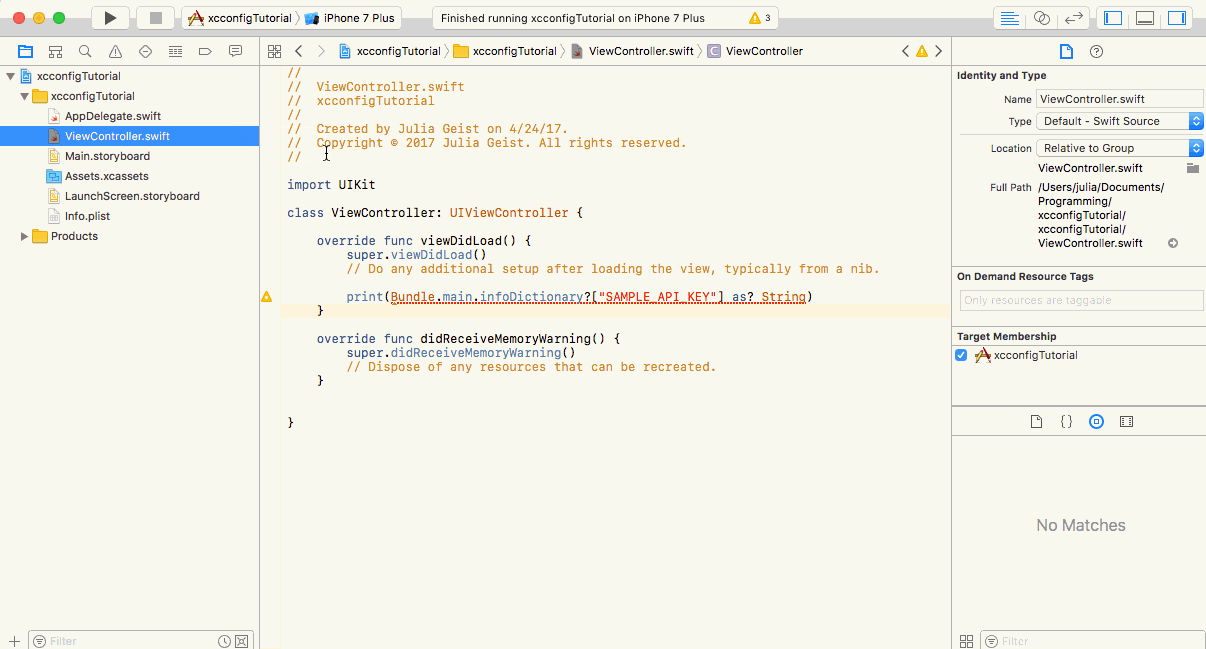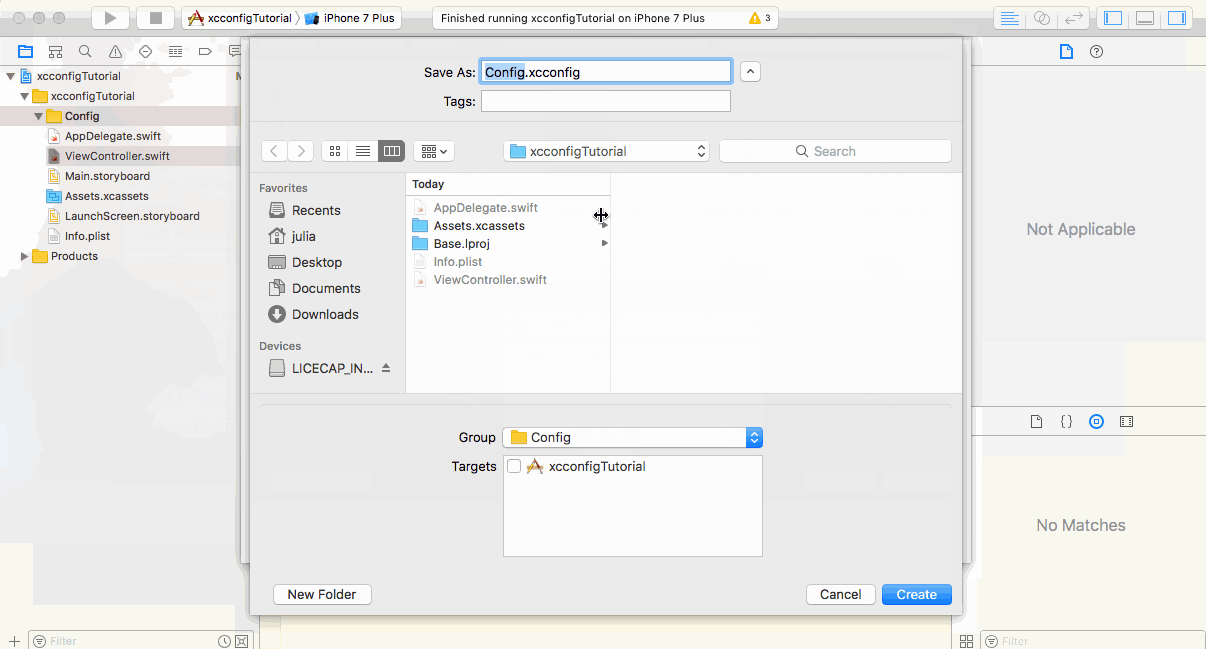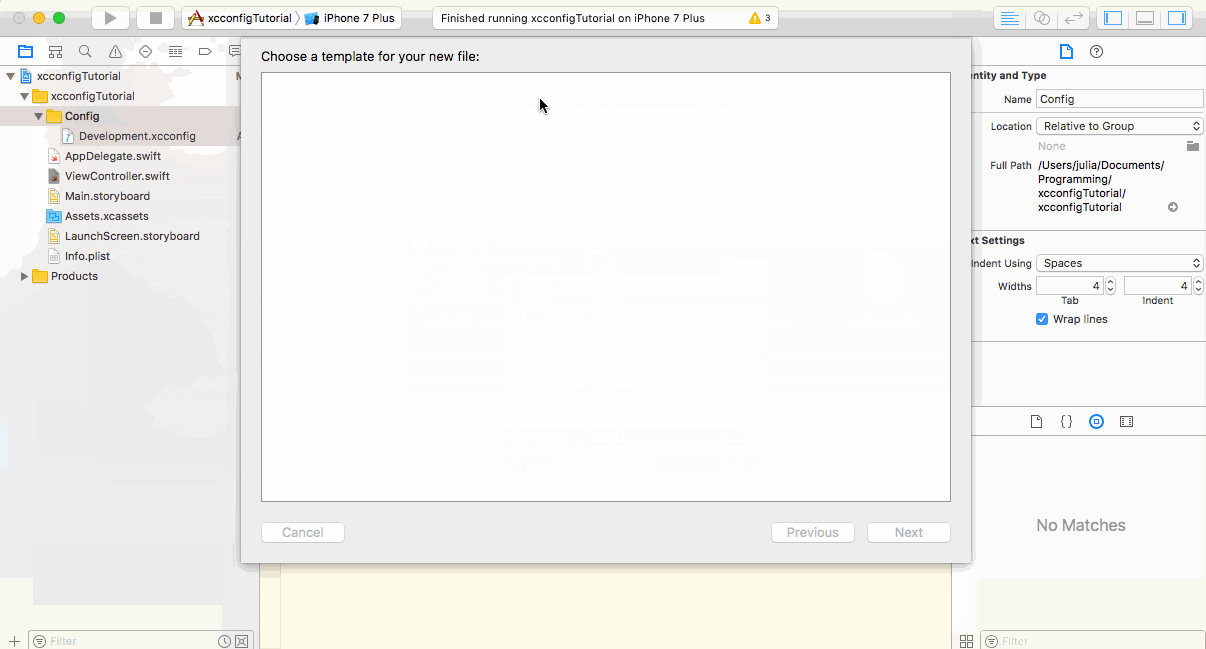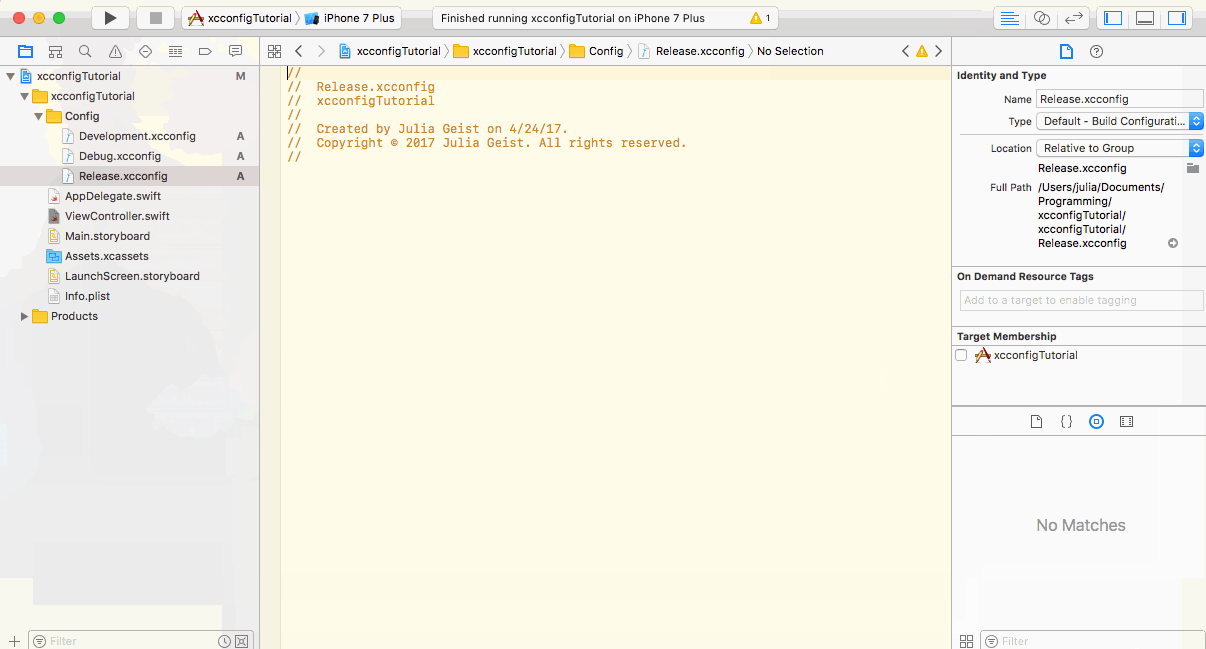
The missing link in the evolution of the software development life cycle. Photo by on Johannes Plenio Unsplash The way we develop, test and deploy software has been advancing in leaps and bounds over the last 10 years or so. For the sake of brevity, and to not give any old school developers terrible flashback of code on , the timeline I am discussing will be focused on the last 11 years (when Github went live) and the one GIANT step we missed when it comes to managing and deploying your software. punch cards The process as it stands today The way we deliver code in modern day software development is more or less the same across most places. It boils down to a software development life cycle (SDLC) and product/project planning and can be broken down into the following sections. Code You code collaboratively using tools like Github, Bitbucket, Gitlab (or for those of you who hate yourselves, SVN). This allows multiple developers to work on a single project in unison. This part we got down pat. After you code you go to the next step which is building. Build This part is also locked down with some very well defined processes. To ensure developers can build and run the code locally we have docker. In order to build the code while deploying we use tools like Jenkins, Circle CI, Travis… Test Depending on your stack and testing goals your tools may vary but it boils down to the same thing. You have your unit tests, integration tests, UI tests… You can use tools like Mockito for Java Spring projects; mocha, chai for javascript/typescript projects; selenium for UI testing and while how you use these tools varies, the motivation as to why we use these tools stays the same. All these tests can and should be ran by your build process that is defined previously. Release & Deploy After all your hard work, your tests all pass, your test coverage is at 100% (am I right 😉) the fun part starts. You get to release and deploy your code. While before we used to literally have “ ”, we are now at a pretty good place when it comes to