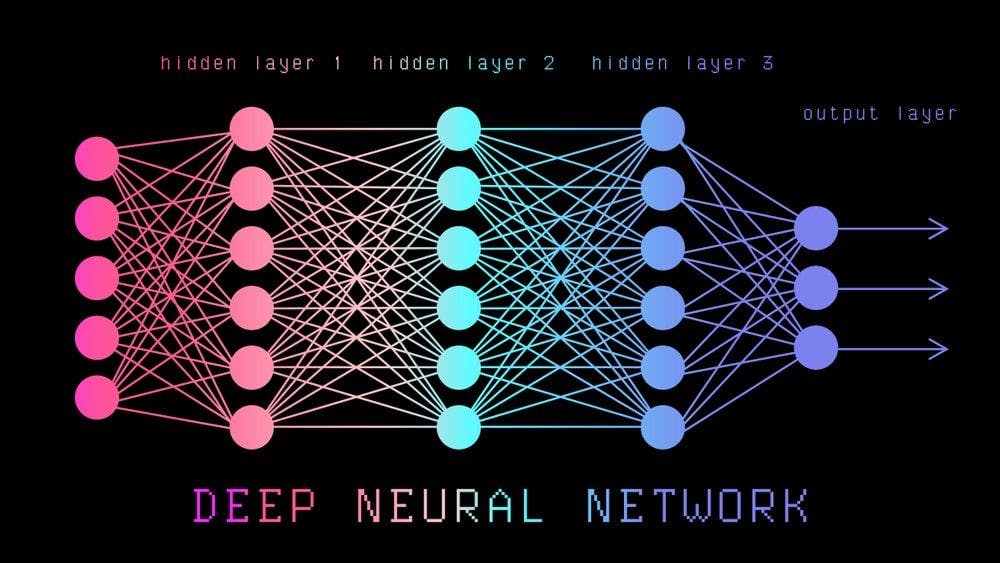
I’m going to describe a complete pipeline for problem posed in “Self-Driving Cars Engineer”. Traffic Sign Recognition is a basic, day by day task for self-driving cars. That’s why it has to be covered in the where I present different projects related to this field. The recognition system processes a traffic sign image extracted from the road scene. Eventually, it should classify that sign into one of 43 categories. In order to make it happen, a is applied, being trained with 50.000 images beforehand. Traffic Sign Recognition Udacity course series about Self-Driving Cars Convolutional Neural Network Goals of the project The goal of the Traffic Sign Recognition project is to build a (DNN) which is used to classify traffic signs. We should train the model so it can decode traffic signs from natural images using the . This data should be firstly preprocessed in order to maximize the model performance. After choosing model architecture, fine tuning and training, the model will be tested on new images of traffic signs found on the web. Because we deal with images classification, a Convolutional Neural Network is chosen as a type of DNN, which is a common choice for this type of problems. The code is written in with use of library. It’s great for making quick, high-level changes in our model architecture. In addition, TensorFlow supports computation on GPU which can really speed up required calculations. Finally, to make all calculations, I launched Amazon Web Services EC2 GPU instance to have bigger advantage over my laptop capabilities. Deep Neural Network German Traffic Sign Dataset Python TensorFlow Project pipeline My pipeline consists of 7 steps, which are quite common in classification problems: Loading the data Dataset exploration and visualization Data preprocessing Data augmentation Designing, training and testing a CNN model Using the model on new images Analyzing softmax probabilities You can find a complete code for the project on github . It is presented in a convenient way using Jupyter Notebook where immediate results are showed after each code block. Dataset The dataset is divided into training set (34.799 samples), validation set (4.410 samples) and test set (12.630 samples). Each sample represents a traffic sign labeled as one of 43 classes. It can be e.g. a stop sign, yield, 30 km/h speed limit etc. The shape of a traffic sign image is scaled to 32x32 pixels in 3 channel RGB representation (32x32x3). Below, there are a few random samples from the dataset: We should firstly explore the dataset, understand it against the problem to solve. Let’s see how many samples we have here for each traffic sign class. We wouldn’t like the model to be biased towards any of the class. Below, there is a histogram of sample occurrences in the training set for each label. Right now, we can see that some labels are greatly underrepresented while others have quite many representatives in the dataset. Should we dismiss the latter ones to equalize the histogram? Let’s draw firstly the subset of images which are belonging to the same class. We can observe that images from the same class can be represented quite differently in the dataset. Generally, there can be different , image can be , or . Indeed, these are samples which are extracted from real world images. And our model have to handle all of these conditions. So, it’s probably better not to truncate our dataset in order to obtain data balance. Let’s “produce” some new samples instead, mostly for underrepresented signs. lighting conditions blurred rotated scaled Data preprocessing To generate so-called I randomly chose images to copy. To provide additional information to the model, I randomly rotated this copy and changed its brightness. For all these operations library was used. I performed these operations until each label had 3200 samples. This increased the training set to 139.148 samples. As an illustration, here’s a drawing of a sample traffic sign with generated images (rotated and different brightness). augmented data OpenCV Next, I decided to convert the images from RGB to grayscale. As a consequence, we have 3 times less of the data to process which strongly influences on the training time. In addition, in the dealing with Traffic Sign Recognition as well, the authors discover that rejecting color information can even boost the final result. To experiment, at an early stage of my model architecture, I trained the model for 20 epochs using RGB, YUV color spaces and gray-scaled images. Likewise, the latest variation ended up with the best results. Finally, I also normalized the image data so that each pixel lies between -1 and 1. It prevents from numerical instabilities which can occur when the data resides far away from zero value. paper Here is an example of a traffic sign image before and after grayscale and normalization. Histograms of both images are depicted as well. Designing a Deep Neural Network model Now, it’s finally time to feed the data to the neural network. Choosing the architecture, tuning different parameters again and again is probably the most demanding task. There are no clear rules for the model optimization. Besides some proven rule of thumbs, our experience often plays a big role. Furthermore, when dealing with deep neural networks you have to wait for the results of each tested model a relatively long time. Of course, it depends on the available processing power. For this project I used with Nvidia GPU inside, which increased the speed about 6 times comparing to results obtained on my laptop running on i7 CPU core. network AWS EC2 instance To give a brief overview of the model complexity, I will name the most important model parameters. As this is a general look into the Traffic Sign Recognition project, I’m not going to explain them in details. These parameters, called sometimes “hyperparameters” are: , , , rate or pooling type. They are often discussed and benchmarked by researchers. However, the choice of type and model structure itself is equally significant. Convolutional Neural Network, introduced very nicely , fits very well for our task. But there are many well-established sub-types of CNN like (1990s), (2012), (2014) or (2014). They are differing with number of neuron layers (model depth), connections between them, number of operations or parameters which are