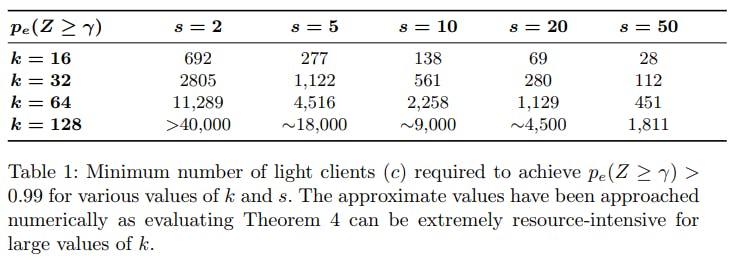
In a , I wrote a summary of a paper about Fraud Proofs written by Mustafa Al-Bassam, Alberto Sonnino, and Vitalik Buterin. They propose a secure on-chain scaling solution that gives strong security guarantees. previous article The goal of this article is verifying their results regarding the data-availability section by simulating the system. The paper uses some well-known combinatorics formulas to prove the security of the network in various setups. Since the model is probabilistic, we can make a program to simulate it. After running the simulation enough times and averaging the results, we hopefully see that we get the same results. I decided to do this not because the mathematics of the paper didn’t convince me, but because I think it would be fun to see if simulating the system would yield to the same results. Moreover, simulating the system may be another way to compute results faster than calculating a particular resource-intensive formula. In particular for populating Table 1 in the paper. Before talking about the simulation, lets first have minimal intro about the relevant part of the paper for the simulation. In a nutshell, a fraud-proof is a tool that let light-nodes receive a proof that some block is invalid. An honest full-node pack the minimum amount of information necessary to challenge the light-node to check the block and be convinced that something is wrong. Doing this in a scalable way involves making tradeoffs between proofs succinctness and real information density in the block. However, to make fraud proofs, block data is a fundamental requirement. If we don’t have the data to prove that a state transition is wrong, how could we have all the necessary information to convince another node that this happened? (For the moment forget about ). mathemagics The paper solves the data-availability problem with two fundamental ideas: Two-dimensional Reed-Solomon as erasure codes Light-nodes doing random sampling of block shares The paper combines these two ideas towards closed-formulas to calculate data-availability probabilities for some set of parameters of the network: , number of within a block. k shares , the number of shares each light-nodes try to pull from a full-node to be satisfied. s , the probability of block reconstruction made possible by light-nodes share sampling. p , the number of light-nodes necessary to satisfy in a network that is configured for and . c p k s Remember these parameters since they are used in the rest of this article. Random-sampling scheme To understand what the simulation is doing is essential to understand what means. You can find a detailed explanation of this in section 5.3 of the paper. However, here’s the main idea so you can imagine what we’re trying to do. light-nodes random sampling Given a new block, the most important interest for the honest nodes in the network is having guarantees that the block data is available. It doesn’t necessarily mean forcing each honest node to have all the shares, but just knowing that as a they could reconstruct it. team First, the light-nodes pull a random a set of shares from the new block. The light-nodes have no coordination in what shares to ask, so the possibility of many of them pulling the same shares is reasonable. As an analogy, you can think of getting pieces of a puzzle. The -nodes aren’t trying to pull the whole puzzle, just some random pieces. The -nodes are interested in the full puzzle. s light full Finally, the light-nodes interact with other full-nodes they’re connected to via . First, the light-nodes notify the full-nodes it’s connected to about the pulled shares. Keeping this running between light-nodes and full nodes, and between full-nodes and other full-nodes allows the set of honest full-node to reconstruct the whole puzzle (block data). gossiping Doing the random-sampling has many advantages: Light-nodes require small bandwidth usage since they pull a small set of shares. Light-nodes require small storage space. Full-nodes leverage light-nodes towards the mutual goal of having all the block data. Block reconstruction is decentralized. It leverages the number of light-clients available. The more light-clients, the better it performs. Using erasure codes in block data makes each extended share less important for block reconstruction, which is a essential contribution to random-sampling and gossiping goal. individually In the full