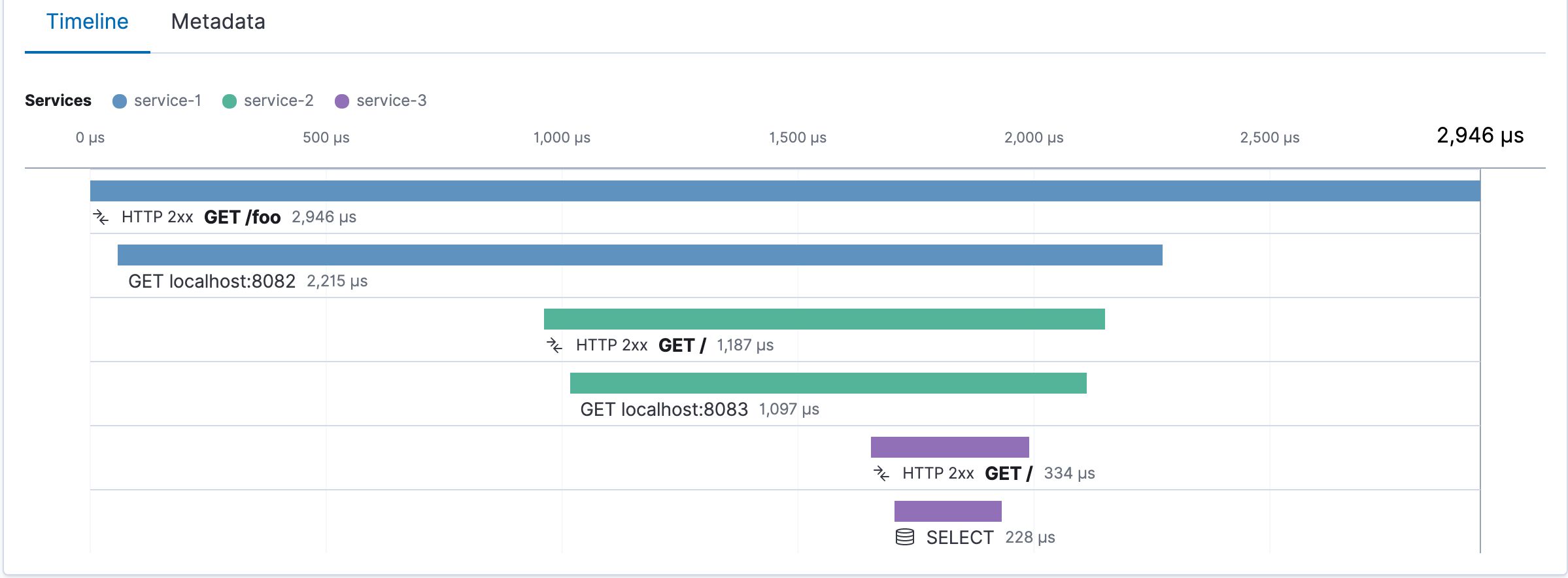
In the previous chapters of Node.js at Scale we learned how you can get , and how you can use . Node.js testing and TDD right Nightwatch.js for end-to-end testing Let’s discuss these topics: In this article, we will learn about running and monitoring Node.js applications in Production. What is monitoring? What should be monitored? Open-source monitoring solutions SaaS and On-premise monitoring offerings What is Node.js Monitoring? Monitoring is observing the quality of a software over time. The available products and tools we have in this industry usually go by the term or in short. Application Performance Monitoring APM If you have a Node.js application in a staging or production environment, you can (and should) do monitoring on different levels: You can monitor regions, zones, individual servers and, of course, the Node.js software that runs on them. In this guide we will deal with the software components only, as if you run in a cloud environment, the others are taken care for you usually. What should be monitored? Each application you write in Node.js produces a lot of data about its’ behavior. There are different layers where an APM tool should collect data from. The more of them covered, the more insights you’ll get about your system’s behavior. Service level Host level Instance (or process) level The list you can find below collects while you maintain a Node.js application in production. We’ll also discuss how monitoring helps to solve them and what kind of data you’ll need to do so. the most crucial problems you’ll run into Problem 1.: Service Downtimes If your application is unavailable, your customers can’t spend money on your sites. If your API’s are down, your business partners and services depending on them will fail as well because of you. We all know how cringeworthy it is to apologize for service downtimes. Your topmost priority should be preventing failures and providing 100% availability for your application. Running a production app comes with great responsibility. Node.js APM’s can easily help you detecting and preventing downtimes, since they usually collect service level metrics. This data can show if your application handles requests properly, although it won’t always help to tell if your public sites or API’s are available. If you want to cover everything, don’t forget to include different regions like the US, Europe and Asia too. To have a proper coverage on downtimes, we recommend to set up a pinger as well which can emulate user behavior and provide foolproof data on availability. Problem 2.: Slow Services, Terrible Response Times Slow response times have a huge impact on conversion rate, as well as on product usage. The faster your product is the more customers and user satisfaction you’ll have. Usually, all Node.js APM’s can show if your services are slowing down, but interpreting that data requires further analysis. I recommend doing two things to find the real reasons for slowing services. Collect data on a process level too. Check out each instance of a service to figure out what happens under the hood. Request CPU profiles when your services slow down and analyze them to find the faulty functions. Eliminating performance bottlenecks enables you to scale your software more efficiently and also to optimize your budget. Problem 3.: Solving Memory Leaks is Hard Our allowed us to build huge enterprise systems and help developers making them better. Node.js Consulting & Development expertise What we see constantly is that Memory Leaks in Node.js applications are quite frequent and that finding out what causes them is among the greatest struggles Node developers face. This impression is backed with data as well. Our showed that Memory Leaks cause a lot of headache for even the best engineers. Node.js Developer Survey To find memory leaks, you have to know exactly when they happen. What you should look for is the steady growth of memory usage which ends up in a service crash & restart . Some APM’s collect memory usage data which can be used to recognize a leak. (as Node runs out of memory after 1,4 Gigabytes) If your APM collects data on the Garbage Collector as well, you can look for the same pattern. As extra objects in a Node app’s memory pile up, the time spent with Garbage Collection increases simultaneously. This is a great indicator of the Memory Leak. After figuring out that you have a leak, request a memory heapdump and look for the extra objects! This sounds easy in theory but can be challenging in practice. What you can do is request 2 heapdumps from your production system with a Monitoring tool, and analyze these dumps with Chrome’s DevTools. If you look for the extra objects in comparison mode, you’ll end up seeing what piles up in your app’s memory. If you’d like a more detailed rundown on these steps, I wrote one article about in Ghost, where I go into more details. finding a Node.js memory leak Problem 4.: Depending on Code Written by