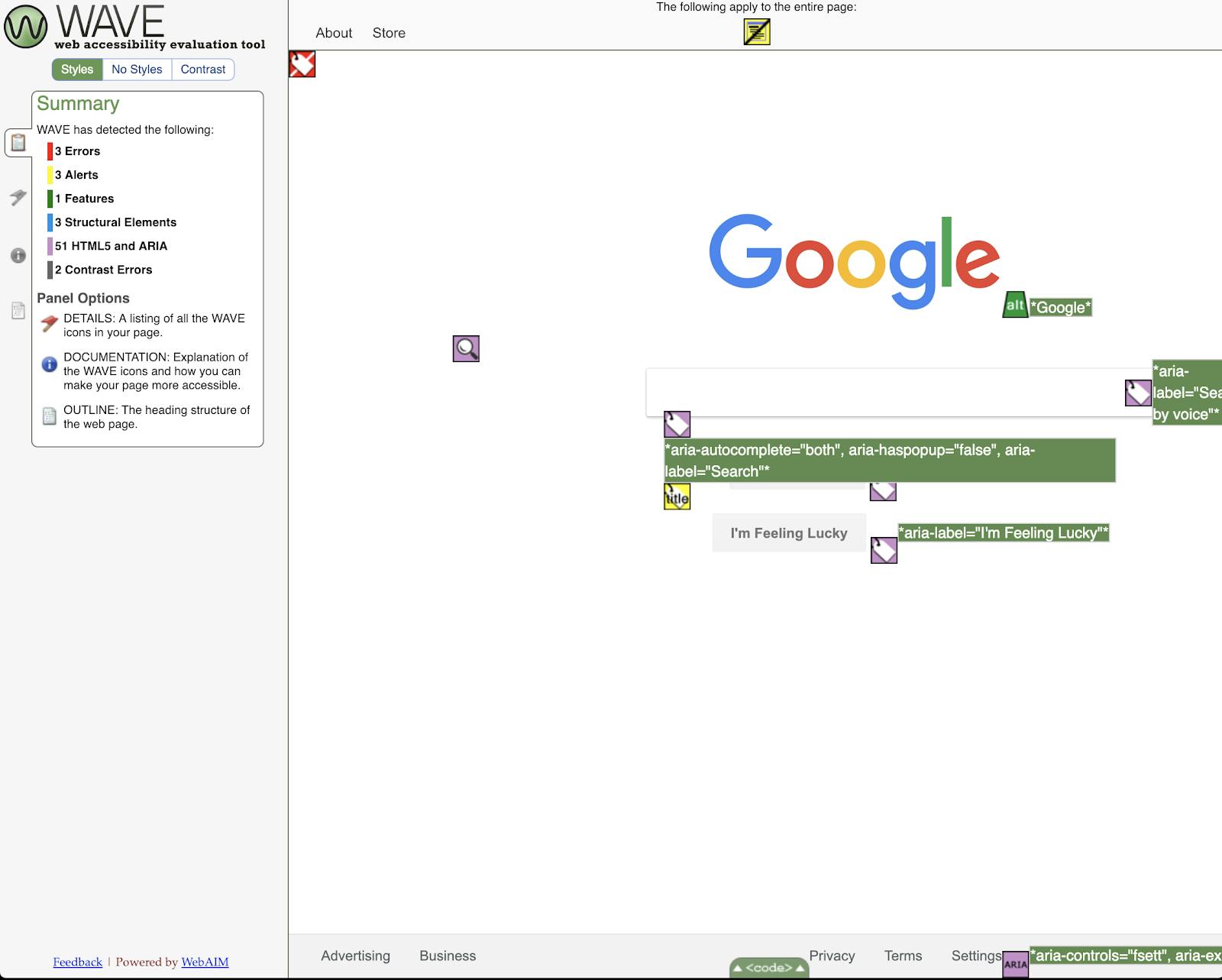
148 reads
The Universal Benefits of PDF/UA
by byKenneth HLVT@captcave
byKenneth HLVT@captcave
When I am not out chasing grades in rock climbing, I work in DevRel and enjoy writing technical content.
April 8th, 2022






When I am not out chasing grades in rock climbing, I work in DevRel and enjoy writing technical content.


When I am not out chasing grades in rock climbing, I work in DevRel and enjoy writing technical content.
About Author

When I am not out chasing grades in rock climbing, I work in DevRel and enjoy writing technical content.
Comments