picture the light-nodes an extra check. Each share comes with the Merke Proof that proves that the current share is from the block data. Since this the paper discusses a 2D coding, then this proof could be from the row or column dimension of the encoding. If we use a N dimension erasure codes, then it could be a proof of the N possible Merkle Trees from which the share lives. Simulation as a verification Generally, a is a way of doing calculations in complex systems where formal proofs are hard, or where complete computation is intractable. Its applications are so broad that I guess the term is often abused. Montecarlo method The very basic idea is using random-sampling to calculate an of the desired output of the model with the goal of, hopefully, getting close to the real mean. empirical mean We can apply the same idea to find results by simulating a probabilistic system. We run many simulations and calculate the that should match the desired real mean. As a tool of verification, we can compare the result of the simulation with the results obtained in another way, e.g., a formal proof. empirical mean However, the simulation idea is, in fact, more powerful. We could start playing with the system, tuning parameters or introducing new ideas, and quickly see how it reacts. How easy is to with the simulation depends on how resource-intensive is running a simulation instance and the minimal amount of iterations we want for calculating a empirical mean. play reliable Fraud-proof network simulation The authors of the paper analyze multiple properties of the solution using closed mathematical formulas. Most of the heavy-lifting math goes around calculating probabilities as a result of light-nodes doing a random-sampling of shares of the blocks. As a way to check those closed formulas, we could make a program that simulates the light-nodes and full-nodes behaviors, let them interact and see what happens. If we run this simulation multiple times, we could make a statistical analysis of the interesting metrics and see if they match with the closed formulas from the paper. A starting in every simulation instance makes available a new block composed of 4_k²_ shares. A number of try to pull distinct random shares from the . The full-node accept to give shares to light-nodes up to a point where he already shared 4_k²-(k+1)²_ distinct shares; this is the worst case scenario for light-nodes. full-node c light-nodes s full-node When a simulation iteration reaches a point where the full-node decides to reject the response share request, then the iteration is considered By running many iterations, we can estimate by calculating the ratio of successful iterations of a setup. successful (meaning the full-node was exposed). p The simulator is program written in Go and , anyone is invited to see the details or improving it. It has a CLI which has three commands: publicly available : verifies the results of of the paper. verifypaper Table 1 : solves for a particular setup of , and . solve c k s p : compares the Standard vs Enhanced model proposed in the paper. compare My initial motivation was only doing the first command, but after some thought and emails with Mustafa and Alberto, I decided to go a little further and implement the last two. Running the program without commands gives some helpful info about how to use the CLI interface: $ git clone https://github.com/jsign/fraudproofsim.git$ cd fraudproofsim && go get ./...$ go run main.goIt permits to compare, solve and verify fraud-proof networks. Usage:fraudproofsim [command] Available Commands:compare Compares the Standard and Enhanced modelshelp Help about any commandsolve Solves c for k, s and pverifypaper Verifies setups calculated in the paper Flags:--enhanced run an Enhanced Model-h, --help help for fraudproofsim--n int number of iterations to run per instance (default 500) Use "fraudproofsim [command] --help" for more information about a command. You can see the three mentioned commands, but also two general flags: , which allows you to choose running the network on an Enhanced model. The default is the Standard model. enhanced , is the number of iterations of the simulation within a setup to calculate the desired result. The default value is 500. n I’m going to show each command and discuss the results. All the runs are made in my laptop, and 8GB of RAM. Not really powerful hardware for running simulations. i7–4710HQ verifypaper command The