Anonymus Most of the Node.js applications heavily rely on npm. We can end up with a lot of dependencies written by developers of unknown expertise and intentions. Roughly 76% of Node shops use vulnerable packages, while open source projects regularly grow stale, neglecting to fix security flaws. There are a couple of possible steps to lower the security risks of using npm packages. Audit your modules with the Node Security Platform CLI Look for unused dependencies with the tool depcheck Use the npm stats API, or browse historic stats on to find out if others using a package npm-stat.com Use the command to avoid packages maintained by only a few npm view <pkg> maintainers Use the command or to learn whether you're using the latest version of a package. npm outdated Greenkeeper Going through these steps can consume a lot of your time, so picking a Node.js Monitoring Tool which can warn you about insecure dependencies is highly recommended. Problem 6.: Email Alerts often go Unnoticed Let’s be honest. We are developers who like spending time writing code — not going through our email account every 10 minutes.. According to my experience, email alerts are usually unread and it’s very easy to miss out on a major outage or problem if we depend only on them. Email is a subpar method to learn about issues in production. I guess that you also don’t want to watch dashboards for potential issues 24/7. This is why it is important to look for an APM with great alerting capabilities. Pair up the monitoring solution of your choice with one of these systems if you'd like to know about your alerts instantly. What I recommend is to use pager systems like **opsgenie** or **pagerduty** to learn about critical issues. A few alerting best-practices we follow at RisingStack: Always keep alerting simple and alert on symptoms Aim to have as few alerts as possible — associated with end-user pain Alert on high response time and error rates as high up in the stack as possible Problem 7.: Finding Crucial Errors in the Code If a feature is broken on your site, it can prevent customers from achieving their goals. Sometimes it can be a sign of bad code quality. Make sure you have proper test coverage for your codebase and a good QA process . (preferably automated) If you use an APM that collects errors from your app then you’ll be able to find the ones which occur more often. The more data your APM is accessing, better the chances of finding and fixing critical issues. — so you’ll be able to find the root causes of errors in a distributed system. We recommend to use a monitoring tool which collects and visualises stack traces as well In the next part of the article, I will show you one open-source, and one SaaS / on-premises Node.js monitoring solution that will help you operate your applications. Prometheus — an Open-Source, General Purpose Monitoring Platform Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud. Prometheus was started in 2012, and since then, many companies and organizations have adopted the tool. It is a standalone open source project and maintained independently of any company. In 2016, Prometheus joined the Cloud Native Computing Foundation , right after Kubernetes. The most important features of Prometheus are: a multi-dimensional data model , (time series identified by metric name and key/value pairs) a flexible query language to leverage this dimensionality, time series collection happens via a pull model over HTTP by default, pushing time series is supported via an intermediary gateway. Node.js monitoring with prometheus As you could see from the previous features, Prometheus is a general purpose monitoring solution, so you can use it with any language or technology you prefer. Check out the official if you’d like to give it a try. Prometheus getting started pages Before you start monitoring your Node.js services, you need to add instrumentation to them via one of the Prometheus client libraries. For this, there is a Node.js client module, which you can find . It supports histograms, summaries, gauges and counters. here Essentially, all you have to do is the Prometheus client, then expose its output at an endpoint: require const Prometheus = require('prom-client') const server = require('express')() server.get('/metrics', (req, res) => { res.end(Prometheus.register.metrics()) }) server.listen(process.env.PORT || 3000) This endpoint will produce an output, that Prometheus can consume — something like this: # HELP process_start_time_seconds Start time of the process since unix epoch in seconds. # TYPE process_start_time_seconds gauge process_start_time_seconds 1490433285 # HELP process_resident_memory_bytes Resident memory size in bytes. # TYPE process_resident_memory_bytes gauge process_resident_memory_bytes 33046528 # HELP nodejs_eventloop_lag_seconds Lag of event loop in seconds. # TYPE nodejs_eventloop_lag_seconds gauge nodejs_eventloop_lag_seconds 0.000089751 # HELP nodejs_active_handles_total Number of active