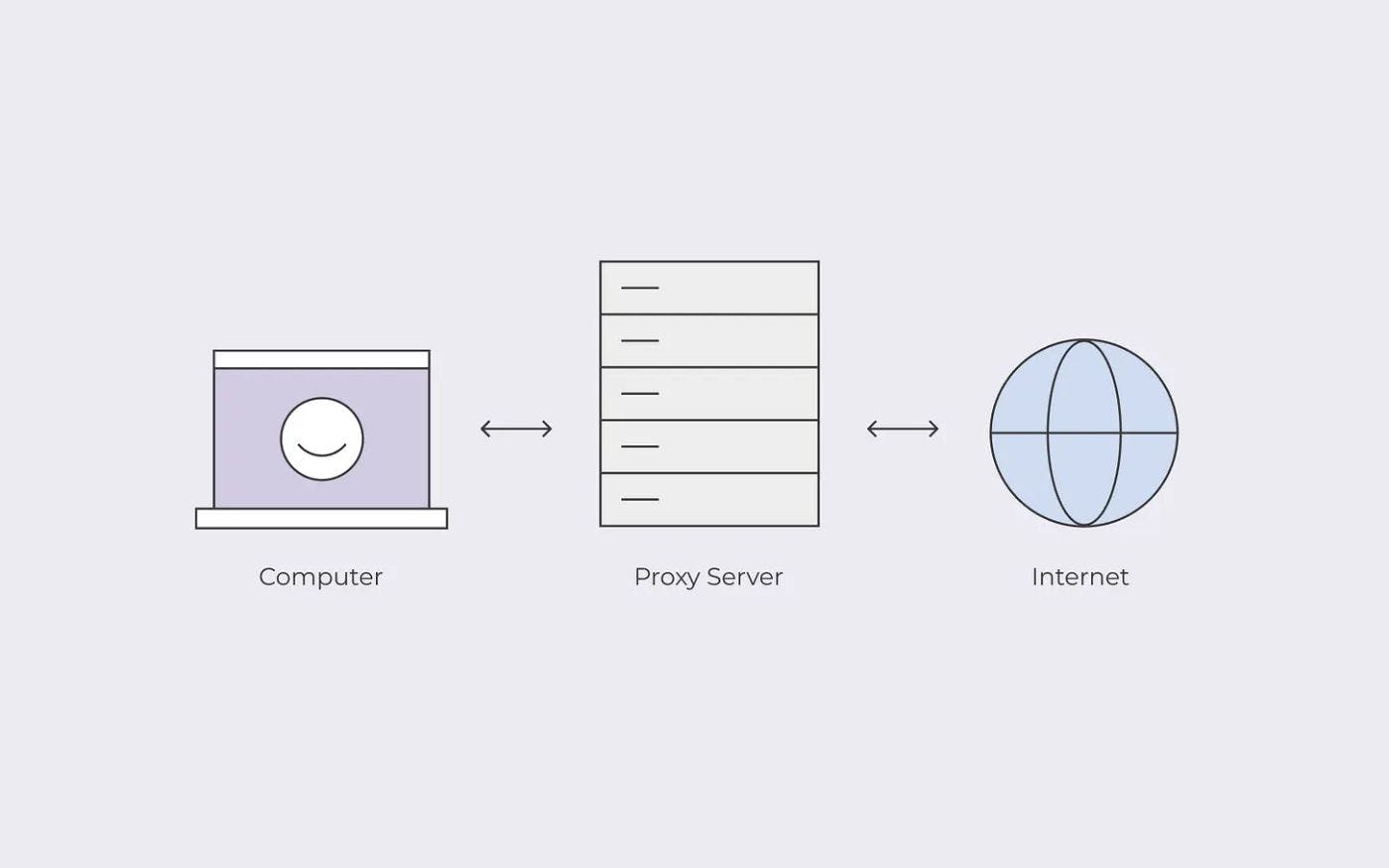
And why it is useful for web scraping? According to Wikipedia, "In computer networking, a is a server application that acts as an intermediary between a client requesting a resource and the server providing that resource". proxy server In other words, it is a server application that stands between you and your target server: you can send a request to the target server through the proxy server, so the machine that sends the request to the target server is the proxy and not your client. Why do we need proxies for web scraping? There are several ways proxies can be useful when scraping. The target website has a sort of geo-fencing, so it shows data depending on the location of the IP address. This is a common case and choosing a proxy with an address belonging to the country we need the data from is quite a common case. The target website limits the requests from the same IP, in this case, we'll need a pool of proxies or a rotating proxy to split the requests into several different IPs The target website uses anti-bot software that employs fingerprints to block traffic from servers. If our scraper is running in a cloud environment, we'll need a residential or mobile proxy to bypass it. The target website blocks all the requests coming from the IP range of our cloud provider. In this case, we'll need an Elite Proxy to mask the origin of the requests. Different types of proxies As we have seen in the examples before, proxies can be categorized using the feature we want to highlight. Usually, when comparing the different proxies vendors or when we find online a list of free proxies, the main features are anonymity, its location, and if it's static or rotating. Proxy anonymity Usually, this information is provided in the free online proxies lists, where the proxies are divided in: Transparents or No Anonymous. So-called because they do not change the starting request headers. On top, it adds the " header containing the origin IP and the "Via" header saying that a proxy is being used. X-Forwarded-For" Anonymous: Same as before but without the " header X-Forwarded-For" Highly Anonymous or Elite: it replicates the original headers without adding anything. Proxy location Every IP can be traced back to a country of provenience, so as e-commerce websites can geo-fence any IP, also proxy providers usually sell proxies located in the main countries of the world. On top, the most important players in the field allow their customers to choose the final location of the proxies, like a data center, a mobile phone, or a residential IP. s are the most common and cheap but also