























































Jan 01, 1970
4,287 판독값
심층 신경망의 모델 양자화
너무 오래; 읽다
양자화는 연속 범위의 값을 더 작은 이산 값 세트로 변환하는 프로세스로, 다양한 장치에서 추론 속도를 향상시키기 위해 심층 신경망에서 자주 사용됩니다. 이 변환에는 float32와 같은 고정밀 형식을 int8과 같은 낮은 정밀도 형식으로 매핑하는 작업이 포함됩니다. 양자화는 균일(선형 매핑) 또는 비균일(비선형 매핑)일 수 있습니다. 대칭 양자화에서는 입력의 0이 출력의 0으로 매핑되는 반면 비대칭 양자화는 이 매핑을 이동합니다. 스케일 팩터와 영점은 교정을 통해 결정되는 양자화에 중요한 매개변수입니다. 양자화 모드에는 PTQ(Post Training Quantization) 및 QAT(Quantization Aware Training)가 포함되며, QAT는 미세 조정을 통해 더 나은 모델 정확도를 제공합니다. 여기에는 미세 조정에 필요한 미분성과 양자화가 호환되도록 가짜 양자화기를 사용하는 작업이 포함됩니다.
양자화는 큰 실수 집합의 값을 작은 이산 집합의 값으로 매핑하는 프로세스로 정의할 수 있습니다. 일반적으로 여기에는 연속 입력을 출력의 고정 값으로 매핑하는 작업이 포함됩니다. 이를 달성하는 일반적인 방법은 반올림하거나 자르는 것입니다. 반올림의 경우 가장 가까운 정수를 계산합니다. 예를 들어 1.8의 값은 2가 됩니다. 그러나 1.2의 값은 1이 됩니다. 잘림의 경우 맹목적으로 소수점 이하의 값을 제거하여 입력을 정수로 변환합니다.
양자화에 대한 동기
어떤 방식으로 진행하든 심층 신경망의 양자화 뒤에 숨은 주된 동기는 추론 속도를 향상시키는 것입니다. 신경망의 추론과 훈련이 계산적으로 상당히 비용이 많이 든다는 것은 말할 필요도 없습니다. 대규모 언어 모델 의 출현으로 이러한 모델의 매개변수 수가 증가하고 있으며 이는 메모리 사용량이 점점 더 높아지고 있음을 의미합니다.
이러한 신경망이 진화하는 속도로 인해 노트북이나 휴대폰, 심지어 시계와 같은 작은 장치에서도 이러한 신경망을 실행하려는 수요가 증가하고 있습니다. 양자화 없이는 이 중 어느 것도 불가능합니다.
양자화에 대해 알아보기 전에 훈련된 신경망은 컴퓨터 메모리에 저장된 부동 숫자에 불과하다는 점을 잊지 마세요.
컴퓨터에 숫자를 저장하기 위한 잘 알려진 표현이나 형식 중 일부는 float32 또는 FP32, float16 또는 FP16, int8, bfloat16입니다. 여기서 B는 Google Brain을 의미하며 최근에는 행렬이나 텐서를 처리하기 위한 특수 형식인 텐서 부동 32 또는 TF32가 있습니다. 운영. 이러한 각 형식은 서로 다른 메모리 청크를 소비합니다. 예를 들어, float32는 부호에 1비트, 지수에 8비트, 가수에 23비트를 할당합니다.
마찬가지로, float16 또는 FP16은 부호에 1비트를 할당하지만 지수에는 5비트, 가수에는 10비트만 할당합니다. 반면, BF16은 지수에 8비트를 할당하고 가수에 7비트만 할당합니다.
심층 네트워크의 양자화
표현이 충분합니다. 제가 말하고자 하는 것은 더 높은 메모리 형식에서 더 낮은 메모리 형식으로의 변환을 양자화라고 한다는 것입니다. 딥러닝 용어로 말하면, Float32는 단정밀도 또는 전체 정밀도라고 하며, Float16 및 BFloat16은 절반 정밀도 라고 합니다. 딥 러닝 모델을 훈련하고 저장하는 기본 방식은 완전한 정밀도입니다. 가장 일반적으로 사용되는 변환은 전체 정밀도에서 int8 형식으로의 변환입니다.