integrating different components. Whether you use Kubernetes or Rancher for your orchestration and container management and AWS or GCP for your infrastructure for this article it doesn’t matter. The point is your code is live, users are using it and loving it. integration hell Image from https://hackernoon.com/delivery-pipelines-as-enabler-for-a-devops-culture-ebc45963f703 Operate & Monitor After you release and deploy you have to make sure that your applications are healthy, withstanding the load, recovering when they are down… Whether you are scaling up your pods on Kubernetes, making sure your application isn’t logging errors in ELK or just keeping an eye on your performance metrics on NewRelic; you need to ensure that your code is up, running and doing what it’s supposed to. Project Planning and Communication It’s not just the coding and delivering software that have come a long way. The improvements in project planning and communication have also helped everyone involved to deliver better products. We went from rigorous spreadsheets and gantt charts, to an agile way of delivering products, from 100 page long manifests, to tools like Jira and Asana. Communication has gone from never ending email threads (well we still have those unfortunately) to using Slack. All in all, the software industry has been focused on how to deliver more value, at a faster pace while not sacrificing quality. BUT, there is still a missing link in this evolution. The one big missing piece that glues all these pieces together is the management of your configurations. During every step of the way your API keys, configurations and the context of how you run your code changes. The missing link With all of these tools and processes in place we are still missing a proper way to manage our configurations. When you’re developing you are using your local environment and have one set of configurations. Even if you want to point your local environment to QA for some external services, you are still changing the context of how your code runs. When you are building with Jenkins you want to run against a mocked or test environment (don’t want to be running those e2e tests against your production