updated on each iteration. A good comparison of the most popular architectures can be found . batch size, number of epochs learning rate loss regularization dropout here LeNet AlexNet GoogLeNet VGGNet here Convolutional Neural Network Let’s discuss briefly the concept of convolutional neural networks. They are very successful in image recognition. The key part to understand, which distinguishes CNN from traditional neural networks, is the operation. Having an image at the input, CNN scans it many times to look for certain . This scanning (convolution) can be set with 2 main parameters: stride and padding type. As we see on below picture, process of the first convolution gives us a set of new frames, shown here in the second column (layer). Each frame contains an information about one feature and its presence in scanned image. Resulting frame will have larger values in places where a feature is strongly visible and lower values where there are no or little such features. Afterwards, the process is repeated for each of obtained frames for a chosen number of times. In this project I chose a classic model which contains only two convolution layers. convolution features LeNet from https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/ The latter layer we are convolving, the more high-level features are being searched. It works similarly to human perception. To give an example, below is a very descriptive picture with features which are searched on different CNN layers. As you can see, the application of this model is face recognition. You may ask how the model knows which features to seek. If you construct the CNN from the beginning, searched features are random. Then, during training process, weights between neurons are being adjusted and slowly CNN starts to find such features which enable to meet predefined goal, i.e. to recognize successfully images from the training set. from from: https://devblogs.nvidia.com/parallelforall/deep-learning-nutshell-core-concepts/ Between described layers there are also (sub-sampling) operations which reduce dimensions of resulted frames. Furthermore, after each convolution we apply a non-linear function (called ) to the resulted frame to introduce non-linearity to the model. pooling ReLU Eventually, there are also at the end of the network. The last set of frames obtained from convolutional operations is flattened to get a one-dimensional vector of neurons. From this point we put a standard, fully-connected neural network. At the very end, for classification problems, there is a layer. It transforms results of the model to probabilities of a correct guess of each class, here a traffic sign index. fully connected layers softmax Below, there is a summary of the model I chose and fine tuned with marked dimensions for each layer. Tuning the model I followed a simple, iterative process of finding the best model architecture. After changing one of the model parameters, I ran only 20 epochs of the training and observed the validation error trying to set it on minimum level. It is very important to consider mainly validation error while tuning the model. Minimizing only the error based on training data can easily lead to unwanted model . overfitting Below, there are details of intermediate steps that I took and the corresponding validation accuracies after 20 epochs of training. Sometimes the differences between two given approaches seemed to be huge and it was hard to make a choice between them. But note that for each training procedure there is a random weight initialization which influences the final error. Especially when number of epochs is small. That’s why during final model tuning I used more than 20 epochs — about 100. Initial LeNet model, choosing input images color representation — 91 % Input images normalization — ~91 % Training set augmantation — 93 % Learn rate optimization, from this stage I tested for 100 epochs — 95 % Finding optimum image transformations during training set augmentation — 96 % Trying different pool methods, trying dropout, choosing L2 loss, tuning learn rate again — 96.8 My were as follows: final model results Training set accuracy of 99.5 % Validation set accuracy of 96.8 % Test set accuracy of 94.6 % I am quite satisfied with these results. Authors of the earlier referenced (Sermanet and LeCun) reach the level of accuracy equal to 99.17%. It is considered as being above human performance which is 98.81% ! paper Testing the model on new images Finally, we would like to test our Traffic Sign Recognition system on completely unseen sign images. Surely, the accuracy obtained on the test set is also a very good indication of the model performance. But let’s find some new images which are not from our German Traffic Sign Dataset. Under images, there are model predictions, indication if the prediction is correct and model certainty. We can see that the results are really good. I also collected images from Polish roads in Gdansk and extracted some traffic signs to test my model. The results are far worse although I chose signs which are identical to German ones. One exception is a Yield sign which is yellow instead of white. So, here a positive surprise that the model predicted correctly. Unfortunately, there are two signs which are not recognized at all. So far I didn’t make more research why this happened. Conclusions I successfully implemented a Convolutional Neural Network to the Traffic Sign Recognition task. It was done using an open-source Tensorflow library for Python. I chose a popular and simple LeNet CNN architecture. I see the biggest room for improvement here. Many modern Deep systems use more recent and more complicated architectures like GoogLeNet or ResNet. This comes in more computational cost, on the other hand. you can find a brief, illustrative comparison of the most popular architectures. The most difficult part of the project was to fine tune a CNN model parameters. It was sometimes cumbersome as I was not sure in which direction I should go. But this is the art of Machine Learning. I researched similar projects and tried to bring some ideas into my model. The interesting part was also data augmentation with image rotation and changing brightness which was also advised by many people doing this project. Learning Here More details and the complete code can be found on . github Originally published at ProggBlogg .