they are likely to get banned from websites that use strong fingerprinting techniques to block bots or IPS that are in a well-known range of data center addresses. I made a test, setting up a Highly Anonymous Proxy on an Ec2 AWS instance and this is the result of the IP API. Data center IP As you can see, combining data from several sources and public registries, it can be easily detected that the request is coming from an EC2 instance. The TCP-IP Fingerprint test also gives interesting results. These are the results when browsing from my Mac without using proxies. It can be detected with a fair degree of certainty that I'm using a Mac Os operating system and this is because every operating system uses different values inside the TCP Handshake packet sent when establishing a connection with a server. In fact, when turning on the proxy on my Unix server, the results of the test change, and, with such an uptime value, it's a red flag signaling that the request is coming from a server and not a personal client. To mimic a more realistic real user sending requests to a website, the most important proxy providers give the option to use proxies with residentials IP, so installed outside data centers, or mobile proxies. Of course, due to scarcity and the cost of the bandwidth, these options are more expensive than the data center's one. Static Vs Rotating Using a static proxy means that your requests will be made all from the same IP of the proxy. This doesn't help in case the website limits the number of requests per IP in a certain timeframe. The solution is a rotating proxy: it means that you set up your scraper as if you're using only one proxy but, in the background, every request sent to its address is routed to a pool of proxies. The target website will see these requests coming from different IPs and machines and will not trigger any block. Where to find the right proxy for me? There ain't no such thing as a free lunch, even in this field. For a list of free proxies, you can have a look but tendentially they are unreliable and slow. here If you're willing to pay for proxies, there are many actors in this industry, the most famous are: Zyte Bright data Oxylabs Smartproxy Scrape.do Key Takeaways Sooner or later, you'll need to use proxies, as more and more websites are becoming harder to scrape. Choosing the right one depends from website to website, there's no silver bullet (or maybe yes but it's too expensive). Also published here.



















![[ Expressjs ] Cracking nuts, put the client IPs to BlackList](https://hackernoon.imgix.net/fallback-feat.png?auto=format&fit=max&w=3840)





