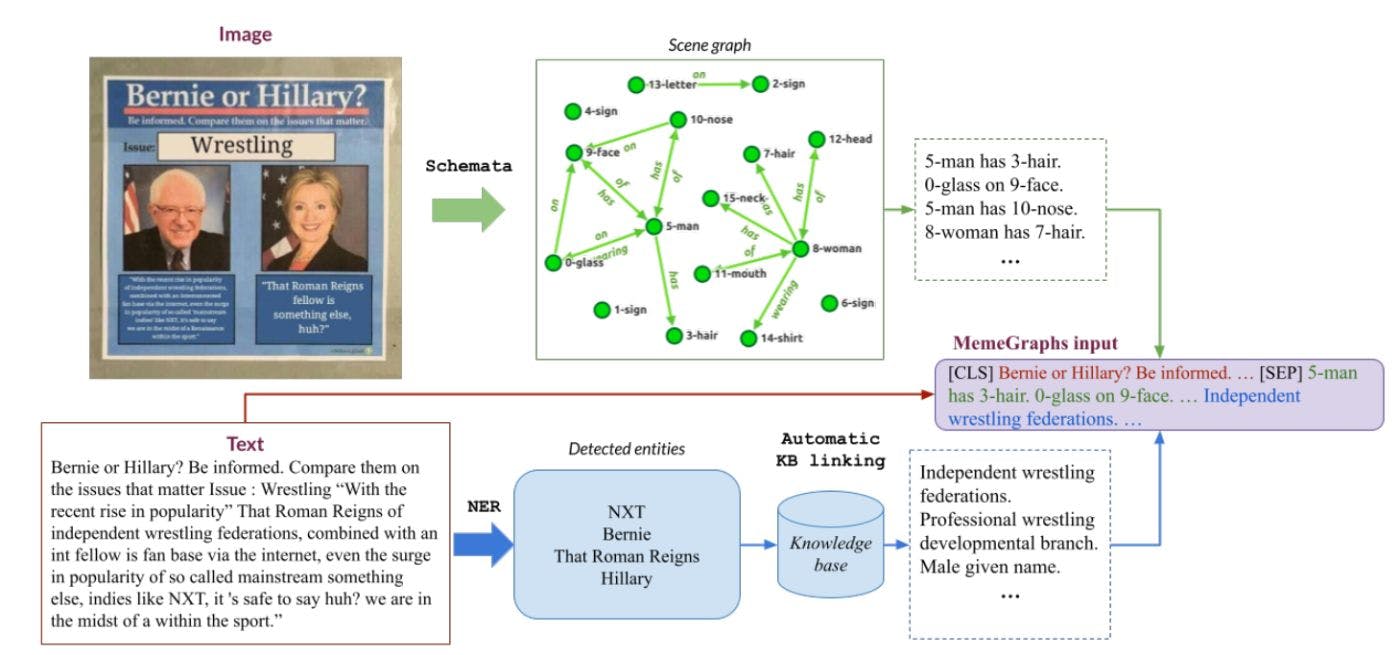
Addressing the issue regarding identification and annotation of inappropriate content in text calls for maintaining and securing a respectful online environment. It also involves detecting explicit and implicit hate speech. Hence, improper language or hate speech detection plays a significant role in online conversations. The collection and annotation of data for training automatic classifiers for detecting hate speech is a daunting task as it involves evaluating several hate speech detection systems. As of date, it is a difficult task to detect hate speech as there is no standard definition of hate speech.This results in creation of datasets which are not just from different sources, but also capture varied information. This makes it very tough to gain direct access to hate speech given the nuances and subtleties in language. Understanding Hate Speech According to the United Nations Strategy and Plan of Action on Hate Speech, hate speech can be defined as, “any kind of communication in speech, writing or behaviour, that attacks or uses pejorative or discriminatory language with reference to a person or a group on the basis of who they are, in other words, based on their religion, ethnicity, nationality, race, colour, descent, gender or other identity factor.” Detecting Hate Speech The Internet nowadays is flooded with toxic and harmful content. The increase in number of social network users have resulted in the rapid spread of toxic content. There are many definitions of toxic content on social network like hate speech, deceptive news, cyber bullying, abusive and toxic language, and sarcasm. Hence, to limit the number of toxic comments and harassment posts, social network moderators require assistance from computers. Computers are also used for automatically detecting and identifying content that’s toxic. Recently, machine learning is also being used for detecting hate speech in texts. It involves employing machine learning techniques to classify text as hate speech. A key limitation with these approaches is with respect to decisions that can be made (opaque and tough) making it difficult for humans to know the reason why it was made. The three major stumbling blocks in annotating text consisting of hate speech are as outlined below: Defining hate speech: Since there is no clear definition of hate speech, it helps one to study it to enable easy annotation. This results in annotation that’s much more reliable. However, since there is a blurred line between hate speech and free expression, defining hate speech becomes impossible. Datasets: It is very difficult to collect and annotate data for training automatic classifiers to detect hate speech. Especially, if the identification and agreement to a particular hate speech is tough in the absence of a standard definition of hate speech. Apart from the above, social media platforms are flooded with hate speech, but most have stringent data usage and distribution policies resulting in very few number of datasets for the public to study, a majority of it coming from Twitter as it has a relatively lenient policy. Automated approaches to hate speech detection: Many social media platforms come with set user rules which ban hate speech. Hence, the enforcement of these rules require hard manual labor of reviewing every report. Also, off late, platforms like Facebook have increased the number of content moderators. Automated tools and approaches can hasten the reviewing process or allocation of human resource to the posts which require close human examination. i). Keyword-based approaches: These are quick and direct to comprehend, but they come with serious drawbacks. The detection of racial slurs will lead to highly precise systems with low recall. Also, systems relying mainly on keywords will be unable to identify hateful content which does not utilise these terms. On the contrary, inclusion of terms which may be or may not always be hateful like trash, swine, etc. can result in creating way too many false alarms, increase in recall at the cost of precision. Apart from this, the above approaches are unable to identify hate speech that does not contain hateful keywords. ii). Source metadata: Extra information from social media can assist in further understanding the characteristics of the posts and