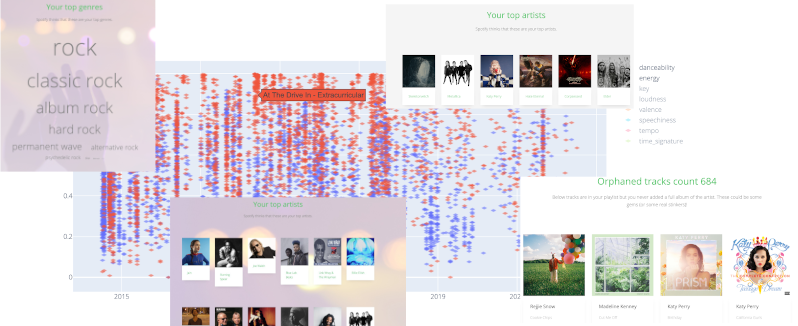
There are many articles on analyzing Spotify data and many applications as well. Some are a one-time analysis on individual's music library and some are an app for a specific purpose. This app is different in that it does not do one thing. It is meant to grow and provide a place to add more analysis. This article is about how the audio features time series was created. More articles will be coming detailing other functionality. The app is currently deployed on Heroku and Render. To get the latest working address refer to the . project GitHub page Audio features time series This analysis looks best to those with a longer history of using Spotify as it shows data in a time series. A time series is, as the name suggests, data splayed over time. In this analysis, we use the song features provided by Spotify and map them over time to show whether our tastes have changed over time. In my case for example there is a slight decrease in the energy of the songs that I added in the recent 2 years vs the previous 4 years. (This I attribute to my SO :). In the app, after login we load data. There is a bit of processing but in the end, we end up with various JSON files. In this case, we will use tracks.json and audio_features.json. Both of these files have the same number of JSON objects and they're in the same order. In this analysis, we'll use these two data files to further transform them in order to plot them. We start with audio features. Below is an example of features for one track (we have 3868 tracks in our library). [ { : , : , : , : , : , : , : , : , : , : , : , : , : , : , : , : , : , : }, "danceability" 0.517 "energy" 0.472 "key" 11 "loudness" -12.606 "mode" 1 "speechiness" 0.105 "acousticness" 0.191 "instrumentalness" 0.0946 "liveness" 0.105 "valence" 0.675 "tempo" 73.744 "type" "audio_features" "id" "2FUKNB0ArS2jVY73Ju3d2U" "uri" "spotify:track:2FUKNB0ArS2jVY73Ju3d2U" "track_href" "https://api.spotify.com/v1/tracks/2FUKNB0ArS2jVY73Ju3d2U" "analysis_url" "https://api.spotify.com/v1/audio-analysis/2FUKNB0ArS2jVY73Ju3d2U" "duration_ms" 404627 "time_signature" 4 Not all these are useful features for plotting. We'll only keep seven of them: ['danceability', 'energy', 'key', 'loudness', 'valence', 'speechiness', 'tempo']. We also need to transpose this (in a simple loop) to have 7 arrays of 3868 data points long. Some of this data is already normalized but not all. We use sklearn.MinMaxScaler to do a quick transformation directly on the array. After this we now have our data array with data ready for plotting but it wouldn't be very much of a time series without timestamps. To get timestamps we turn to tracks. Each track has a date_added field and they're already sorted in our json file with the latest track added being on top. [ { : , : { .. : , : , : , : , : , : } }, "added_at" "2020-11-16T11:08:53Z" "track" "name" "A Vast Filthy Prison" "popularity" 17 "preview_url" "https://p.scdn.co/mp3-preview/e60c4014418dfa75ec4201083e32f78831035c12?cid=47821343906643e3a7a156c5a3376c6d" "track_number" 10 "type" "track" "uri" "spotify:track:2FUKNB0ArS2jVY73Ju3d2U" We load tracks and again in a simple loop extract only what we will want to plot. We take the timestamp when it was added, artist and song name. We use this information as a hover over effect in the graph. At this time we have two arrays and we're ready to plot them. dataSeries contains the timestamps and song names used for hover effect dataToDisplay contains the data points for each music feature We create a loop where we add each feature as a separate trace on the same figure. We use Python's list comprehension to use in plotting where is the timestamp, is an array representing ith audio feature and is the artist and song title. dataSeries[:, 0] dataToDisplay[i] dataSeries[:, 1] Next we get the JSON representation of this graph and use Plotly JavaScript library. graphJSON = fig.to_json() This gives us the graph in its full glory. You can see the timestamps on the x axis and the data normalized on the y axis. We have 7 features for each of the 3868 tracks plotted. The full code is available on GitHub at https://github.com/dmossakowski/additive-spotify-analyzer




















![10 FinTech Trends in 2021 [Part II]](https://firebasestorage.googleapis.com/v0/b/hackernoon-app.appspot.com/o/images%2F3nhao37bBEfHA9RTQ0WNVWfXPD02-ern31d7.jpeg?alt=media&token=f48ef9e5-ec15-4bfe-93cf-9a84dfb77f84&auto=format&fit=max&w=3840)






