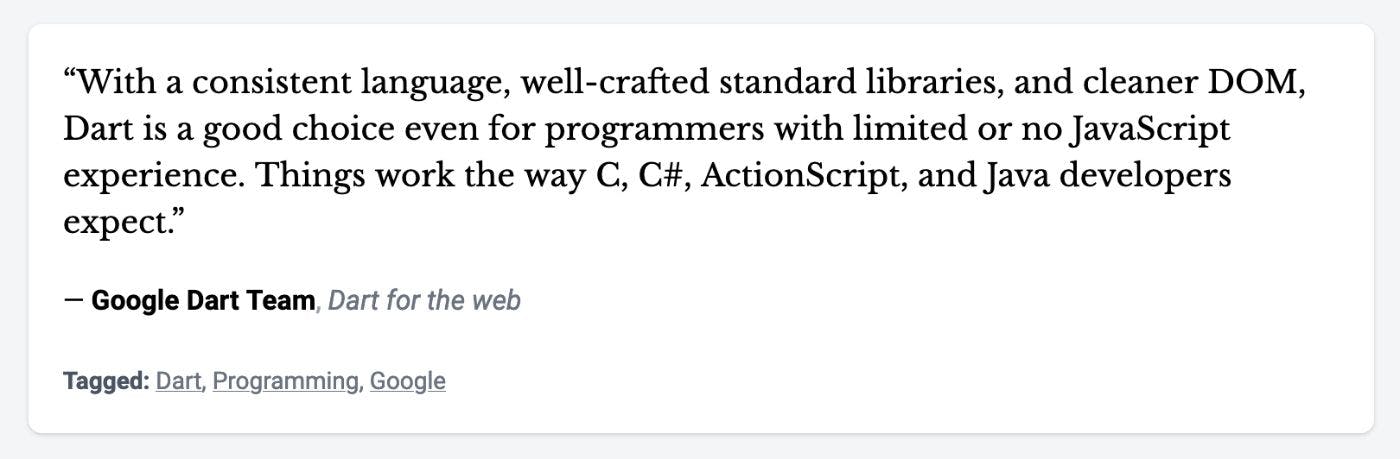
612 reads
The Hallucinating Boldface of ChatGPT— A Warning to Juniors in the Programming/Coding Career Path
by byOlaoluwa Afolabi@olaoluwa
byOlaoluwa Afolabi@olaoluwa
- Software Engineer - CEO, Lucre (getlucre.xyz - Bitcoin payment infrastructure).
January 17th, 2023






- Software Engineer - CEO, Lucre (getlucre.xyz - Bitcoin payment infrastructure).
Story's Credibility


- Software Engineer - CEO, Lucre (getlucre.xyz - Bitcoin payment infrastructure).
Story's Credibility
About Author
- Software Engineer - CEO, Lucre (getlucre.xyz - Bitcoin payment infrastructure).
Comments