handles. # TYPE nodejs_active_handles_total gauge nodejs_active_handles_total 4 # HELP nodejs_active_requests_total Number of active requests. # TYPE nodejs_active_requests_total gauge nodejs_active_requests_total 0 # HELP nodejs_version_info Node.js version info. # TYPE nodejs_version_info gauge nodejs_version_info{version="v4.4.2",major="4",minor="4",patch="2"} 1 Of course, these are just the default metrics which were collected by the module we have used — you can extend it with yours. In the example below we collect the number of requests served: const Prometheus = require('prom-client') const server = require('express')() const PrometheusMetrics = { requestCounter: new Prometheus.Counter('throughput', 'The number of requests served') } server.use((req, res, next) => { PrometheusMetrics.requestCounter.inc() next() }) server.get('/metrics', (req, res) => { res.end(Prometheus.register.metrics()) }) server.listen(3000) Once you run it, the endpoint will include the throughput metrics as well: /metrics # HELP process_start_time_seconds Start time of the process since unix epoch in seconds. # TYPE process_start_time_seconds gauge process_start_time_seconds 1490433805 # HELP process_resident_memory_bytes Resident memory size in bytes. # TYPE process_resident_memory_bytes gauge process_resident_memory_bytes 25120768 # HELP nodejs_eventloop_lag_seconds Lag of event loop in seconds. # TYPE nodejs_eventloop_lag_seconds gauge nodejs_eventloop_lag_seconds 0.144927586 # HELP nodejs_active_handles_total Number of active handles. # TYPE nodejs_active_handles_total gauge nodejs_active_handles_total 0 # HELP nodejs_active_requests_total Number of active requests. # TYPE nodejs_active_requests_total gauge nodejs_active_requests_total 0 # HELP nodejs_version_info Node.js version info. # TYPE nodejs_version_info gauge nodejs_version_info{version="v4.4.2",major="4",minor="4",patch="2"} 1 # HELP throughput The number of requests served # TYPE throughput counter throughput 5 Once you have exposed all the metrics you have, you can start querying and visualizing them — for that, please refer to the official and the . Prometheus query documentation vizualization documentation While sometimes these solutions can provide greater flexibility for your use-case than hosted solutions, it can take months to implement them & then you have to deal with operating them as well. As you can imagine, instrumenting your codebase can take quite some time — since you have to create your dashboard and alerts to make sense of the data. If you have the time to dig deep into the topic, you’ll be fine with it. Meet Trace — our SaaS, and On-premises Node.js Monitoring Tool As we just discussed, running your own solution requires domain knowledge, as well as expertise on how to do proper monitoring. You have to figure out what aggregation to use for what kind of metrics, and so on.. This is why it can make a lot of sense to go with a hosted monitoring solution — whether it is a SaaS product or an on-premises offering. At RisingStack, we are developing . We built all the experience into Trace which we gained through the years of providing . our own Node.js Monitoring Solution, called Trace professional Node services What’s nice about Trace, is that to your application — so it really takes only a few seconds to get started. you have all the metrics you need with only adding a single line of code require([email protected]/trace') After this, the collector automatically gathers your application’s performance data and visualizes it for you in an easy to understand way. Trace Just a few things Trace is capable to do with your production Node app: Send alerts about Downtimes, Slow services & Bad Status Codes. Ping your websites and API’s with an external service + show APDEX metrics. Collect data on service, host and instance levels as well. Automatically create a (10 second-long) CPU profile in a production environment in case of a slowdown. Collect data on memory consumption and garbage collection. Create memory heapdumps automatically in case of a Memory Leak in production. Show errors and stack traces from your application. Visualize whole transaction call-chains in a distributed system. Show how your services communicate with each other on a live map. Automatically detect npm packages with security vulnerabilities. Mark new deployments and measure their effectiveness. Integrate with Slack, Pagerduty, and Opsgenie — so you’ll never miss an alert. Although Trace is currently a SaaS solution, we’ll make an on-premises version available as well soon. It will be able to do exactly the same as the cloud version, but it will run on Amazon VPC or in your own datacenter. If you’re interested in it, let’s talk! I hope that in this chapter of Node.js at Scale I was able to give useful advice about monitoring your Node.js application. In the next article, you will learn how to debug Node.js applications in an easy way. Originally published at blog.risingstack.com on March 28, 2017.