2,369 reads
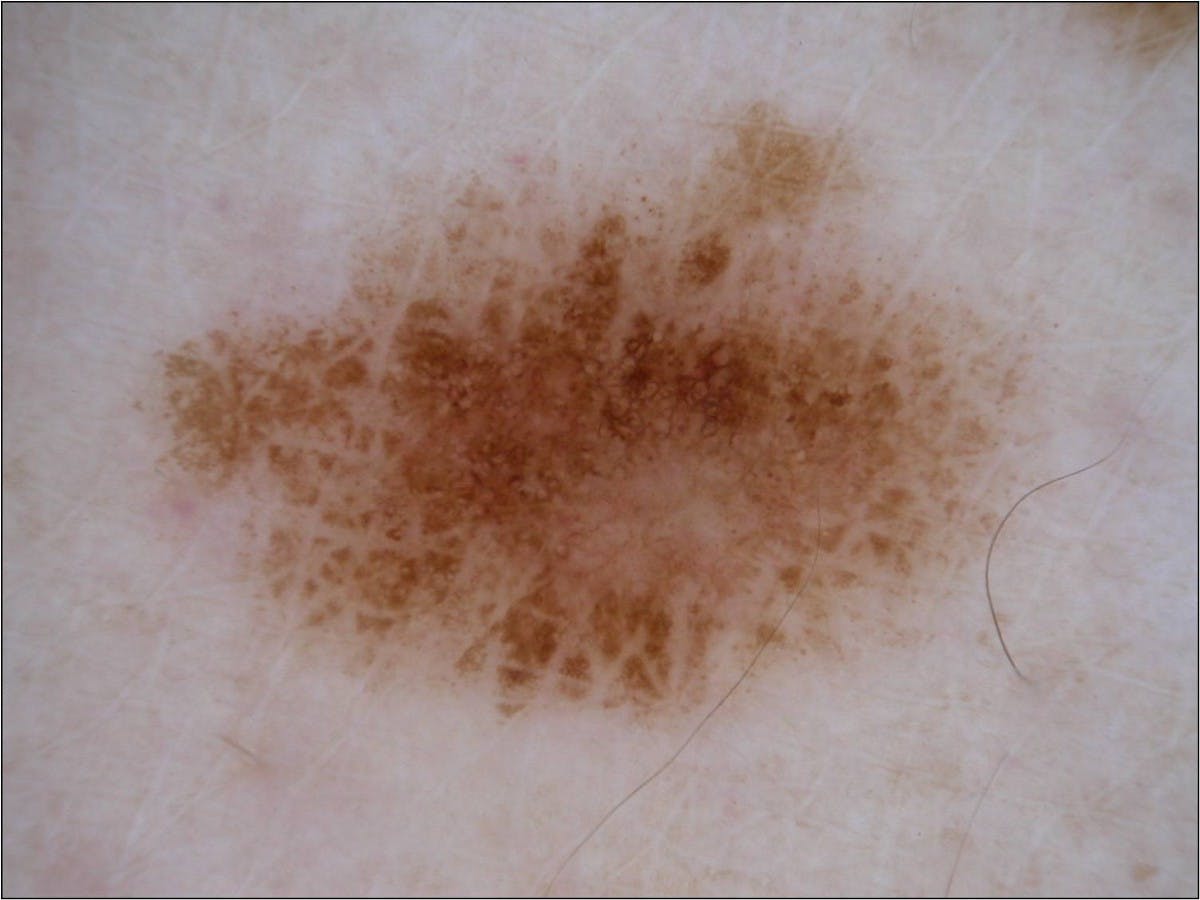
Machine Learning for the ISIC Cancer Classification Challenge #2: Deep learning on AWS
by byEvan Kozliner@evankozliner
byEvan Kozliner@evankozliner
Founder building https://withpotions.com - we will write your newsletter for you 🗞️
April 8th, 2018






Founder building https://withpotions.com - we will write your newsletter for you 🗞️


Founder building https://withpotions.com - we will write your newsletter for you 🗞️
About Author

Founder building https://withpotions.com - we will write your newsletter for you 🗞️
Comments