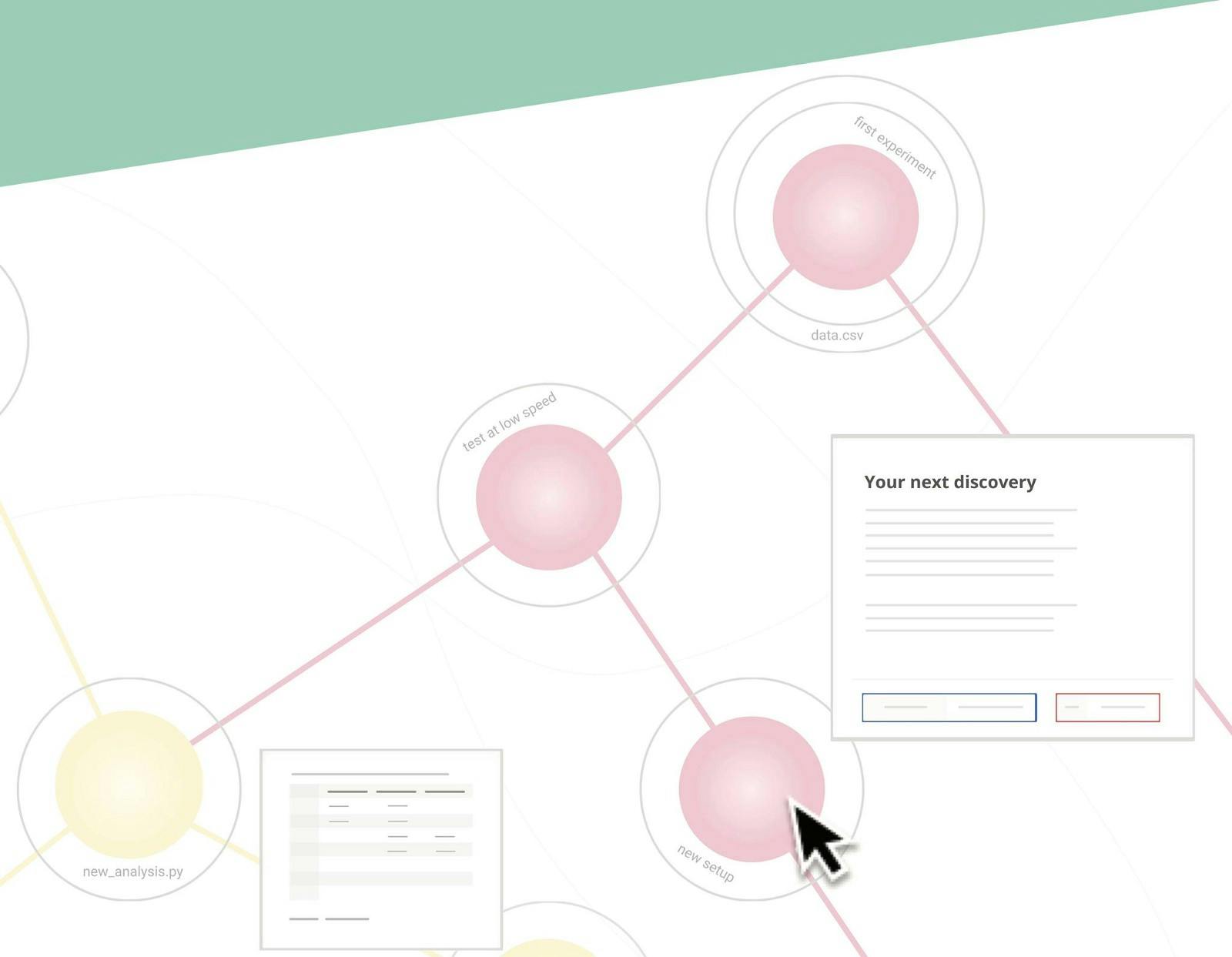
Exploring data to gain knowledge, from biology to , can broadly be called . A lot has been written about why research needs to get its act together when it comes to documentation. Of course, there are good reasons to call for an end to the paper notebook: No backup, no search, no sharing. But even fully digital domains like machine learning suffer from a . It is extremely hard in all domains of research to understand what exactly lead to a particular result. data-science research reproducibility crisis Relationships matter as much as content There is a deeper problem: The traditional ways of storing and documenting research do not model the workflow very well. A notebook organizes the notes only linearly, in the order they were taken. A file folder structure, only allows files to be associated with their file name, folder name, and the other files in the same folder. However, research is different. Different paths are being explored sometimes at the same time, and it is not immediately clear what the right folder for a file would be. Files would have to live in different folders at the same time. Notebooks would have to be ripped apart and re-assembled constantly. For data to become knowledge, the relationships between the data artefacts are as meaningful as the data itself. Graphs to the rescue The natural way to model the reality of research is a directional graph. Starting from a single atom of knowledge, like a first measurement, or a first look at the data, one makes a new decision based on that and creates more data. Both steps in the process can be interpreted as a node and their causal relationship as an edge. If a particular path does not work out, one goes back to the last thing that worked and tries out something new and creates a new branch, or several new paths emerge from a result and branch off. Several intermediate results from different projects may also be combined and create more graphs. Store, structure, and document in a graph As the massive success of graph databases has shown, it makes sense to store data in a way that models their relationships. Research data is no different. Storing, structuring, and documenting research in a graph, makes it easy to understand where results came from and what they lead to. It gives the researchers a way to quickly gain an overview of what happened, without having to go through folders or re-create the workflow in their heads based on headlines in notebooks or referenced filenames. Instead of just taking notes, they build a knowledge base on the go which can be understood and re-used later by themselves or their colleagues. Check out how we at amie are documenting research as a graph: and how it can be . amie.ai used
















![What Are Convolution Neural Networks? [ELI5]](https://hackernoon.imgix.net/images/69s32rn.jpg?auto=format&fit=max&w=3840)











