. Alternative to Logstash Logstash requires the user to spend a lot of time to start ingesting from a new custom log type. And if you add any new line, the parsing rules will have to be updated. For last few months we've been developing a system, which can solve this problem almost completely. It will allow you to parse your logs with virtually no assistance and a nice UI to name your fields and make final fine-tuning. custom If you like what we do stay tuned with us at: GitHub | Forum | Slack | Telegram | Twitter | VK | Facebook GitHub Forum Slack Telegram Twitter VK Facebook (Disclaimer: The author is the CEO of Manticore Software) Disclaimer The author is the CEO of Manticore Software Also published here. here