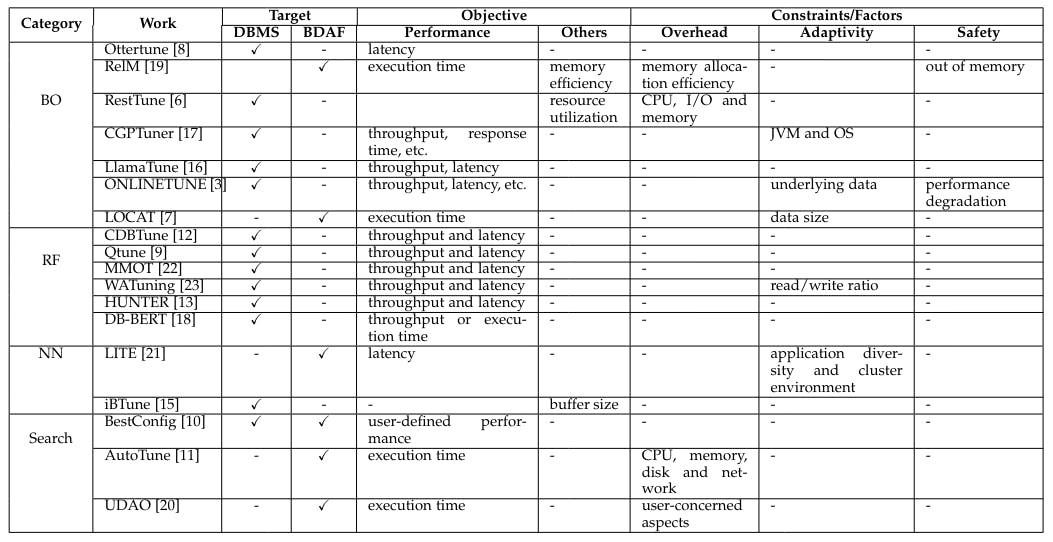
Authors: (1) Limeng Zhang, Centre for Research on Engineering Software Technologies (CREST), The University of Adelaide, Australia; (2) M. Ali Babar, Centre for Research on Engineering Software Technologies (CREST), The University of Adelaide, Australia. Table of Links Abstract and 1 Introduction 1.1 Configuration Parameter Tuning Challenges and 1.2 Contributions 2 Tuning Objectives 3 Overview of Tuning Framework 4 Workload Characterization and 4.1 Query-level Characterization 4.2 Runtime-based Characterization 5 Feature Pruning and 5.1 Workload-level Pruning 5.2 Configuration-level Pruning 5.3 Summary 6 Knowledge from Experience 7 Configuration Recommendation and 7.1 Bayesian Optimization 7.2 Neural Network 7.3 Reinforcement Learning 7.4 Search-based Solutions 8 Experimental Setting 9 Related Work 10 Discussion and Conclusion, and References 1.1 Configuration Parameter Tuning Challenges In order to find an optimal configuration for a DBMS workload, either a database administrator or a tuning program has to address a number of challenges. First, the parameter space is vast and intricate, with a large number of knobs existing in continuous space, and the number of DBMS knobs continues to grow with each new version and feature release. Staying abreast of these changes and comprehending their implications for system performance presents an ongoing challenge for database administrators [3], [8]. Second, the interdependence of parameters within DBMSs complicates the optimization process. Altering one knob may have repercussions on the effectiveness of another, introducing nonlinear correlations that pose difficulties for both manual and model-based configuration identification. Third, the diversity and heterogeneity of workloads, hardware, and other environmental factors in a DBMS further contribute to the complexity. A DBMS may host numerous instances, each accommodating various types of workloads. Real-world application workloads are dynamic, with properties such as workload types, workload parallelization, workload records, and operations counts exhibiting variations over time [3], [9]. Furthermore, training samples are scarce due to the time-intensive process of gathering historical observations and the complexity introduced by high-dimensional parameters. Addressing these challenges requires sophisticated approaches and tools to enhance the efficiency of DBMSs in diverse and dynamic operational environments. 1.2 Contributions Through an investigation into the state-of-the-art automatic DBMS configuration tuning, we aim to provide researchers, developers, and practitioners with comprehensive insights and guidance in the field. In this study, our contributions are fourfold: We provide an overview of a wide spectrum of prominent automatic tuning methods for cloud databases, as discussed in various studies [3], [6], [8]–[18]. These methods include Bayesian optimization-based methods, Neural network-based methods, Reinforcement learning-based methods, and Search-based methods. Meanwhile, we also include several relevant automatic tuning methods [7], [19]–[21], which focus on big data analytics framework but encounter similar challenges in identifying the optimal configuration within the complex and dependent configuration space. We outline the primary tuning objectives and summarize three main constraints or factors frequently discussed in automatic configuration tuning in DBMS (Section 2): overhead, adaptivity, and safety. We provide a comprehensive overview of the automatic tuning pipeline, encompassing Workload Characterization (Section 4), Feature Pruning (Section 5), Knowledge from Experience (Section 6), Configuration Recommendation (Section 7). We describe in detail the key features in each part. We providing a comprehensive summary of popular open-source benchmarks utilized for evaluating database performance optimization. This paper is available on arxiv under CC BY 4.0 DEED. Authors: (1) Limeng Zhang, Centre for Research on Engineering Software Technologies (CREST), The University of Adelaide, Australia; (2) M. Ali Babar, Centre for Research on Engineering Software Technologies (CREST), The University of Adelaide, Australia. Authors: Authors: (1) Limeng Zhang, Centre for Research on Engineering Software Technologies (CREST), The University of Adelaide, Australia; (2) M. Ali Babar, Centre for Research on Engineering Software Technologies (CREST), The University of Adelaide, Australia. Table of Links Abstract and 1 Introduction Abstract and 1 Introduction 1.1 Configuration Parameter Tuning Challenges and 1.2 Contributions 1.1 Configuration Parameter Tuning Challenges and 1.2 Contributions 2 Tuning Objectives 2 Tuning Objectives 3 Overview of Tuning Framework 3 Overview of Tuning Framework 4 Workload Characterization and 4.1 Query-level Characterization 4 Workload Characterization and 4.1 Query-level Characterization 4.2 Runtime-based Characterization 4.2 Runtime-based Characterization 5 Feature Pruning and 5.1 Workload-level Pruning 5 Feature Pruning and 5.1 Workload-level Pruning 5.2 Configuration-level Pruning 5.2 Configuration-level Pruning 5.3 Summary 5.3 Summary 6 Knowledge from Experience 6 Knowledge from Experience 7 Configuration Recommendation and 7.1 Bayesian Optimization 7 Configuration Recommendation and 7.1 Bayesian Optimization 7.2 Neural Network 7.2 Neural Network 7.3 Reinforcement Learning 7.3 Reinforcement Learning 7.4 Search-based Solutions 7.4 Search-based Solutions 8 Experimental Setting 8 Experimental Setting 9 Related Work 9 Related Work 10 