양자화 유형
양자화는 균일 하거나 불균일 할 수 있습니다. 균일한 경우, 입력에서 출력으로의 매핑은 균일한 간격의 입력에 대해 균일한 간격의 출력을 생성하는 선형 함수입니다. 균일하지 않은 경우 입력에서 출력으로의 매핑은 비선형 함수이므로 출력은 균일한 입력에 대해 균일한 간격으로 배치되지 않습니다.
균일한 유형으로 들어가면 선형 매핑 기능은 크기 조정 및 반올림 작업이 될 수 있습니다. 따라서 균일한 양자화에는 방정식의 스케일링 계수 S가 포함됩니다.
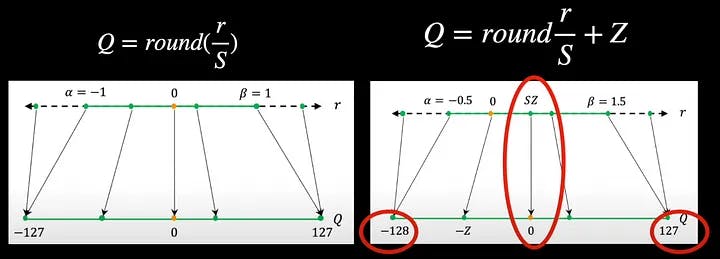
float16에서 int8로 변환할 때 항상 -127과 더하기 127 사이의 값으로 제한할 수 있으며 입력의 0이 대칭 매핑으로 이어지는 출력의 0에 완벽하게 매핑되도록 보장할 수 있으며 따라서 이 양자화 를 대칭이라고 합니다. 양자화 .
반면, 0의 양쪽 값이 동일하지 않은 경우(예: -128과 +127 사이) 또한 입력의 0을 출력의 0이 아닌 다른 값에 매핑하는 경우 이를 비대칭 양자화 라고 합니다. 이제 출력에서 0 값이 이동되었으므로 방정식에 0 요소 Z 를 포함하여 방정식에서 이를 계산해야 합니다.
척도 및 제로 팩터 선택
스케일 팩터와 영점을 선택하는 방법을 알아보기 위해 위 그림과 같이 실수 축에 분포된 입력의 예를 살펴보겠습니다. 스케일 팩터는 본질적으로 최소값 r_min 에서 최대값 r_max 까지 입력 오른쪽의 전체 범위를 균일한 분할로 나눕니다. 그러나 음수 값은 알파, 양수 값은 베타 등 어느 시점에서 이 입력을 클리핑하도록 선택할 수 있습니다. 알파와 베타 이외의 값은 알파와 동일한 출력에 매핑되므로 의미가 없습니다. 이 예에서는 -127과 +127입니다. 이러한 클리핑 값 알파 및 베타와 그에 따른 클리핑 범위를 선택하는 프로세스를 교정 이라고 합니다.
과도한 클리핑을 방지하기 위해 가장 쉬운 옵션은 알파를 r_min과 동일하게 설정하고 베타를 r_max와 동일하게 설정하는 것입니다. 그리고 우리는 이러한 r_min 및 r_max 값을 사용하여 스케일 팩터 S 를 계산할 수 있습니다. 그러나 이로 인해 출력이 비대칭이 될 수 있습니다. 예를 들어 입력의 r_max는 1.5일 수 있지만 r_min은 -1.2만 될 수 있습니다. 따라서 대칭 양자화를 제한하려면 알파와 베타가 둘 중 최대값이 되어야 하며 물론 영점을 0으로 설정해야 합니다.
대칭 양자화는 훈련된 가중치가 추론 중에 이미 사전 계산되어 추론 중에 변경되지 않으므로 신경망 가중치를 양자화할 때 사용되는 것입니다. 영점이 0으로 설정되어 있기 때문에 비대칭의 경우에 비해 계산도 더 간단합니다.
