9,375 reads
(tutorial 3)What is seq2seq for text summarization and why





Too Long; Didn't Read
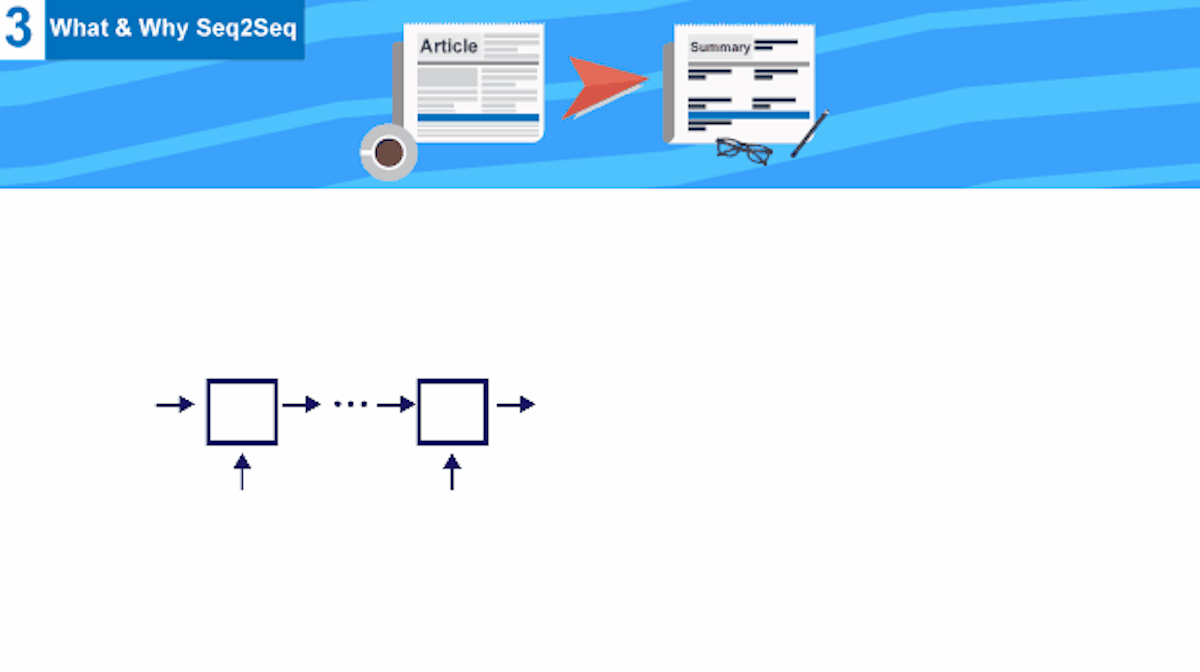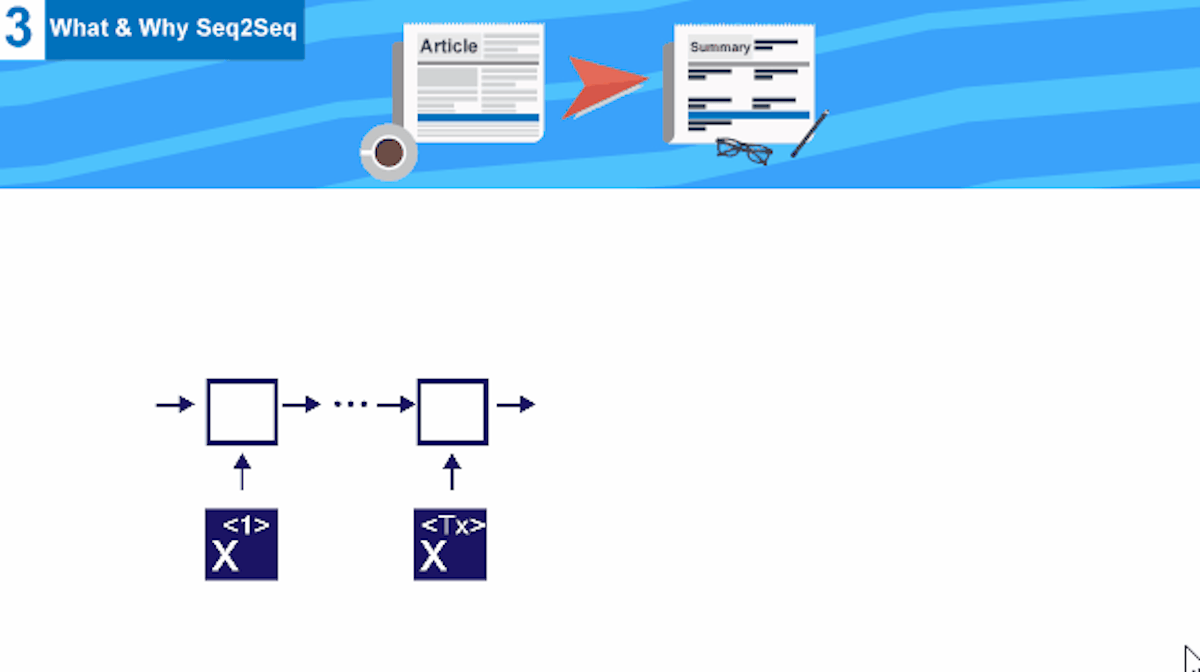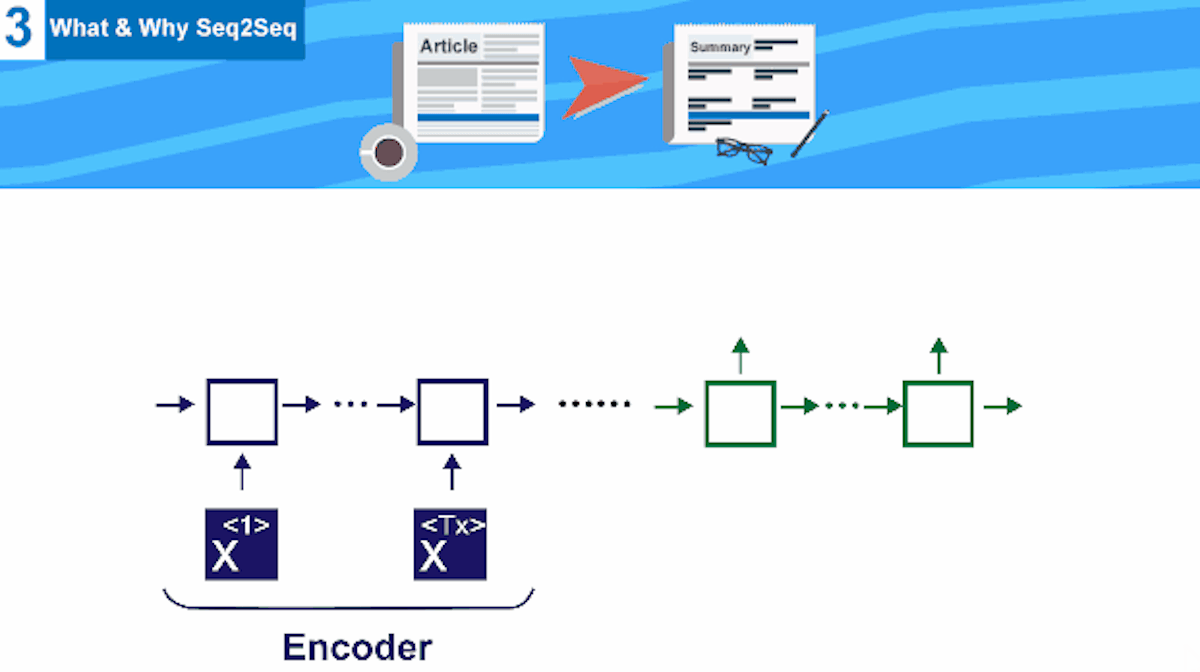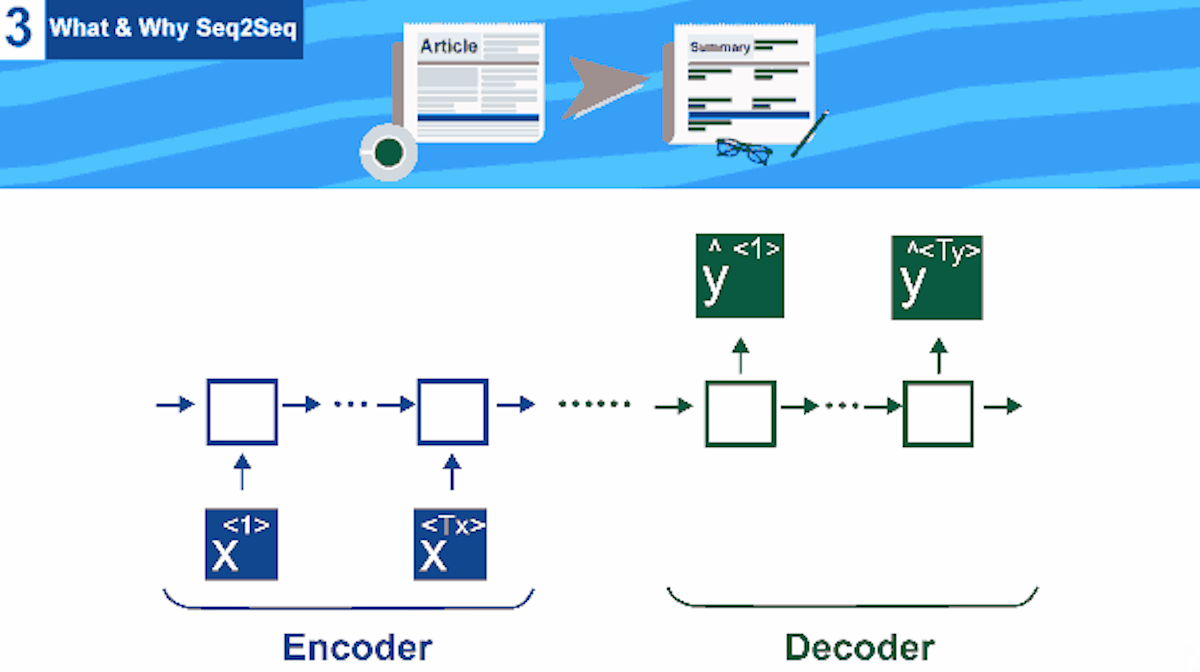
This tutorial is the third one from a series of tutorials that would help you build an abstractive text summarizer using tensorflow , today we would discuss the main building block for the text summarization task , begining from RNN why we use it and not just a normal neural network , till finally reaching seq2seq modelCompany Mentioned



amr zaki
@theamrzaki

L O A D I N G
. . . comments & more!
. . . comments & more!