





















































Jan 01, 1970
4,299 lecturas
Cuantización de modelos en redes neuronales profundas
Demasiado Largo; Para Leer
La cuantización es el proceso de convertir valores de un rango continuo a un conjunto más pequeño de valores discretos, que a menudo se utiliza en redes neuronales profundas para mejorar la velocidad de inferencia en varios dispositivos. Esta conversión implica mapear formatos de alta precisión como float32 a formatos de menor precisión como int8. La cuantificación puede ser uniforme (mapeo lineal) o no uniforme (mapeo no lineal). En la cuantificación simétrica, el cero en la entrada se asigna a cero en la salida, mientras que la cuantificación asimétrica desplaza esta asignación. El factor de escala y el punto cero son parámetros cruciales para la cuantificación, determinados mediante calibración. Los modos de cuantificación incluyen la cuantificación posterior al entrenamiento (PTQ) y el entrenamiento consciente de la cuantificación (QAT), y QAT ofrece una mejor precisión del modelo mediante un ajuste fino. Implica el uso de cuantificadores falsos para hacer que la cuantificación sea compatible con la diferenciabilidad requerida para el ajuste fino.
La cuantización se puede definir como el proceso de mapear valores de un gran conjunto de números reales a valores de un pequeño conjunto discreto. Normalmente, esto implica asignar entradas continuas a valores fijos en la salida. Una forma común de lograrlo es redondeando o truncando. En caso de redondeo, calculamos el número entero más cercano. Por ejemplo, un valor de 1,8 se convierte en 2. Pero un valor de 1,2 se convierte en 1. En caso de truncamiento, eliminamos ciegamente los valores después del decimal para convertir la entrada en un número entero.
Motivación para la cuantización
Cualquiera que sea la forma en que procedamos, la principal motivación detrás de la cuantificación de redes neuronales profundas es mejorar la velocidad de inferencia, ya que no hace falta decir que la inferencia y el entrenamiento de redes neuronales son bastante costosos desde el punto de vista computacional. Con la llegada de los modelos de lenguaje grandes , la cantidad de parámetros en estos modelos solo aumenta, lo que significa que la huella de memoria es cada vez mayor.
Con la velocidad a la que están evolucionando estas redes neuronales, existe una demanda cada vez mayor para ejecutarlas en nuestras computadoras portátiles o teléfonos móviles e incluso en dispositivos pequeños como relojes. Nada de esto es posible sin la cuantización.
Antes de sumergirnos en la cuantización, no olvidemos que las Redes Neuronales entrenadas son meros números flotantes almacenados en la memoria del ordenador.
Algunas de las representaciones o formatos más conocidos para almacenar números en computadoras son float32 o FP32, float16 o FP16, int8, bfloat16 donde B significa Google Brain o, más recientemente, tensor float 32 o TF32, un formato especializado para manejar matrices o tensores. operaciones. Cada uno de estos formatos consume una porción diferente de la memoria. Por ejemplo, float32 asigna 1 bit para signo, 8 bits para exponente y 23 bits para mantisa.
De manera similar, float16 o FP16 asigna 1 bit para signo pero solo 5 bits para exponente y 10 bits para mantisa. Por otro lado, BF16 asigna 8 bits para el exponente y sólo 7 bits para la mantisa.
Cuantización en redes profundas
Basta de representaciones. Lo que quiero decir es que la conversión de un formato de memoria superior a un formato de memoria inferior se llama cuantización. Hablando en términos de aprendizaje profundo, Float32 se denomina precisión simple o total, y Float16 y BFloat16 se denominan precisión media . La forma predeterminada en la que se entrenan y almacenan los modelos de aprendizaje profundo es con total precisión. La conversión más utilizada es de precisión total a formato int8.
Tipos de cuantificación
La cuantificación puede ser uniforme o no uniforme . En el caso uniforme, el mapeo de la entrada a la salida es una función lineal que da como resultado salidas espaciadas uniformemente para entradas espaciadas uniformemente. En el caso no uniforme, el mapeo de la entrada a la salida es una función no lineal, por lo que las salidas no estarán espaciadas uniformemente para una entrada uniforme.
Profundizando en el tipo uniforme, la función de mapeo lineal puede ser una operación de escala y redondeo. Por tanto, la cuantificación uniforme implica un factor de escala, S en la ecuación.
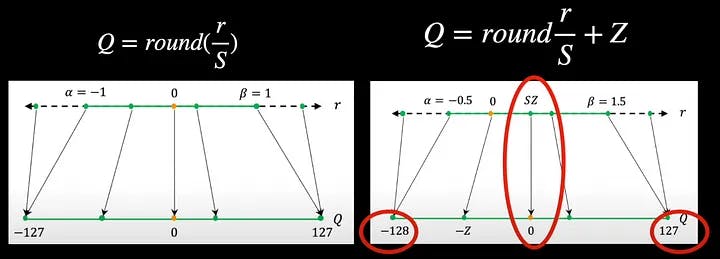
Al convertir de, digamos, float16 a int8, observe que siempre podemos restringirnos a valores entre -127 y más 127 y asegurarnos de que el cero de la entrada se asigne perfectamente al cero de la salida, lo que lleva a un mapeo simétrico y, por lo tanto, esta cuantificación se llama simétrica . cuantización .
Por otro lado, si los valores a ambos lados del cero no son iguales, por ejemplo entre -128 y +127. Además, si asignamos el cero de la entrada a algún otro valor distinto de cero en la salida, entonces se llama cuantificación asimétrica . Como ahora tenemos el valor cero desplazado en la salida, debemos contar esto en nuestra ecuación incluyendo el factor cero, Z , en la ecuación.