idea of this command is to verify the results of Table 1 in the paper: As the footnote mentions, evaluating Theorem 4 is extremely resource-intensive: The command has baked in the setups that correspond to each case in the table. verifypaper $ go run main.go help solveIt solves c for k, s and p (p, within a threshold) Usage:fraudproofsim solve [k] [s] [p] [threshold?] [flags] Flags:-h, --help help for solve Global Flags:--enhanced run an Enhanced Model--n int number of iterations to run per instance (default 500)$ go run main.go verifypaperk=16, s=50, c=28 => p=1 37msk=16, s=20, c=69 => p=0.994 28msk=16, s=10, c=138 => p=0.988 37msk=16, s=5, c=275 => p=0.986 37msk=16, s=2, c=690 => p=0.99 63msk=32, s=50, c=112 => p=0.996 137msk=32, s=20, c=280 => p=0.994 131msk=32, s=10, c=561 => p=0.988 136msk=32, s=5, c=1122 => p=0.992 143msk=32, s=2, c=2805 => p=0.994 175msk=64, s=50, c=451 => p=0.996 464msk=64, s=20, c=1129 => p=0.996 536msk=64, s=10, c=2258 => p=0.992 510msk=64, s=5, c=4516 => p=0.988 527msk=64, s=2, c=11289 => p=0.996 679msk=128, s=50, c=1811 => p=0.992 2193msk=128, s=20, c=4500 => p=0.702 2068msexit status 2 Some notes to understand these results: Since the flag wasn’t present, the default value was used. This means each setup runs 500 times to estimate . n p Since the flag wasn’t present, a Standard model is used. Regarding verification of the paper configurations, the kind of model used isn’t relevant since the idea of the different models is to improve of the network. enhanced soundness The letters , , and have the same meaning as defined in the paper. k s c p For the configuration described in each line, the simulation runs and estimate Also, it shows how much time took to run. p. The last line of the output is the total time of the verification. In all the cases with less than 128, we see that the estimated is always close to .99. This means that the simulation results agree with the ones of Table 1. k p For we wee that isn’t always close to 0.99. For s=50, we can see that we have good results, but for other values, we have lower probabilities than expected. This result is reasonable since the table gave some approximate results. I left these setups intentionally optimistic to see that the value is coherent. k=128 p p So these results are great since we can safely say that the results of the simulation match the results obtained by the paper using the closed formulas. Moreover, we can see that the running times for each setup is quite short, which is nice too. Instead of fixing and calculating , we can use the command as I’ll show below. c p solve solve command Generally, verifying results is cheaper than finding them. The above tries to verify for , and . But we could also populate by solving for , and . This is what the command does. verifypaper p k s c Table 1 c k s p solve In particular, it finds doing a binary-search in some reasonable domain space. For each candidate , is estimated. Depending if the is greater or lower than the , the value of is . c c p estimated p desired p c binary-searched $ go run main.go help solveIt solves c for k, s and p (p, within a threshold) Usage:fraudproofsim solve [k] [s] [p] [threshold?] [flags] Flags:-h, --help help for solve Global Flags:--enhanced run an Enhanced Model--n int number of iterations to run per instance (default 500) If we see in , for and and the value of c is 2258. Let’s for this setup and see what happens: Table 1 k=64 s=10 p=.99 solve $ go run main.go solve 64 10 .99 0.005Solving for (k:64, s:10, p:0.99, threshold:0.005)[1, 16384]: c=8192 p=1[1, 8192]: c=4096 p=1[1, 4096]: c=2048 p=0[2048, 4096]: c=3072 p=1[2048, 3072]: c=2560 p=1[2048, 2560]: c=2304 p=1[2048, 2304]: c=2176 p=0.002[2176, 2304]: c=2240 p=0.902[2240, 2304]: c=2272 p=1[2240, 2272]: c=2256 p=0.994Solution c=2256 with p=0.994 (4900ms) In each line we can see: shows where are we standing in the current step of the binary-search. [a,b] is the proposal being evaluated. c is the estimated result of the desired we’re looking for p p As we can see, we found a value of quite close to the exact result. The parameter is used to solve for within a range. c threshold p Let’s try with a smaller threshold and a lot more iterations for calculations: $ go run main.go solve 64 10 .99 0.0001 --n 2000Solving for (k:64, s:10, p:0.99, threshold:0.0001)[1, 16384]: c=8192 p=1[1, 8192]: c=4096 p=1[1, 4096]: c=2048 p=0[2048, 4096]: c=3072 p=1[2048, 3072]: c=2560 p=1[2048, 