Discussion and Conclusion, and References 10 Discussion and Conclusion, and References 1.1 Configuration Parameter Tuning Challenges In order to find an optimal configuration for a DBMS workload, either a database administrator or a tuning program has to address a number of challenges. First, the parameter space is vast and intricate, with a large number of knobs existing in continuous space, and the number of DBMS knobs continues to grow with each new version and feature release. Staying abreast of these changes and comprehending their implications for system performance presents an ongoing challenge for database administrators [3], [8]. Second, the interdependence of parameters within DBMSs complicates the optimization process. Altering one knob may have repercussions on the effectiveness of another, introducing nonlinear correlations that pose difficulties for both manual and model-based configuration identification. Third, the diversity and heterogeneity of workloads, hardware, and other environmental factors in a DBMS further contribute to the complexity. A DBMS may host numerous instances, each accommodating various types of workloads. Real-world application workloads are dynamic, with properties such as workload types, workload parallelization, workload records, and operations counts exhibiting variations over time [3], [9]. Furthermore, training samples are scarce due to the time-intensive process of gathering historical observations and the complexity introduced by high-dimensional parameters. Addressing these challenges requires sophisticated approaches and tools to enhance the efficiency of DBMSs in diverse and dynamic operational environments. 1.2 Contributions Through an investigation into the state-of-the-art automatic DBMS configuration tuning, we aim to provide researchers, developers, and practitioners with comprehensive insights and guidance in the field. In this study, our contributions are fourfold: We provide an overview of a wide spectrum of prominent automatic tuning methods for cloud databases, as discussed in various studies [3], [6], [8]–[18]. These methods include Bayesian optimization-based methods, Neural network-based methods, Reinforcement learning-based methods, and Search-based methods. Meanwhile, we also include several relevant automatic tuning methods [7], [19]–[21], which focus on big data analytics framework but encounter similar challenges in identifying the optimal configuration within the complex and dependent configuration space. We outline the primary tuning objectives and summarize three main constraints or factors frequently discussed in automatic configuration tuning in DBMS (Section 2): overhead, adaptivity, and safety. We provide a comprehensive overview of the automatic tuning pipeline, encompassing Workload Characterization (Section 4), Feature Pruning (Section 5), Knowledge from Experience (Section 6), Configuration Recommendation (Section 7). We describe in detail the key features in each part. We providing a comprehensive summary of popular open-source benchmarks utilized for evaluating database performance optimization. We provide an overview of a wide spectrum of prominent automatic tuning methods for cloud databases, as discussed in various studies [3], [6], [8]–[18]. These methods include Bayesian optimization-based methods, Neural network-based methods, Reinforcement learning-based methods, and Search-based methods. Meanwhile, we also include several relevant automatic tuning methods [7], [19]–[21], which focus on big data analytics framework but encounter similar challenges in identifying the optimal configuration within the complex and dependent configuration space. We provide an overview of a wide spectrum of prominent automatic tuning methods for cloud databases, as discussed in various studies [3], [6], [8]–[18]. These methods include Bayesian optimization-based methods, Neural network-based methods, Reinforcement learning-based methods, and Search-based methods. Meanwhile, we also include several relevant automatic tuning methods [7], [19]–[21], which focus on big data analytics framework but encounter similar challenges in identifying the optimal configuration within the complex and dependent configuration space. We outline the primary tuning objectives and summarize three main constraints or factors frequently discussed in automatic configuration tuning in DBMS (Section 2): overhead, adaptivity, and safety. We outline the primary tuning objectives and summarize three main constraints or factors frequently discussed in automatic configuration tuning in DBMS (Section 2): overhead, adaptivity, and safety. We provide a comprehensive overview of the automatic tuning pipeline, encompassing Workload Characterization (Section 4), Feature Pruning (Section 5), Knowledge from Experience (Section 6), Configuration Recommendation (Section 7). We describe in detail the key features in each part. We provide a comprehensive overview of the automatic tuning pipeline, encompassing Workload Characterization (Section 4), Feature Pruning (Section 5), Knowledge from Experience (Section 6), Configuration Recommendation (Section 7). We describe in detail the key features in each part. We providing a comprehensive summary of popular open-source benchmarks utilized for evaluating database performance optimization. We providing a comprehensive summary of popular open-source benchmarks utilized for evaluating database performance optimization. This paper is available on arxiv under CC BY 4.0 DEED. This paper is available on arxiv under CC BY 4.0 DEED. available on arxiv