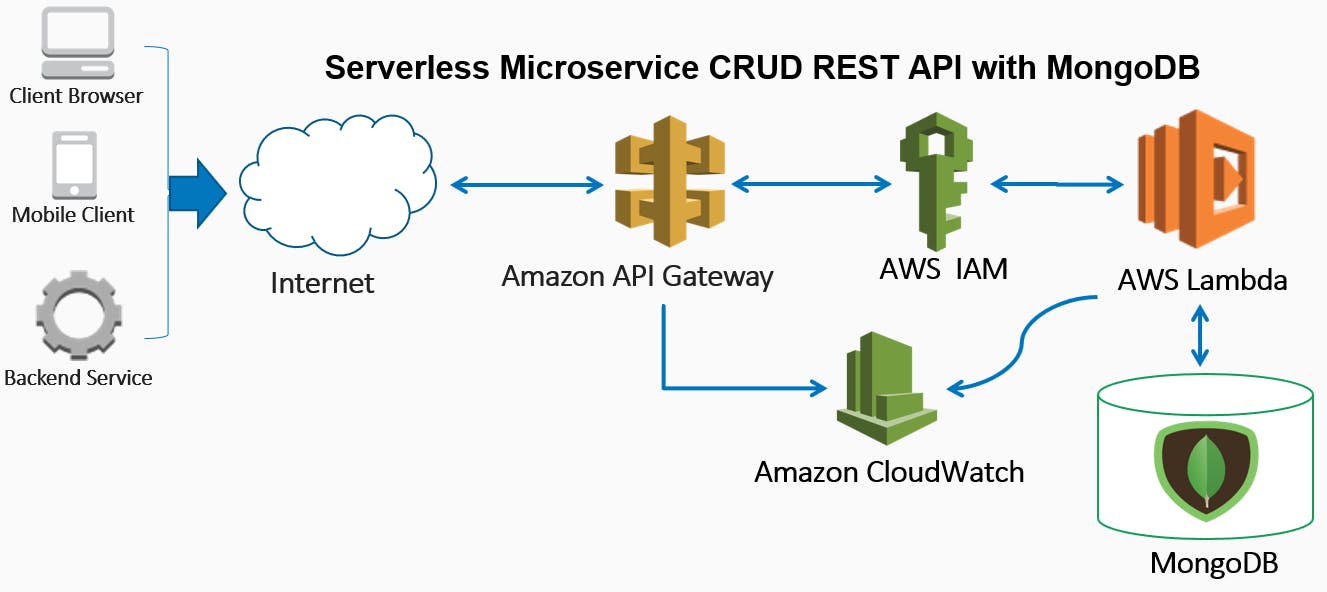
In modern microservice architectures, it’s common to create RESTful data service application programming interface (API) when sharing data with other systems such as visualisations, user interfaces, or even integrating with other 3rd parties. There are many architecture, infrastructure and development complexities to consider in the creation, maintenance and monitoring of such systems. In addition, you need to consider costs, and the scalability of the API and data store. We are moving away from the large and complex monolithic architectures that are hard to scale to Microservices architectures. For example, you could have a loosely coupled fleet of microservices each with an API for each data source, integrating with a clustered NoSQL database, such as Cassandra. Adopting Microservices architecture typically means that you need a DevOps team that, for example, setup, monitor and maintain the continuous integration / continuous deployment (CI/CD) pipelines, container-orchestration platform and monitoring systems. Things are looking better recently as AWS has announced and that help with Kubernetes, but there is still a lot of integration that needs to be built by developers and containers configuration to think about. Kubernetes Amazon Elastic Container Service for Kubernetes (EKS) AWS Fargate Back in 2014, AWS launch Lambda functions which act as integration glue between services where you only need to write the business logic code to respond to inbound events. These events could be an GET request from API Gateway, new records added to a Kinesis Streams or an object put into S3. Using Lambda has been very popular as they are stateless, have built in event source integration and you only pay per 100ms of execution time. So rather than use a fleet of Microservices running on containers, you can build a highly scalable Serverless stack integrating API Gateway, Lambda and DynamoDB. There are many tutorials on this including my first . video course Serverless & Lambdaless RESTful Data API In this blog post, I show you how to loose the Lambda altogether and have API Gateway directly invoke DynamoDB, to create a full suite of create, read, update, and delete (CRUD) operations. Other posts I’ve read only cover how to partially do this manually in the AWS console and not in code using and , which is what I will show you here. Using Swagger and SAM to deploy the infrastructure and API is realistically what you absolutely want to do to release it to a production environment for minimising human error, repeatability and scalability. Swagger SAM Overview I assume you already have an and . I’m using Ubuntu bash with some shell scripts, for watch out for the . AWS Account setup AWS CLI installed Windows 10 users install Linux Bash Shell Windows carriage returns that need to be removed when running a script within Linux I first create environment variables and an IAM Role with policies using AWS CLI. I do this so they remain in place even if I delete the CloudFormation stack and so they can be reused by other APIs. I then construct a SAM template to create a DynamoDB table and the POST, PUT, GET, and DELETE API methods, which I deploy via CloudFormation. Finally, I test the API methods, to ensure they are working as expected. Creating variables First let’s create a containing your environment specific details. common-variables.sh #!