2560]: c=2304 p=1[2048, 2304]: c=2176 p=0.0025[2176, 2304]: c=2240 p=0.8955[2240, 2304]: c=2272 p=0.9995[2240, 2272]: c=2256 p=0.9885[2256, 2272]: c=2264 p=0.9955[2256, 2264]: c=2260 p=0.9945[2256, 2260]: c=2258 p=0.992[2256, 2258]: c=2257 p=0.994[2256, 2257]: c=2256 p=0.9865[2256, 2257]: c=2256 p=0.9915Solution c=2256 with p=0.9915 (31346ms) The found solution is the same, but we can see that the total running time is greater. The reason for this is twofold: Since is greater, each simulation for the candidate takes more time. n c Since is smaller, the binary search goes further in getting close to 0.99. threshold Now we’ll try to calculate the estimated solution for the >40000 scenario in the : Table 1 $ go run main.go solve 128 2 0.99 0.005Solving for (k:128, s:2, p:0.99, threshold:0.005)[1, 65536]: c=32768 p=0[32768, 65536]: c=49152 p=1[32768, 49152]: c=40960 p=0[40960, 49152]: c=45056 p=0.796[45056, 49152]: c=47104 p=1[45056, 47104]: c=46080 p=1[45056, 46080]: c=45568 p=1[45056, 45568]: c=45312 p=1[45056, 45312]: c=45184 p=0.956[45184, 45312]: c=45248 p=0.976[45248, 45312]: c=45280 p=0.998[45248, 45280]: c=45264 p=0.986Solution c=45264 with p=0.986 (34220ms) Good, pretty in line with the Table 1 estimation. Let’s force the simulation to find a solution for a that doubles the biggest analyzed in the paper, and a number that makes the worst-case scenario for : k s k $ go run main.go solve 256 2 0.99 0.005Solving for (k:256, s:2, p:0.99, threshold:0.005)[1, 262144]: c=131072 p=0[131072, 262144]: c=196608 p=1[131072, 196608]: c=163840 p=0[163840, 196608]: c=180224 p=0.076[180224, 196608]: c=188416 p=1[180224, 188416]: c=184320 p=1[180224, 184320]: c=182272 p=1[180224, 182272]: c=181248 p=0.964[181248, 182272]: c=181760 p=1[181248, 181760]: c=181504 p=0.994Solution c=181504 with p=0.994 (142453ms) We can see that we found the solution in some reasonable time 2min and 22s. Alberto confirmed that these times are several of orders faster than computing for in the paper. Theorem 4 Table 1 compare command The paper put discuss the property of the solution. This means, understanding if any light-nodes would complete pulling their shares before being alerted of a data unavailability problem. soundness As a summary, the Standard models allows the full-node to recognize which light-node is asking for each share. Thus, full-node is able to select which light-nodes to reply to satisfy the maximum possible number of light-nodes. The Enhanced model implies not allowing the full-node to recognize which light-node is asking for each share. Thus, the full-node can’t have certainty about how many full-nodes are close to being satisfied. In the simulation, each time the full-node receive a share request it has the option to accept or reject the request. If the latter happens, then the full-node is considered malicious, meaning that it probably has intentions of making data unavailable. When simulating with the Standard Model, the light-nodes run serially. This model the worst-case scenario for the light-nodes because it violates as much as possible. The first light-nodes, each asking for shares, produce a total of share request. While this number is small enough compared with the full-node rejection criteria, then all appear to run smoothly. However, when comes to the critical point close to , then the full-node probably reject start rejecting requests_._ c soundness z s z*s z c On the other hand, when the simulation run in Enhanced Model, a random light-node is elected to ask for the next share. Since the light-nodes are selected randomly, on average they all progress evenly in their journey of asking for their corresponding shares. Thus, fewer of them will complete their journey before someone noticing the data-unavailability. s To understand this better we have the command. This command compares the two models for a and setup for various . For each simulation, it calculates how many light-nodes finished asking their shares before the full-node makes a rejection. compare k s c s It automatically generates a plot as a file to understand the results: png $ go run main.go help compareCompares Standard and Enhanced model to understand their impact on soundness Usage:fraudproofsim compare [k] [s] [#points] [flags] Flags:-h, --help help for compare Global Flags:--enhanced run an Enhanced Model--n int number of iterations to run per instance (default 500) The parameter is the number of points we want to