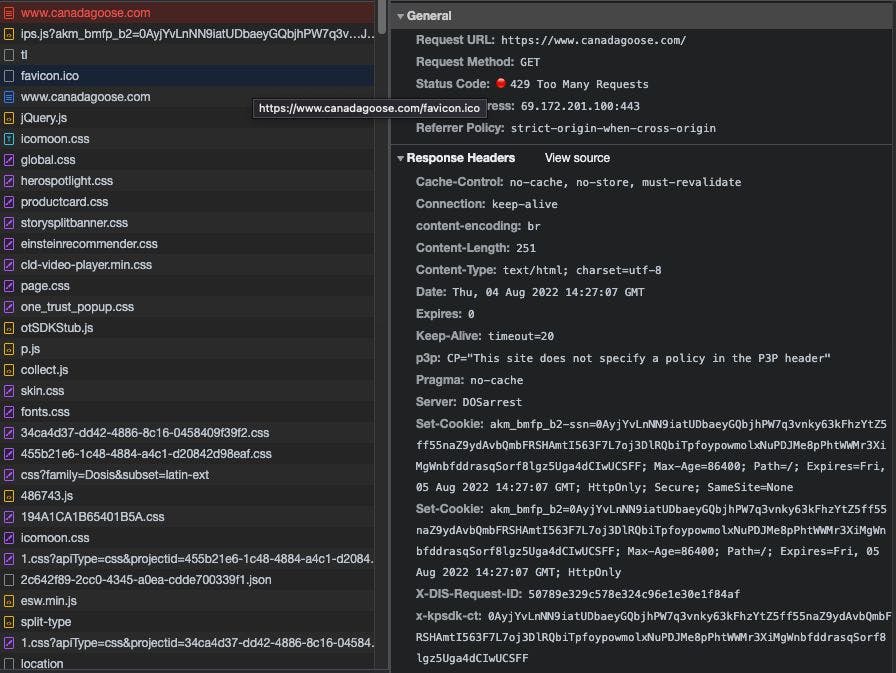
At , we said over and over that web scraping is getting more complex. Anti-bot software requires more advanced solutions, leading to higher computing and memory costs. The Web Scraping Club There’s also a less visible cost, which is the complexity of the web scraping infrastructure: since there's no silver bullet or magic solution that fits every case, the modern web scraper needs a full array of tools in his belt to tackle different cases. In this post, we’ll see some of the tools I’m using daily to tackle the most common anti-bot solutions and how, through a quick test, they behave against them. The Chosen Tools As a python developer, basically my potential toolset of headful browsers is restricted to: Selenium Undetected Chromedriver Playwright (in different sauces) Pyppeteer + stealth And that’s the reason why you won’t find puppeteer or cheerio in the following tests. Selenium Given that, you won’t find Selenium: in my opinion, it has lost some appeal in the latest years, specifically from when Playwright has been released. It relies on standard web drivers which are not meant to be used for web scraping and can be easily detected by anti-bot software. Undetected Chromedriver On the other hand, you can get a better result at a fraction of the complexity using the undetected_chromedriver python package. In this case, you’re still using a web driver, but one that is modified and compiled with the final purpose to be used in web scraping projects. Playwright Playwright was released in 2020, and at the moment, it’s my favorite tool because of its flexibility and ease of usage. After the installation (via pip), you can start right with 3 different browsers, both in headful or headless mode. And if you need more, you can install other clients like Chrome (instead of the chromium bundled) or some compatible anti-detect browser like GoLogin, to get more options for your scrapers. Even Playwright is not meant for web scraping, and there was a plugin for customizing the bundled browsers, but it's not been updated for a too long time and is no more effective. But playing around with the right combo of browser and settings, to me, it’s my first choice. Pyppeteer It’s an unofficial porting in Python of Puppeteer, the original project of browser automation from where Playright took “inspiration”. I don’t find any reason actually to prefer it to Playwright, but it’s another option worth mentioning. It has a stealth module but, at least in these tests, it didn’t work as expected. The Tested Antibots In this post, we’ll see how the tools mentioned before perform against the most well-known anti-bot solutions. We will perform a generic page load test on 5 different websites, one per solution. It cannot be an exhaustive test, since every website can have a different setup and different rules to block or not suspicious traffic. On top of that, by loading only one page, we cannot test if the behavior of a spider written using one of the tools could be marked as a bot. And, last but not least, there will be cases where some sections of websites (like the login pages) would be protected by stricter rules than the home page. Given that, our test could be a good starting point to understand which tool is more convenient to start with. Cloudflare Cloudflare Bot Management solution utilizes a combination of signature-based detection and machine learning algorithms to accurately identify and classify bot traffic. The solution also offers rate-limiting, CAPTCHA challenges, and JavaScript challenges to mitigate the impact of bots on a website's security, performance, and user experience. It’s one of the most used and strongest solutions to bypass if configured in a strict way. PerimeterX PerimeterX uses real-time behavior analysis and machine learning to detect and block bots in real time while allowing legitimate traffic to pass through. Compared to Cloudflare Bot Management, PerimeterX also focuses on real-time behavior analysis and machine learning, including, at the same time, the ability to detect advanced bots that use techniques like IP hopping, browser fingerprinting, and headless browsing. In our tests, we’ll see it will be the easiest to bypass, at least for the website we considered. Datadome Datadome is another anti-bot solution with all the features mentioned before; for our tests, it was the hardest to consistently bypass. Typically, we could load the target page for the first time with every solution, but if we try to test it for a second time from the same IP, the load will fail. Kasada I think it’s the youngest solution on the market between the ones tested here, and it’s the most recognizable. When loading inside your browser a website protected with Kasada for the first time, you should notice in the network tab of the developers’ tool window a 429 error. This is the “challenge” that Kasada sends to the browser and, if it is solved, then you get redirected to the target website. It is called a zero-trust security policy. F5 In my filter bubble (fashion e-commerces), I don’t see many F5-protected websites, but when configured strictly, it’s not that easy to bypass. It seems to rely heavily on AI to detect strange behavior in the users, but even loading a single page of our testing website was not simple. Loading... The Tests Results The last image says almost everything, but if you want more, you can continue reading on the full article. The Web Scraping Club Also published here