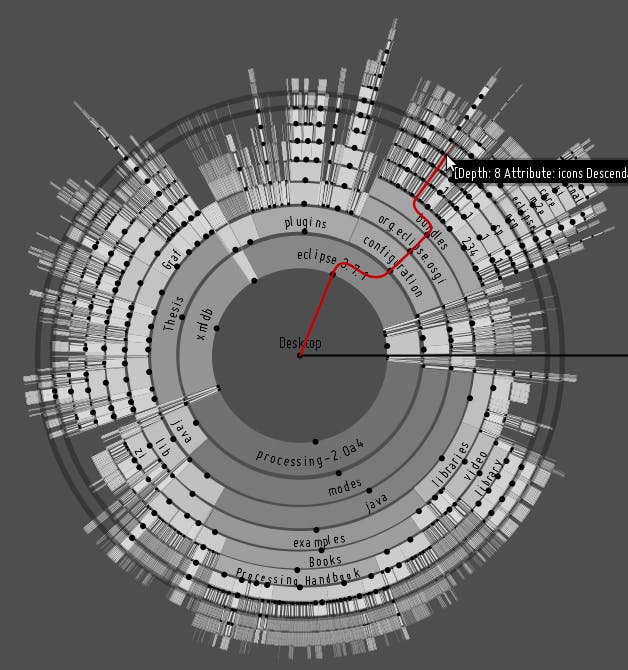
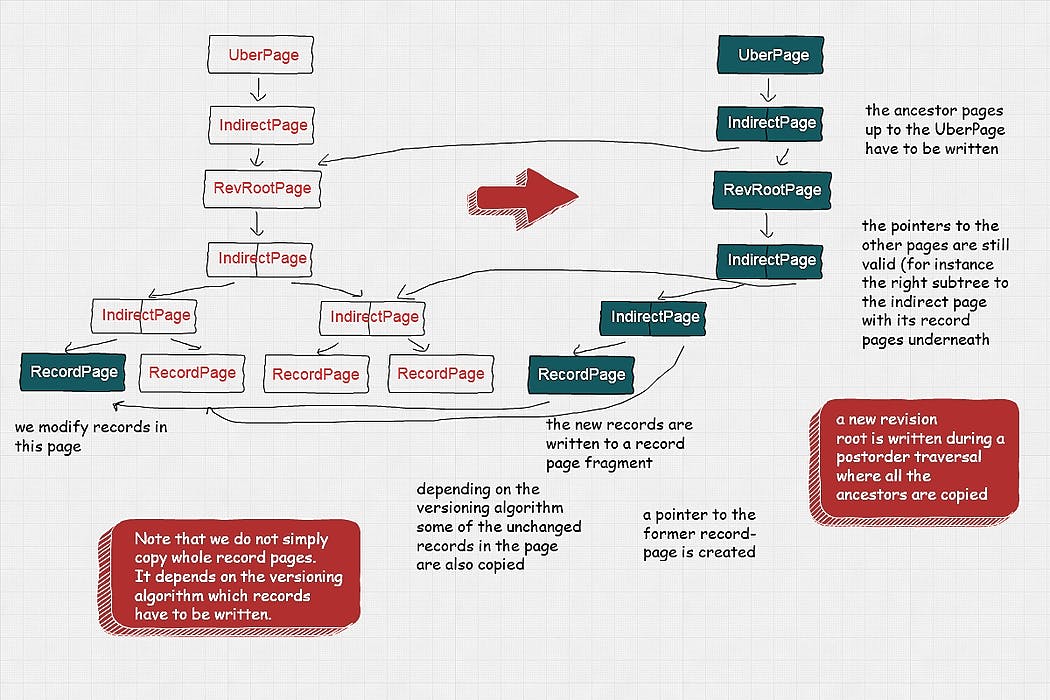
As most current database systems still simply store current state or past states within one big relational table, we investigated what the performance drivers are and how to improve on the current state-of-the-art. We implemented an Open Source storage system called Sirix(.io) from scratch, which stores small sized snapshots as well as supports sophisticated time-travel queries, while competing with the efficiency of non-temporal database systems. What is a temporal database system? It is a term used to describe, that a system is capable of retrieving past states of your data. Typically a temporal database stores both , how long a fact is true in the real world as well as , when the data actually is committed to the database. valid time transaction time Questions such as: Give me last month’s history of the Dollar-Pound Euro exchange rate. What was the customers address on July 12th in 2015 as it was recorded in the day? Did they move or did we correct an error? Did we have errors in the database, which were corrected later on? Let’s turn or focus to the question why historical data hasn’t been retained in the past and how new storage advances in recent years made it possible, to build sophisticated solutions to help answer these questions without the hurdle, state-of-the-art systems bring. Advantages and disadvantages of flash drives as for instance SSDs As Marc Kramis points out in his paper “ ”: Growing Persistent Trees into the 21st Century The switch to flash drives keenly motivates to shift from the “current state’’ paradigm towards remembering the evolutionary steps leading to this state. The main insight is that flash drives as for instance SSDs, which are common nowadays have zero seek time while not being able to do in-place modifications of the data. Flash drives are organized into pages and blocks, whereas blocks Due to their characteristics they are able to read data on a fine-granular page-level, but can only erase data at the coarser block-level. Blocks first have to be erased, before they can be updated. Thus, updated data first is written to another place. A garbage collector marks the data, which has been rewritten to the new place as erased, such that new data can be stored in the future. Furthermore index-structures are updated. Evolution of state through fine grained modifications Furthermore Marc points out, that small modifications, because of clustering requirements due to slow random reads of traditionally mechanical disk head seek times, usually involves writing not only the modified data, but also all other records in the modified page as well as a number of pages with unmodified data. This clearly is an undesired effect. How we built an Open Source storage system based on these observations from scratch Sirix stores per revision and per page-deltas. Due to zero seek time of flash drives we do not have to cluster data. Sirix only ever clusters data during transaction commits. It is based on an append-only storage. Data is never modified in-place. Instead, it is copied and appended to a file in a post-order traversal of the internal tree-structure in batches once a transaction commits. We borrowed ideas from the filesystem as for instance checksums stored in parent database-pages/page-fragments, which forms a self-validating merkle-tree as well as our internal tree-structure of databases-pages. ZFS In stark contrast to other (COW) approaches, however we do not simply copy the whole record-page, which is a waste of storage space. Depending on the used versioning algorithm we only copy a number of records from the page (everytime the changed records itself). copy-on-write Versioning algorithms for storing and retrieving record-level snapshots As most database system we store at most a fixed number of records, that is the actual data per database-page (currently 512 records at most). The records themselves are of variable size. Overlong records, which exceed a predefined length in bytes are stored in additional overflow pages and only referenced in the record-pages. We implemented a number of versioning strategies best known from backup systems for copy-on-write operations of record-pages. Namely we either copy the full record-pages, that is any record in the page ( ) full only the changed records in a record-page regarding the former version ( ) incremental only the changed records in a record-page since a full page dump ( ) differential It is well known, that each of these versioning strategies has its advantages and drawbacks. Simply storing the whole page ( is very efficient for reading-operations. However write performance in comparison to all other approaches is the worst, as we simply copy all unchanged records in addition to all changed records. full) -versioning is the other extreme and write-performance is best, as it stores the optimum (only changed records), but on the other hand reconstructing a page needs intermittent full snapshots of pages, such that the performance doesn’t deteriorate with each new revision of the page as the number of increments increases with each new version. Incremental -versioning tries to balance reads and writes a bit better, but is still not optimal. Each time records in a page are modified a new page is written, with all changed records since a past full dump of the page. This means that only ever two revisions of the page-fragment have to be read to reconstruct a record-page. However write-performance also deteriorates with each new revision of the page. Differential The screenshot depicts an (Interactive) Visualization of moved subtrees in Sirix throug hierarchical edge bundles versioning in regards to write performance, due to the requirement of intermittent full dumps of the page results in write-peaks. versioning also suffers from a similar problem. Without an intermittent full dump a lot of data would have to be duplicated on each new write. Incremental Differential Marc Kramis came up with the idea of a novel sliding snapshot algorithm, which balances read/write-performance to circumvent any write-peaks. The algorithm makes use of a sliding windows. First, any changed record must be stored, second any record, which is older than a predefined length of the window and which has not been changed during these -revisions. Only these -revisions at max have to be read. The fetching of the page-fragments could be done in parallel or we simply stop once the full-page has been reconstructed starting with the most recent revision. N N N Once we made sure our storage system scaled linear for fetching old-revisions as well as the most recent revision and logarithmic for fetching and storing single records as well as whole revisions we focused our attention to upper layers. DOM alike API We then invested a lot of work to implement a persistent DOM-interface (for instance to store XML-documents and in the future JSON-documents natively). Our records are stored with stable identifiers, which never change, regardless of the fact if the records are updated or not and where they physically reside. Markers are inserted for deleted records. The encoding is simply first-child-, left-sibling-, right-sibling-, parent- and node-ID in order to store a kind of DOM representation of currently XML/XDM-nodes. Versioned, typed, user-defined indexes We then shifted our focus again to implement versioned user-defined, index-structures. During each transaction commit a snapshot not only of the stored data, but also of the indexes is generated. The indexes currently are based on AVL-trees/AVL-nodes stored in record-pages in different subtrees of our internal ZFS alike tree-structure. A path summary of all paths in the resource is kept up-to-date at all times. To enable users to make the most of our temporal database system and to actually easily answer the aforementioned questions one would likely be able to get answered by a temporal database system we extended a query-compiler called Brackit. Users are now able to open specific revisions, navigate in the DOM-alike tree-structure to select nodes in a specific revision and then navigate in time. Through novel time-based axis it is for instance easily possible to analyse how the selected or a sequence of records/the nodes looks like in the next revision, the previous revision, the first or the last revision, the past- or future-revisions, all-revisions… Furthermore we are able to query a range of revisions either based on given timestamps or the IDs of the revisions. But what if we want to import several revisions of preexisting documents or compare any revision stored in our system independent of the versioning algorithm we chose? Diff-algorithms FMSE diff-algorithm We first implemented a diff-algorithm called (FMSE) to support the import of different versions of a document and commit several revision in our storage system. The algorithm does not rely on node-identifiers. It matches based on similarities of subtrees through first calculating a (LCF) on the leaf nodes of the tree-structured document to import (currently XML, in the future also JSON). Then it tries to match way bottom up. In the next step edit-operations are applied to transform the document from one version to another version. The algorithm obviously uses heuristics at a form of the tree-to-tree correction problem and thus NP-hard. It works best and produces a minimal edit-script if the leaf nodes are very distinctive. fast-matching-simple-editscript Longest Common Subsequence ID-based algorithm optionally making use of stored hashes In order to compute diffs between any revision of Sirix-resources and regardless of the record-page level versioning we developed an algorithm, which makes use of our stable record-identifiers (which is a based on a sequence generator, which never reassigns IDs (from deleted records for instance). If we store hashes of the nodes during insertion the diff algorithm is able to skip whole-subtrees if the node-identifiers as well as the hashes match. Depicts how the ID-based diff algorithm works Non blocking, asynchronous RESTful API We recently built, on top of our XQuery and DOM-API layers a higher level API to communicate with a Sirix server based on Vert.x, Kotlin/Coroutines and Keycloak for authentication. The implementation and usage examples thereof already was the subject of another . article A Visual Analytics Approach for Comparing Tree-Structures As shown in a few screenshot we once developed a Visual Analytics approach to compare tree-structures stored in Sirix. However, it’s a bit dated and needs to be ported to the web. What we are working on Next, we’ll investigate how to best store JSON-documents, which simply boils down to the question of how fine-granular we want our records to be (for instance object record nodes, array-index nodes…) However, we would be more than happy to discuss future directions and ideas. Any help is greatly appreciated. If you like this, please give us some claps so more people see it or a star on Github… and most importantly check it out ( ) :-) we would love to hear any suggestions, feedback, suggestions for future work, as for instance work on JSON or horizontal scaling in the cloud, bug reports ;-), just everything… please get in contact Our Open Source repository: http://sirix.io