result in an enhanced identification approach. Hence, information like demographics of the posting like user, location, timestamp or social engagement on the platform can offer a better know-how of the post at a granular level. This information is not handy to external researchers as publishing of data which contains user information can raise privacy issues. External researchers can have only a part or none of the user information. iii). Machine learning classifiers: Machine learning models obtain samples of labeled text for producing a classifier which can detect hate speech as per labels annotated by content reviewers. Many models were put forth and proven to be successful in the past. iv). Content pre-processing and feature selection: The identification and classification of user generated content involves extraction of text which indicate hate. Hence, hate speech is seen as a societal issue that calls for an automatic hate speech detection system. There are current approaches along with a new system for achieving a reasonable level of accuracy. A new approach has also been proposed for outperforming existing systems at this task along with the added benefit of enhanced interpret-ability. Addressing the issue regarding identification and annotation of inappropriate content in text calls for maintaining and securing a respectful online environment. It also involves detecting explicit and implicit hate speech. Hence, improper language or hate speech detection plays a significant role in online conversations. The collection and annotation of data for training automatic classifiers for detecting hate speech is a daunting task as it involves evaluating several hate speech detection systems. As of date, it is a difficult task to detect hate speech as there is no standard definition of hate speech.This results in creation of datasets which are not just from different sources, but also capture varied information. This makes it very tough to gain direct access to hate speech given the nuances and subtleties in language. Understanding Hate Speech According to the United Nations Strategy and Plan of Action on Hate Speech, hate speech can be defined as, “any kind of communication in speech, writing or behaviour, that attacks or uses pejorative or discriminatory language with reference to a person or a group on the basis of who they are, in other words, based on their religion, ethnicity, nationality, race, colour, descent, gender or other identity factor.” Detecting Hate Speech The Internet nowadays is flooded with toxic and harmful content. The increase in number of social network users have resulted in the rapid spread of toxic content. There are many definitions of toxic content on social network like hate speech, deceptive news, cyber bullying, abusive and toxic language, and sarcasm. Hence, to limit the number of toxic comments and harassment posts, social network moderators require assistance from computers. Computers are also used for automatically detecting and identifying content that’s toxic. Recently, machine learning is also being used for detecting hate speech in texts. It involves employing machine learning techniques to classify text as hate speech. A key limitation with these approaches is with respect to decisions that can be made (opaque and tough) making it difficult for humans to know the reason why it was made. The three major stumbling blocks in annotating text consisting of hate speech are as outlined below: Defining hate speech: Since there is no clear definition of hate speech, it helps one to study it to enable easy annotation. This results in annotation that’s much more reliable. However, since there is a blurred line between hate speech and free expression, defining hate speech becomes impossible. Defining hate speech: Since there is no clear definition of hate speech, it helps one to study it to enable easy annotation . This results in annotation that’s much more reliable. However, since there is a blurred line between hate speech and free expression, defining hate speech becomes impossible. Defining hate speech: enable easy annotation Datasets: It is very difficult to collect and annotate data for training automatic classifiers to detect hate speech. Especially, if the identification and agreement to a particular hate speech is tough in the absence of a standard