generate to make the interpolation. #points Let’s compare for a setup: $ go run main.go compare 64 10 25Solving c for (k: 64, s: 10) with precision .99+-.005:[1, 16384]: c=8192 p=1[1, 8192]: c=4096 p=1[1, 4096]: c=2048 p=0[2048, 4096]: c=3072 p=1[2048, 3072]: c=2560 p=1[2048, 2560]: c=2304 p=1[2048, 2304]: c=2176 p=0[2176, 2304]: c=2240 p=0.896[2240, 2304]: c=2272 p=0.998[2240, 2272]: c=2256 p=0.99Found solution c=2256, now generating 25 points in [.50*c,1.5*c]=[1128, 3384]:0%3%7%11%15%19%23%27%31%35%39%43%47%51%55%59%63%67%71%75%79%83%87%91%95%99%Plotted in plot.png The first thing it does is to solve for for a . This is done in order to plot for values of within .50 and 1.5 of . Let’s see the generated : c p=.99 c c plot.png The result of the compare command for k=64 and s=10 Interesting! For values of lower than the one for .99 guarantee, we see that both the Standard and Enhanced model have the same result. All the light-nodes finish asking their shares successfully even when the full block isn’t guaranteed to be available. This is reasonable; thinking an extreme case of then it’s evident that asking only for shares will be successful. c s c=1 s When we reach and exceed the critical point of (=.99) light-nodes something interesting happens. c In the Standard model, if we keep adding light-nodes, the total number of light-nodes is bounded. This sound reasonable since shares where already asked and the full-node is pretty doomed to reject any more share request if interested in making the block unavailable. This means that no more light-nodes can be tricked. fooled c*s In the Enhanced-model we see something different. The more light-nodes we add from , the less total light-nodes finished asking for their shares. Since each share request the full-node receives comes from a random light-node, when the full-node reaches the critical point of share rejection not many light-nodes have yet finished asking their shares. The light-nodes evenly. c s share the risk If the network has more than the minimum amount of light-nodes, then rapidly fewer and fewer light-nodes complete pulling their shares before someone finds out that the full-node is malicious and alert the rest of the network. c s For other setups, we see the same shape. Intuitively we expect that will have some influence on how fast the Enhanced model improves soundness. Let’s check this intuition. s With the same and a bigger (also more calculated points which don’t affect anything but the plot interpolation): k=64 s $ go run main.go compare 64 50 50Solving c for (k: 64, s: 50) with precision .99+-.005:[1, 16384]: c=8192 p=1[1, 8192]: c=4096 p=1[1, 4096]: c=2048 p=1[1, 2048]: c=1024 p=1[1, 1024]: c=512 p=1[1, 512]: c=256 p=0[256, 512]: c=384 p=0[384, 512]: c=448 p=0.93[448, 512]: c=480 p=1[448, 480]: c=464 p=1[448, 464]: c=456 p=1[448, 456]: c=452 p=0.998[448, 452]: c=450 p=0.978[450, 452]: c=451 p=0.992Found solution c=451, now generating 50 points in [.50*c,1.5*c]=[225, 676]:0%1%3%...97%99%Plotted in plot.png And the plot: Result of the compare command for k=64 and s=50 Yes!, a bigger in the Enhanced Model is much more aggressive in the soundness guarantee in respect of . s c Finally, let’s see for a smaller s: $ go run main.go compare 64 2 50Solving c for (k: 64, s: 2) with precision .99+-.005:[1, 16384]: c=8192 p=0[8192, 16384]: c=12288 p=1[8192, 12288]: c=10240 p=0[10240, 12288]: c=11264 p=0.97[11264, 12288]: c=11776 p=1[11264, 11776]: c=11520 p=1[11264, 11520]: c=11392 p=1[11264, 11392]: c=11328 p=0.998[11264, 11328]: c=11296 p=0.994Found solution c=11296, now generating 50 points in [.50*c,1.5*c]=[5648, 16944]:0%1%3%5%...97%99%Plotted in plot.png Result for the compare command for k=64 and s=2 We can appreciate that with a smaller , is guaranteed much slower. s soundness Running times and bottlenecks The running times of the simulation depend on three factors: , , and the . s k c number of iterations I profiled the code using multiple times to find where is the bottleneck in the simulation. It turns out that the bottlenecks are when the light-nodes decides which shares to ask from the shares. I’ve made multiple implementations of this particular part to improve the running times. pprof s 4k² As a summary, I noticed a locking-contention issue within the default library. After some research, already noticed that within standard-library there’s a mutex; something quite reasonable when using a singleton random seed for a