이제 입력이 한 방향, 즉 긍정적인 방향으로 치우쳐 있는 예를 검토해 보겠습니다. 이는 ReLU 또는 GeLU와 같은 가장 성공적인 활성화 함수의 출력과 유사합니다. 게다가 활성화의 출력은 입력에 따라 변경됩니다. 예를 들어, 고양이 이미지 두 개를 표시할 때 활성화 함수의 출력은 상당히 다릅니다. 이제 질문은 "양자화 범위를 언제 교정해야 합니까?"입니다. 훈련중인가요? 아니면 추론 중에 그리고 예측을 위한 데이터를 얻을 때?
양자화 모드
이 질문은 특히 PTQ( Post Training Quantization )에서 다양한 양자화 모드로 이어집니다. PTQ에서는 추가 학습을 수행하지 않고 사전 학습된 모델로 시작합니다. 모델에 필요한 중요한 데이터에는 클리핑 범위를 계산하는 데 사용되는 교정 데이터와 그에 따른 스케일 팩터(S) 및 영점(Z)이 포함됩니다. 일반적으로 이 교정 데이터는 모델 가중치에서 파생됩니다. 교정 프로세스가 끝나면 모델의 양자화를 진행하여 양자화된 모델을 얻을 수 있습니다.
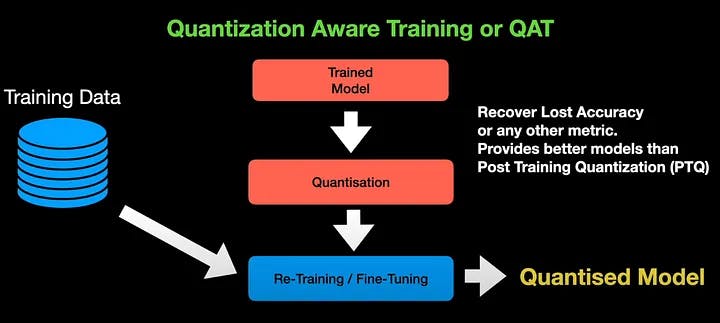
양자화 인식 훈련(Quantization Aware Training , 줄여서 QAT)에서는 표준 절차를 사용하여 훈련된 모델을 양자화한 다음 양자화된 모델을 얻기 위해 새로운 훈련 데이터를 사용하여 추가 미세 조정 또는 재훈련을 수행합니다. QAT는 일반적으로 손실된 정확도나 양자화 중에 우려되는 기타 측정항목을 복구하기 위해 모델의 매개변수를 조정하기 위해 수행됩니다. 따라서 QAT는 훈련 후 양자화보다 더 나은 모델을 제공하는 경향이 있습니다.
미세 조정을 수행하려면 모델이 미분 가능해야 합니다. 그러나 양자화 연산은 미분 불가능합니다. 이를 극복하기 위해 우리는 직선 추정기와 같은 가짜 양자화기를 사용합니다. 미세 조정 중에 이러한 추정기는 양자화 오류를 추정하고 오류는 훈련 오류와 결합되어 더 나은 성능을 위해 모델을 미세 조정합니다. 미세 조정 중에 부동 소수점의 양자화된 모델에 대해 순방향 및 역방향 전달이 수행됩니다. 그러나 매개변수는 각 그래디언트 업데이트 후에 양자화됩니다.
딥러닝의 모델 양자화를 설명하는 아래 동영상을 확인하세요.
요약
이는 양자화의 기본 사항을 거의 다룹니다. 우리는 양자화의 필요성과 대칭 및 비대칭과 같은 다양한 유형의 양자화로 시작했습니다. 또한 우리는 양자화 매개변수, 즉 스케일 팩터와 영점을 선택하는 방법을 빠르게 배웠습니다. 그리고 우리는 다양한 양자화 모드로 마무리했습니다. 하지만 PyTorch나 TensorFlow에서는 이 모든 것이 어떻게 구현됩니까? 그것은 다른 날을 위한 것입니다. 이 영상을 통해 딥러닝의 양자화에 대한 통찰력을 얻으셨기를 바랍니다.
다음번에 뵙기를 바랍니다. 그때까지 조심하세요!
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
태그 걸기
Languages
이 기사는 다음에서 발표되었습니다....
관련 기사
대형 언어 모델: Transformers 탐색 - 2부
#llm


효과적인 프롬프트를 작성하고 AI를 최대한 활용하는 방법 #writing-prompts
Jan 01, 1970