Elegir escala y factor cero
Para aprender cómo podemos elegir el factor de escala y el punto cero, tomemos una entrada de ejemplo distribuida como en la figura anterior en el eje de números reales. Básicamente, el factor de escala divide todo este rango de entrada desde el valor mínimo r_min hasta el valor máximo r_max en particiones uniformes. Sin embargo, podemos optar por recortar esta entrada en algún momento, digamos alfa para valores negativos y beta para valores positivos. Cualquier valor más allá de alfa y beta no es significativo porque se asigna a la misma salida que el de alfa. En este ejemplo, son -127 y +127. El proceso de elegir estos valores de recorte alfa y beta y, por tanto, el rango de recorte se denomina calibración .
Para evitar un recorte excesivo, la opción más sencilla podría ser configurar alfa para que sea igual a r_min y beta para que sea igual a r_max. Y felizmente podemos calcular el factor de escala S , usando estos valores r_min y r_max . Sin embargo, esto puede hacer que la salida sea asimétrica. Por ejemplo, r_max en la entrada podría ser 1,5 pero r_min solo podría ser -1,2. Entonces, para limitarnos a la cuantificación simétrica, necesitamos que alfa y beta sean los valores máximos de los dos y, por supuesto, establecer el punto cero en 0.
La cuantificación simétrica es exactamente lo que se utiliza al cuantificar los pesos de las redes neuronales, ya que los pesos entrenados ya se calculan previamente durante la inferencia y no cambiarán durante la inferencia. El cálculo también es más sencillo en comparación con el caso asimétrico, ya que el punto cero se establece en 0.
Ahora revisemos un ejemplo en el que las entradas están sesgadas en una dirección, digamos en el lado positivo. Esto se asemeja al resultado de algunas de las funciones de activación más exitosas como ReLU o GeLU. Además de eso, las salidas de las activaciones cambian con la entrada. Por ejemplo, el resultado de las funciones de activación es bastante diferente cuando mostramos dos imágenes de un gato. Entonces la pregunta ahora es: "¿Cuándo calibramos el rango para la cuantificación?" ¿Es durante el entrenamiento? ¿O durante la inferencia y cuando obtenemos los datos para la predicción?
Modos de cuantificación
Esta pregunta conduce a varios modos de cuantificación, particularmente en la cuantificación posterior al entrenamiento (PTQ). En PTQ, iniciamos con un modelo previamente entrenado sin realizar capacitación adicional. Los datos cruciales que se requieren del modelo involucran datos de calibración, que se utilizan para calcular el rango de recorte y, posteriormente, el factor de escala (S) y el punto cero (Z). Normalmente, estos datos de calibración se derivan de los pesos del modelo. Después del proceso de calibración, podemos proceder a cuantificar el modelo, dando como resultado el modelo cuantificado.
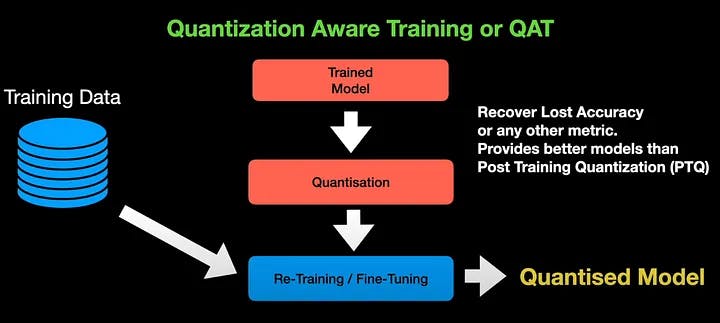
En Quantization Aware Training o QAT para abreviar, cuantificamos el modelo entrenado utilizando un procedimiento estándar, pero luego realizamos más ajustes o reentrenamiento, utilizando datos de entrenamiento nuevos para obtener el modelo cuantificado. El QAT generalmente se realiza para ajustar el parámetro del modelo con el fin de recuperar la precisión perdida o cualquier otra métrica que nos preocupe durante la cuantificación. Por tanto, QAT tiende a proporcionar mejores modelos que la cuantificación posterior al entrenamiento.
Para poder realizar un ajuste fino, el modelo debe ser diferenciable. Pero la operación de cuantificación no es diferenciable. Para superar esto, utilizamos cuantificadores falsos, como estimadores directos. Durante el ajuste fino, estos estimadores estiman el error de cuantificación y los errores se combinan junto con el error de entrenamiento para ajustar el modelo para un mejor rendimiento. Durante el ajuste fino, los pases hacia adelante y hacia atrás se realizan en el modelo cuantificado en punto flotante. Sin embargo, los parámetros se cuantifican después de cada actualización de gradiente.
Mire el vídeo a continuación que explica la cuantificación de modelos en el aprendizaje profundo.
Resumen
Eso cubre prácticamente los conceptos básicos de la cuantificación. Comenzamos con la necesidad de cuantificación y los diferentes tipos de cuantificación, como la simétrica y la asimétrica. También aprendimos rápidamente cómo podemos elegir los parámetros de cuantización, es decir, el factor de escala y el punto cero. Y terminamos con diferentes modos de cuantificación. Pero, ¿cómo se implementa todo en PyTorch o TensorFlow? Eso es para otro día. Espero que este video le haya brindado información sobre la cuantificación en el aprendizaje profundo.
Espero verte en mi próximo. ¡Hasta entonces, cuídense!
L O A D I N G
. . . comments & more!
. . . comments & more!