definition of hate speech. Apart from the above, social media platforms are flooded with hate speech, but most have stringent data usage and distribution policies resulting in very few number of datasets for the public to study, a majority of it coming from Twitter as it has a relatively lenient policy. Datasets: It is very difficult to collect and annotate data for training automatic classifiers to detect hate speech. Especially, if the identification and agreement to a particular hate speech is tough in the absence of a standard definition of hate speech. Apart from the above, social media platforms are flooded with hate speech, but most have stringent data usage and distribution policies resulting in very few number of datasets for the public to study, a majority of it coming from Twitter as it has a relatively lenient policy. Datasets: Automated approaches to hate speech detection: Many social media platforms come with set user rules which ban hate speech. Hence, the enforcement of these rules require hard manual labor of reviewing every report. Also, off late, platforms like Facebook have increased the number of content moderators. Automated tools and approaches can hasten the reviewing process or allocation of human resource to the posts which require close human examination. Automated approaches to hate speech detection: Many social media platforms come with set user rules which ban hate speech. Hence, the enforcement of these rules require hard manual labor of reviewing every report. Also, off late, platforms like Facebook have increased the number of content moderators. Automated tools and approaches can hasten the reviewing process or allocation of human resource to the posts which require close human examination. Automated approaches to hate speech detection: Many social media platforms come with set user rules which ban hate speech. Hence, the enforcement of these rules require hard manual labor of reviewing every report. Also, off late, platforms like Facebook have increased the number of content moderators. Automated tools and approaches can hasten the reviewing process or allocation of human resource to the posts which require close human examination. Automated approaches to hate speech detection: i). Keyword-based approaches: These are quick and direct to comprehend, but they come with serious drawbacks. The detection of racial slurs will lead to highly precise systems with low recall. Also, systems relying mainly on keywords will be unable to identify hateful content which does not utilise these terms. On the contrary, inclusion of terms which may be or may not always be hateful like trash, swine, etc. can result in creating way too many false alarms, increase in recall at the cost of precision. Apart from this, the above approaches are unable to identify hate speech that does not contain hateful keywords. i). Keyword-based approaches: ii). Source metadata: Extra information from social media can assist in further understanding the characteristics of the posts and result in an enhanced identification approach. Hence, information like demographics of the posting like user, location, timestamp or social engagement on the platform can offer a better know-how of the post at a granular level. This information is not handy to external researchers as publishing of data which contains user information can raise privacy issues. External researchers can have only a part or none of the user information. ii). Source metadata: iii). Machine learning classifiers: Machine learning models obtain samples of labeled text for producing a classifier which can detect hate speech as per labels annotated by content reviewers. Many models were put forth and proven to be successful in the past. iii). Machine learning classifiers: iv). Content pre-processing and feature selection: The identification and classification of user generated content involves extraction of text which indicate hate. Hence, hate speech is seen as a societal issue that calls for an automatic hate speech detection system. There are current approaches along with a new system for achieving a reasonable level of accuracy. A new approach has also been proposed for outperforming existing systems at this task along with the added benefit of enhanced interpret-ability. iv). Content pre-processing and feature selection: