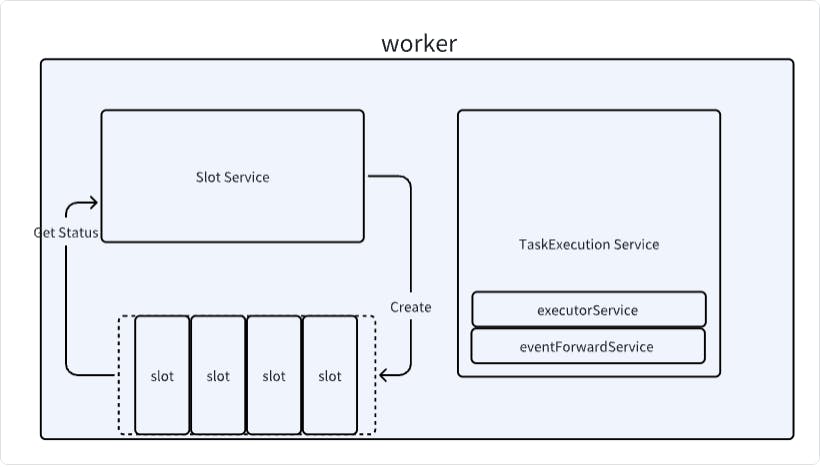
I started seeing chatter about in early 2023 and was low-key keeping an eye on it. The project started in 2017 as Waterdrop and grew out of the contributions from the creator of which supports SeaTunnel as a task plugin. Apache SeaTunnel Apache Dolphin, I had some initial issues getting my head around what SeaTunnel is and why I should care about it. That means I will keep this relatively high level to at least answer those questions. With that, let’s jump in. What is SeaTunnel? They describe it as “a high-performance, distributed, massive data integration tool that provides an all-in-one solution for heterogeneous data integration and data synchronization.” It comprises three main components: Source connectors Transform connectors Sink connectors. Many source connectors are available; as of the current version, 2.3.3, a list is available . It includes formats such as relational, , and graph, as well as distributed file systems like HDFS and object stores like S3. here NoSQL A transform connector comes into play if the schema between your source and sink differ, essentially mapping your data. The sink is the other side of the source, but now you are writing instead of reading. A complete list of sink connectors as of version 2.3.3 is available . As of this writing, it is claimed that over 100 connectors currently exist. here With these components, SeaTunnel can solve common problems found with data integration and synchronization. So, it provides high-performance data synchronization for real-time and batch data. The poorly translated claim in the docs is that it can “synchronize hundreds of billions of data per day in real-time.” I’m not sure what that claim is, but it's probably pretty fast, considering that companies like Alibaba use it. Apache SeaTunnel Features I was impressed with the connector API feature in the system. As stated earlier, over 100 pre-built connectors exist, but you can create a different one if you need to. The connectors are not tied to a specific execution engine but can use Flink, Spark, or the native SeaTunnel one. The plug-in architecture for the connectors reminds me a bit of the . Trino ecosystem Data can be synchronized in batch or real-time, providing various synchronization options. A nifty feature is how it works with JDBC, which supports multi-table or whole database synchronization. This addresses the need for CDC multi-table synchronization scenarios. The runtime process of SeaTunnel is shown in the diagram below: The SeaTunnel runtime flow breaks down as follows: Configure the job information and select the execution engine. The source connector reads the data in parallel and passes it downstream to transform, sink, or directly to the sink. Keep in mind that SeaTunnel is an EL(T) integration platform, as such, it can only do basic data transformations itself: Change the case of data in a column Change a column name Split a column into multiple columns SeaTunnel Jobs A SeaTunnel job, or config file, is described with four possible sections: env, source, transform, and sink. The transform can be ignored if no transformation is performed. A config file can be written in or format. Borrowing from the SeaTunnel docs, here is a simple example in format: Hocon JSON hocon env { job.mode = "BATCH" } source { FakeSource { result_table_name = "fake" row.num = 100 schema = { fields { name = "string" age = "int" card = "int" } } } } transform { Filter { source_table_name = "fake" result_table_name = "fake1" fields = [name, card] } } sink { Clickhouse { host = "clickhouse:8123" database = "default" table = "seatunnel_console" fields = ["name", "card"] username = "default" password = "" source_table_name = "fake1" } } While the format is very easy to read and understand, I could see it getting pretty gnarly with large tables. I’ll comment here that, like many open-source projects, the docs are rather lacking, but the project seems to have a pretty active channel based on the time I’ve been in there. Slack SeaTunnel Requirements It’s a Java system, and they say that version 8 or 11 is required but should work with older systems. If you already have Java installed, then you just need to get the plugins you want from their site (or write your own) and set them up in their config file. After that, you create the config file that will manage the job as we described. It’s all pretty straightforward as long as you have the credentials to access your source and destination data repositories. The console will give feedback on what is happening. A is also available for those who want an alternative to the CLI, and that would be my personal preference for using the system, it’s much easier to get visibility, but it also has a lot more steps to install and use it. web interface Summary SeaTunnel is undoubtedly only for some; it comes into play when dealing with lots of data across various data sources and destinations, as I currently see it. I can certainly see situations where it would simplify things, so I’ll keep this project in my bag of tricks. The SeaTunnel folks have this good quick-start guide available , making it simple to give it a try yourself and see how well it can solve your problems. here You can read the other “What the heck” articles at these links: (I was pretty out front on this one.) What The Heck Is DuckDB? (I was out front on this one, too.) What the Heck Is Malloy? (slower, but also growing) What the Heck is PRQL? (growing quickly) What the Heck is GlareDB?