concurrent library. rand other people rand Then I decided that each light-node would make their random seed to avoid locking-contention between different goroutines. After another , I found out that this was quite computer-expensive; better than the original lock-contention, but expensive. Concurrency in the simulation is at the iteration level, so generating a random-seed for each operation instead of light-nodes made a significant improvement. pprof Profiling the code and finding these things was fun too. Maybe I explain all this in more detail in a further article. Possible Improvements There’re a bunch of things that could be improved/enhancements in the simulation. Domain-size and binary-search for solve command In the command, I do a binary search for until the explored domain is exhausted or the desired lies within a chosen . There may be other ways of implementing the command or reducing the domain of search. solve c p threshold solve Full-node decision-making for share request rejection The full-node make the first share request rejection when 4_k²-(k+1)²_ were shared. That number corresponds to the number of shares the full-node could give and still make the block unavailable. maximum This is the best-case scenario for full-nodes where the light-nodes ask for a particular subset of shares. Since the data is encoded in 2D-Reed-Solomon, each unavailable share could be reconstructed from a row or column point of view. This full-node happens when the unshared shares always are in the rows and columns still unrecoverable from the block. In other words, unshared shares contribute to block unavailability. best-case as much as possible This implies that the simulation is pessimistic, so lies on the of the claims it makes. Saying it differently, most of the times the block will be recoverable even when the simulation continues considering it isn’t. safe-side This aspect of the simulation could be improved if each time the full-node makes a new share available, it calculates what remaining shares are unrecoverable since they can’t still be reconstructed with the already shared shares using the 2D Reed-Solomon encoding. After the last unrecoverable share is shared, the full-node can be considered . Notice that unrecoverable and unshared are different things. An unshared share could be reconstructed if enough shares of its column or row are available. doomed Running time and memory usage The simulation already has some moderate optimizations result of multiple profilings. Since the simulation is cpu-bound and it only needs enough random seeds depending on the number of cores in the CPU to avoid locking-contention issues, the method could be improved. pprof Simulation.Init() Also, there could be a better solution to generate the random subset of distinct elements of a set of 4_k²_ elements (shares to pull). The actual solution is nice since it exploits the fact that is much smaller than s s (2k)². I’ve made no memory profiling, so I’m convinced there are many things to be improved in this direction. Simulation configuration scan The simulation configurations in the simulation are fixed and correspond to the ones proposed in the paper. This could be easily changed, and be useful to search for a configuration that matches some required criteria. Mustafa suggested that may be interesting to include network bandwidth usage or latency. In the same vein, we could scan for network configurations that optimize or establish bounds of these metrics within some minimum security requirements. The possibilities are broad, and we could play a lot with it. Explore other possible codings and their impact on results Another idea mentioned by Mustafa was considering the impact on the network when using other codings for the block data. For example, adding more dimensions with Reed-Solomon, or using even other codings. Conclusion The simulation verified the mathematical calculations in the paper and provided a way several orders of magnitude faster to estimate values of the model than computing the closed-mathematical formula. Finally, it helps to get better intuition on how the Standard and Enhanced model impacts the property of the system. soundness Further work could be done to improve the simulation in various directions. Finally, I’d like to thank both Mustafa and Alberto for their opinions and suggestions. Special thanks to Mustafa for various ideas for the article, and kindly reviewing a draft.