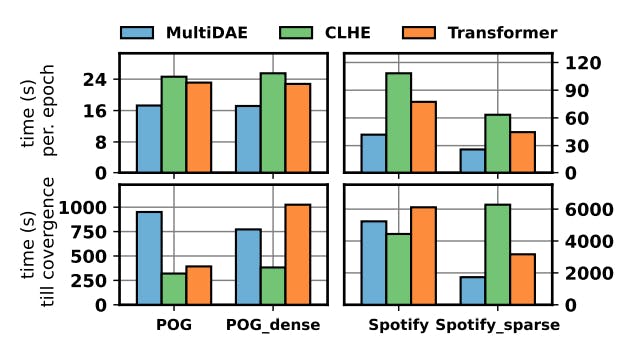
312 reads
Neural Entity Linking and How JPMorgan Chase Plans to Use it
by
August 3rd, 2022





Audio Presented by



About Author

ML Engineer @ Juniper Networks | https://medium.com/@harshit158
Comments

ML Engineer @ Juniper Networks | https://medium.com/@harshit158