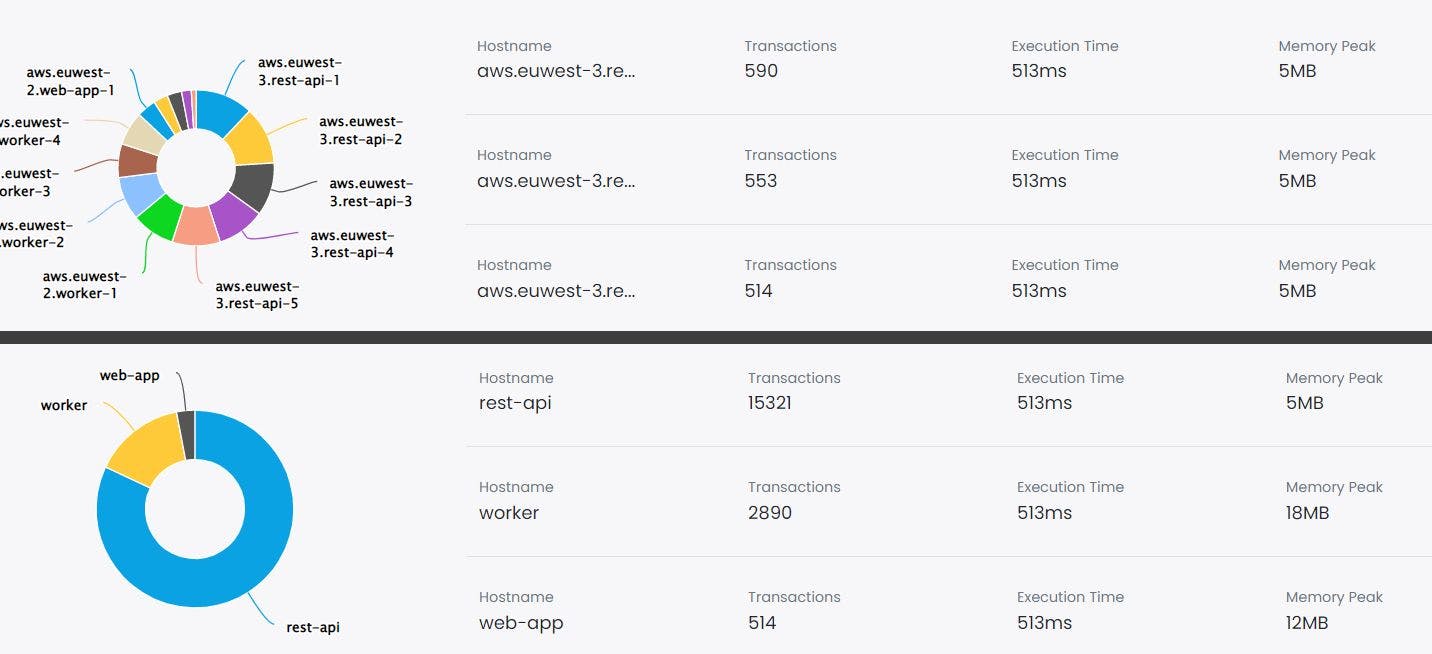
716 reads
Using Kubernetes and Containers for Infinite Scaling
by byDenilson Nastacio@dnastacio
byDenilson Nastacio@dnastacio
Operations architect, corporate observer, software engineer, inventor. @dnastacio
November 14th, 2022





Audio Presented by
Operations architect, corporate observer, software engineer, inventor. @dnastacio


Operations architect, corporate observer, software engineer, inventor. @dnastacio
About Author
Operations architect, corporate observer, software engineer, inventor. @dnastacio
Comments