/bin/shexport profile="demo"export region="eu-west-1"export aws_account_id="000000000000"export template="apigateway-dynamo" These will be used for the AWS CLI commands I will run later. Security Create the IAM Roles and Policies In order for API Gateway to push logs to CloudWatch and for it to access DynamoDB you need to create a role with two policies. You can do this in the AWS Console or AWS CLI. I’ve done it in code using the AWS CLI and that is what I recommend for repeatability and to avoid errors. Also, you never know if someone deletes policies by mistake, then you need to retrace your JSON policy steps which is not something you want to do if you have 100s of policies and are under pressure with a live system! Let’s call the API Gateway role , create the role using the trust relationship, then attach the service role for cloudWatch and then create the DynamoDB role and attach it. api-gateway-dynamo-full-user-vists I have created a shell script you can invoke , make sure you run to make it executable. Here are the contents of the script ./create-role.sh chmod + x #!/bin/sh. ./common-variables.sh#Setup API Gateway Rolerole_name=api-gateway-dynamo-full-user-commentsaws iam create-role --role-name ${role_name} \ --assume-role-policy-document file://../../IAM/assume-role-api-gateway.json --profile $profile#Add Policy for API Gateway to write to logsrole_policy_arn="arn:aws:iam::aws:policy/service-role/AmazonAPIGatewayPushToCloudWatchLogs"aws iam attach-role-policy \ --role-name "${role_name}" \ --policy-arn "${role_policy_arn}" --profile ${profile}#Create DynamoDB Policypolicy_name="dynamo-full-user-visits-api"aws iam create-policy --policy-name ${policy_name} --policy-document file://../../IAM/dynamo-full-user-comments.json --profile ${profile}#Attach Policy for API Gateway to access DynamoDBrole_policy_arn="arn:aws:iam::${aws_account_id}:policy/${policy_name}"aws iam attach-role-policy \ --role-name "${role_name}" \ --policy-arn "${role_policy_arn}" --profile ${profile} The trust relationship. assume-role-api-gateway.json { "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "apigateway.amazonaws.com" }, "Action": "sts:AssumeRole" } ]} The allowing API Gateway full CRUD access to DynamoDB table dynamo-full-user-comments.json { "Version": "2012-10-17", "Statement": [ { "Sid": "Stmt1422032676021", "Effect": "Allow", "Action": [ "dynamodb:DeleteItem", "dynamodb:DescribeTable", "dynamodb:GetItem", "dynamodb:PutItem", "dynamodb:Query", "dynamodb:Scan", "dynamodb:UpdateItem" ], "Resource": [ "arn:aws:dynamodb:eu-west-1:000000000000:table/user-comments-api-sam"] }, { "Effect": "Allow", "Action": "dynamodb:ListTables", "Resource": "*", "Condition": {} } ]} I have a shell script you can invoke with that runs all these scripts to setup the IAM Role and policies. ./create-role.sh Create the Parameters and DynamoDB table Create a YAML template file called we will be appending the parameters, DynamoDB config and later on the API methods. Here are the set of parameters:. apigateway-dynamo.yaml Parameters: Table: {Default: user-comments-api-sam, Type: String} AccountId: {Default: 000000000000, Type: String} RoleName: {Default: api-gateway-dynamo-full-user-comments, Type: String} Lets then create a DynamoDB table using SAM and call it which is a name I will reuse further down the script as a parameter. I then create the table with serverside encryption, and with hash or primary key called and set the read and write throughput to 1. I do this to keep it in the , but you can easily change this as you need to scale out. user-comments-api-sam PageId free tier Resources: DynamoDBTable: Type: AWS::DynamoDB::Table Properties: TableName: !Ref Table SSESpecification: SSEEnabled: True AttributeDefinitions: - AttributeName: PageId AttributeType: S KeySchema: - AttributeName: PageId KeyType: HASH ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1 PUT Method Let’s start by adding some JSON data to DynamoDB using the PUT method of our API. I’m using to define a collection of Amazon API Gateway resources and methods that can be invoked through HTTPS endpoints. Type: AWS::Serverless::Api MyApi: Type: AWS::Serverless::Api Properties: StageName: Prod DefinitionBody: swagger: 2.0 info: title: Ref: AWS::StackName paths: "/visits": put: consumes: - "application/json" produces: - "application/json" responses: "200": description: "200 response" schema: $ref: "#/definitions/Empty" x-amazon-apigateway-integration: httpMethod: POST type: AWS uri: { "Fn::Sub": "arn:aws:apigateway:${AWS::Region}:dynamodb:action/PutItem" } credentials: { "Fn::Sub": "arn:aws:iam::${AccountId}:role/${RoleName}" } requestTemplates: application/json: { 'Fn::Sub': "{ \n\ \t\"TableName\": \"${Table}\",\n\ \t\"Item\": {\n\ \t\t\"PageId\": {\n\ \t\t\t\"S\": \"$input.path('$.PageId')\"\n\ \t\t},\n\ \t\t\"EventCount\": {\n\ \t\t\t\"N\": \"$input.path('$.EventCount')\"\n\ \t\t},\n\ \t\t\"Message\": {\n\ \t\t\t\"S\": \"$input.path('$.Message')\"\n\ \t\t}\n \t}\n}" } responses: default: statusCode: "200" Here I use built in variables like for the region, but also parameters that are specified earlier at the top of this script. ${AWS::Region} I’m following the PUT convention by making it idempotent, meaning that if you call it several times it will result in the same operation. Here we will simply overwrite the existing row with the passed JSON body. I use the action to do this and you can see in the that I parse the JSON and map them into DynamoDB keys and values. The keys and values are then put into a DynamoDB table which is replaced with using the parameters at the top of the script . You will also notice that the and have been reformatted to make it easier to understand. PutItem requestTemplates ${Table} user-comments-api-sam Table: {Default: user-comments-api-sam, Type: String} \t \n GET Method Now that I have some data I want to retrieve it from DynamoDB. I use a GET Method that allows you to fetch the specified data from DynamoDB. Unlike the PUT method, I use a resourceId rather than the JSON body to do this. Here I pass into API Gateway as a URL parameter. {PageId} paths: "/visits/{PageId}": get: consumes: - "application/json" produces: - "application/json" responses: "200": description: "200 response" schema: $ref: "#/definitions/Empty" x-amazon-apigateway-integration: httpMethod: POST type: AWS uri: { "Fn::Sub": "arn:aws:apigateway:${AWS::Region}:dynamodb:action/Query" } credentials: { "Fn::Sub": "arn:aws:iam::${AccountId}:role/${RoleName}" } requestTemplates: application/json: { 'Fn::Sub': "{ \n\ \t\"TableName\": \"${Table}\",\n\ \t\"KeyConditionExpression\": \"PageId = :v1\",\n\ \t\"ExpressionAttributeValues\": {\n\ \t\t\":v1\": { \n\ \t\t\t\"S\": \"$input.params('PageId')\"\n\ \t\t}\n\ \t}\n}"} responses: default: statusCode: "200" responseTemplates: application/json: "#set($inputRoot = $input.path('$'))\n\ {\n\ \t\"comments\": [\n\ \t\t#foreach($elem in $inputRoot.Items) {\n\ \t\t\t\"PageId\": \"$elem.PageId.S\",\n\ \t\t\t\"Message\": \"$elem.Message.S\",\n\ \t\t\t\"EventCount\": \"$elem.EventCount.N\"\n\ \t\t}#if($foreach.hasNext),#end\n\ \t#end\n\ \t]\n}" You will see that uses the to create a . If data matches the query then it is returned and passed through the , which transforms it from the native DynamoDB format to a more stand JSON format. requestTemplates PageId DynamoDB Query responseTemplates POST Method I have shown how to do an idempotent PUT, now let’s look at a more complex update that increments a counter by the specified value each time it is invoked. This could be very useful for persisting leaderboards scores, metrics or transactions. post: consumes: - "application/json" produces: - "application/json" responses: "200": description: "200 response" schema: $ref: "#/definitions/Empty" x-amazon-apigateway-integration: httpMethod: POST type: AWS uri: { "Fn::Sub": "arn:aws:apigateway:${AWS::Region}:dynamodb:action/UpdateItem" } credentials: { "Fn::Sub": "arn:aws:iam::${AccountId}:role/${RoleName}" } requestTemplates: application/json: { 'Fn::Sub': "{\n\t\"TableName\": \"${Table}\",\n\ \t\"Key\":{\n \t\t\"PageId\": {\n \t\t\t\"S\": \"$input.path('$.PageId')\"\n\ \t\t}\n\ \t},\n\ \t\"ExpressionAttributeValues\": {\n\ \t\t\":event_count\": {\n\ \t\t\t\"N\": \"$input.path('$.EventCount')\"},\n\ \t\t\":message\": {\n\ \t\t\t\"S\": \"$input.path('$.Message')\"}\n\ \t},\n\ \t\"UpdateExpression\": \"ADD EventCount :event_count SET Message = :message\",\n\ \t\"ReturnValues\": \"ALL_NEW\"\n}"} responses: default: statusCode: "200" Again I use the to form a query, extracting different values from the JSON body using . I think one of the best features of DynamoDB is the rich for updates. Here I use which performs a non-locking update of the value already in DynamoDB. The beauty is that the read and update is done as an atomic action using an UpdateExpression, no need to mess around and retry on the client side! I also want to show to outcome of the call, so I return it using . requestTemplates $input.path() expressions language available "UpdateExpression\": \"ADD EventCount :event_count EventCount "ReturnValues\": \"ALL_NEW\" DELETE Method Finally, I want to be able to delete specific records in DynamoDB, so I use the action where I pass in the as a URL parameters. PageId DeleteItem PageId delete: `consumes: - "application/json" produces: - "application/json" parameters: - name: "PageId" in: "path" required: true type: "string" responses: "200": description: "200 response" schema: $ref: "#/definitions/Empty" x-amazon-apigateway-integration: credentials: { "Fn::Sub": "arn:aws:iam::${AccountId}:role/${RoleName}" } uri: { "Fn::Sub": "arn:aws:apigateway:${AWS::Region}:dynamodb:action/DeleteItem" } requestTemplates: application/json: { 'Fn::Sub': "{ \n\ \t\"TableName\": \"${Table}\",\n\ \t\"Key\": {\n\ \t\t\"PageId\": {\n \t\t\t\"S\": \"$input.params('PageId')\"\n\ \t\t}\n\ \t},\n\ \t\"ConditionExpression\": \"attribute_not_exists(Replies)\",\n\ \t\"ReturnValues\": \"ALL_OLD\"\n}" } responses: default: statusCode: "200" passthroughBehavior: "when_no_match" httpMethod: "POST" type: "aws"` definitions: Empty: type: "object" title: "Empty Schema" Here I want to see what is deleted so I’ve included . At the end of the script we have and Empty Schema that is referred thought the YAML file. "ReturnValues\": \"ALL_OLD\" Deploying the API Life is much easier and quicker, now that I don’t even need any Lambda code, or package the Lambda and dependencies as a Zip file. All I need to do is to deploy the stack using the code and config in and that's it! apigateway-dynamo.yaml Serverless & Lambdaless RESTful Data API Deployment $ aws cloudformation deploy --template-file $template.yaml --stack-name $template --capabilities CAPABILITY_IAM --region $region --profile $profile This is very easy to add into any CI/CD pipeline step too. Testing the API Now that you understand how to built the API, lets manually test if it is working as expected. Logon to the AWS console > API Gateway or you can also use browser plugins like postman for this. Testing the PUT Method or Create As you have no data in DynamoDB yet, let’s start by adding some. Open the API Gateway On the navigation pane, choose apigateway-dynamo and Resources In Resources Click on Put Under /visits — PUT — Method Execution click on Test In “Request Body” enter the following JSON {"PageId": "444","EventCount": 1,"Message": "happy"} Scroll down and click on the Test button. You will see on the right (or under on mobile devices) Status: 200 which means the call was successful and see a response body. You will also see full API logs, which are useful for testing and debugging. These are also stored in CloudWatch logs, which is the first place you need to look at if you start getting 4XX or 5XX errors. Testing the GET method Now that you have a record in DynamoDB, let’s retrieve it using a PageId = 444 query. In resources Click on Put Under /visits/{PageId} — GET — Method Execution click on Test In Path for {PageId} enter 444 OR in Query Strings for {PageId} enter PageId=444 Click on the