servers). When you release your code to production you need to have the right API keys in the right places. You don’t want to accidentally promote your test Stripe keys to your production environment or forget about them all together. Although configurations are required literally at every single step of the SDLC, there is no stage defined for it and thus it has, unfortunately, been largely ignored. This has resulted in a across the entire software industry. This causes major outages (looking at you ), security breaches (looking at you ) or a ton of time wasted trying to figure out why your entire tech stack went down (looking at you every single software developer ever, including myself). When it comes to configuration management, it’s extremely difficult to securely onboard and off-board team members, share them across the organization in a secure manner and version the configuration files as they evolve. wide variety of solutions Netflix Equifax All the previous changes and evolutions mentioned above started off chaotic and disorganized and have been standardized and agreed upon by the software world. The current stack of solution simply don’t satisfy the needs of the current SDLC. Solutions like ansible-vault, git-encypt, Vault and Consul attempt to address both security and sharing but miss the mark completely when it comes to on-boarding, off-boarding, versioning, release tracking…. It’s time to evolve and patch that missing link. Configuration management, and I mean proper configuration management is the last aspect that is blocking true CI/CD. At we believe the future is collaborative, and are working towards a space of Collaborative Configuration Management. ConfigTree.co No more wondering why two services can’t connect, no more having to scramble and change your prod keys in case someone quits, no more digging into logs upon logs wondering why you’re authentication is failing with an external service. If you’re tired of dealing with mismanaged files and your own way of dealing with the frustrations let me know :) Drop a comment below or give me a shout on twitter at or . @mlevkov @configtree If you liked the article please hit the 👏 so other people can enjoy it.