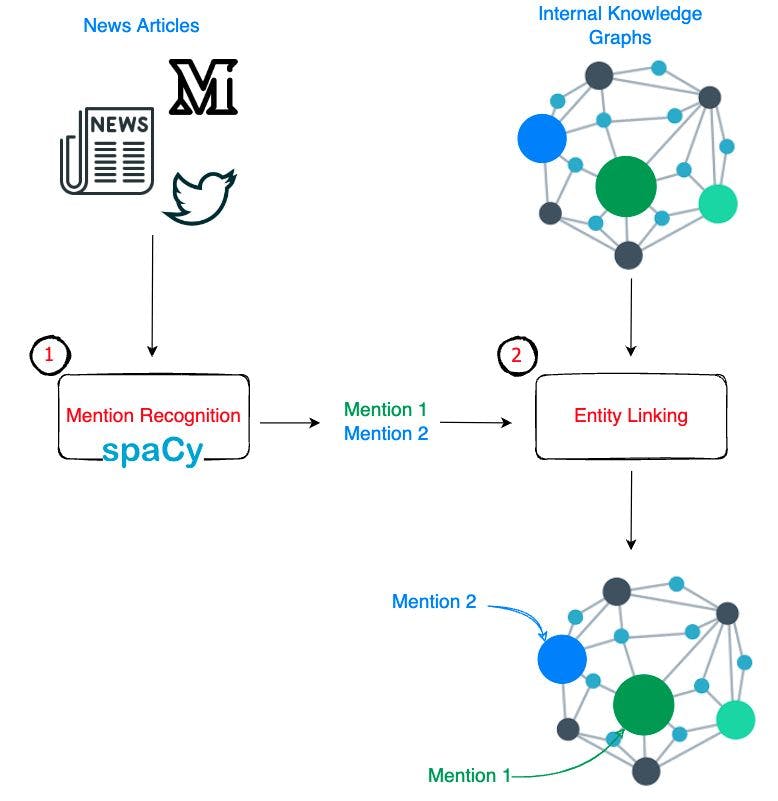
161 reads
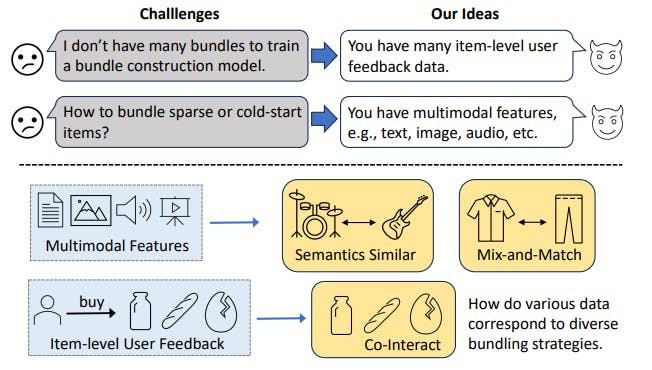
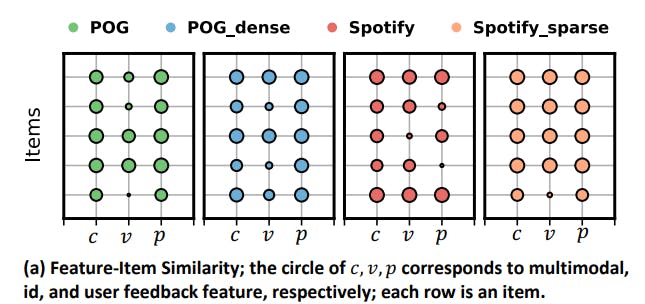
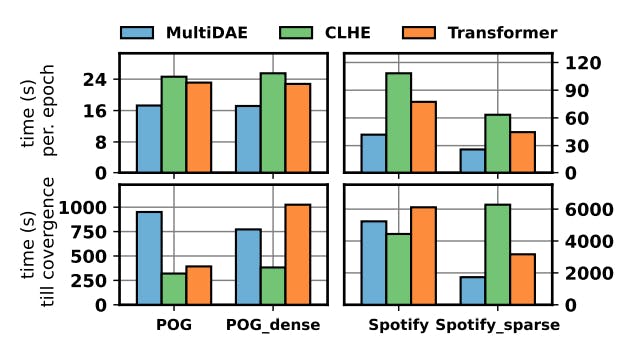
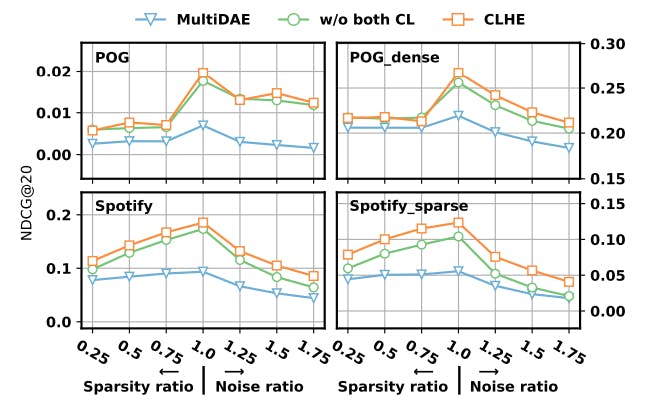
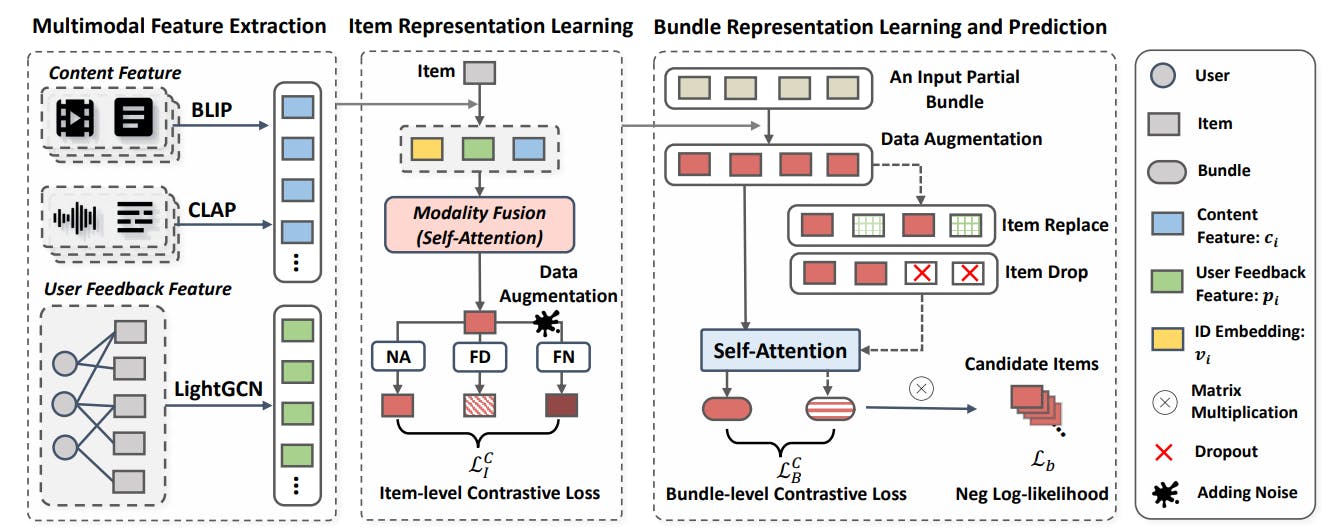
A Comprehensive Approach to Multimodal Bundle Construction with CLHE Methodology
by byThe FeedbackLoop: #1 in PM Education@feedbackloop
byThe FeedbackLoop: #1 in PM Education@feedbackloop
The FeedbackLoop offers premium product management education, research papers, and certifications. Start building today!
January 30th, 2024





The FeedbackLoop offers premium product management education, research papers, and certifications. Start building today!


The FeedbackLoop offers premium product management education, research papers, and certifications. Start building today!
About Author

The FeedbackLoop offers premium product management education, research papers, and certifications. Start building today!
Comments