Test button. You should get a status: 200 and also see the following Response Body which is what we expect { "comments": [ { "PageId": "444", "Message": "happy", "EventCount": "1" } ]} Testing the POST Method With the PUT method, you saw that the value remains constant no matter how many times you call it. Now let's test the POST method that increments a counter by the specified value each time it is called. EventCount In Resources Click on Post Under /visits — POST — Method Execution click on Test In “Request Body” enter the following JSON {"PageId": "444","EventCount": 1,"Message": "happy"} You should get a status: 200 and also see the following Response Body "comments": [ { "PageId": "444", "Message": "happy", "EventCount": "2" } ]} Run it several times and you will see EventCount increment, you can also increment it by more than 1 if you modify the request JSON body EventCount value. Why does this POST method return the current value? It’s down to the config as I wanted to show you the effects of the POST without having to go to the DynamoDB console! "ReturnValues\": \"ALL_NEW\" Testing the DELETE Method Now that you have a lot of data, maybe you need to delete some records. In resources Click on Delete Under /visits/{PageId} — DELETE — Method Execution click on Test In Path for {PageId} enter 444 OR in Query Strings for {PageId} enter PageId=444 Click on the Test button. You should get a status: 200 and also see the a Response Body of the deleted record, I used the . "ReturnValues\": \"ALL_OLD\" To double check you can have a look at the DynamoDB in the AWS Console Open the DynamoDB Console Under the navigation click on Tables Under name click on user-comments-api-sam On the tab click on Items You should see the record is no longer there, you can also use the Query drop down to check. Clean up To delete the stack simply run here are the contents of the shell script: ./delete-stack.sh $ aws cloudformation delete-stack --stack-name $template --region $region --profile $profile Analysis and Conclusion Well done on completing the steps to a creating a serverless data API! The full source code will be available shortly on my GitHub repo Next steps: As a good starting point, create the API in AWS Console and then Export the YAML Use environment variables and parameters where possible Decouple IAM Roles and policies from SAM template The disadvantages of my Lambdaless approach: If CloudFormation is a no go can be more complex with AWS CLI CloudFormation notation is verbose and strange to me, e.g. and don't feel friendly or intuitive! { 'Fn::Sub': [...] } if($foreach.hasNext),#end Complex pagination and exception handling more complex due to CloudFormation notation over the likes of Node.js or Python How to unit test the API Integration Request and response in the yaml? The advantages of my Lambdaless approach: No Lambda cold starts, faster than having a Lambda in between Simpler and less code — no Python or Node.js Zip package needed, all config in one YAML file! Swagger and SAM — very fast and easy to deploy, easy to use in CI/CD Have API Gateway Logging and Monitoring in CloudWatch Finally, not everything can be done with this Lambdaless approach but Serverless computing can be used in most scenarios. If you want to find out more on Serverless microservices and have more complex use cases, please have a look at my video courses and so support me in writing more blog posts. For beginners and intermediates, the , configuration and detailed walk throughs full Serverless Data API code For intermediate or advanced users, I cover the implementation of with over 7h of original content, code, configuration and detailed walk throughs making it one of the most complete serverless microservices video courses out there! 15+ serverless microservice patterns Feel free to connect with me on or message me for comments. LinkedIn