
4,297 reads
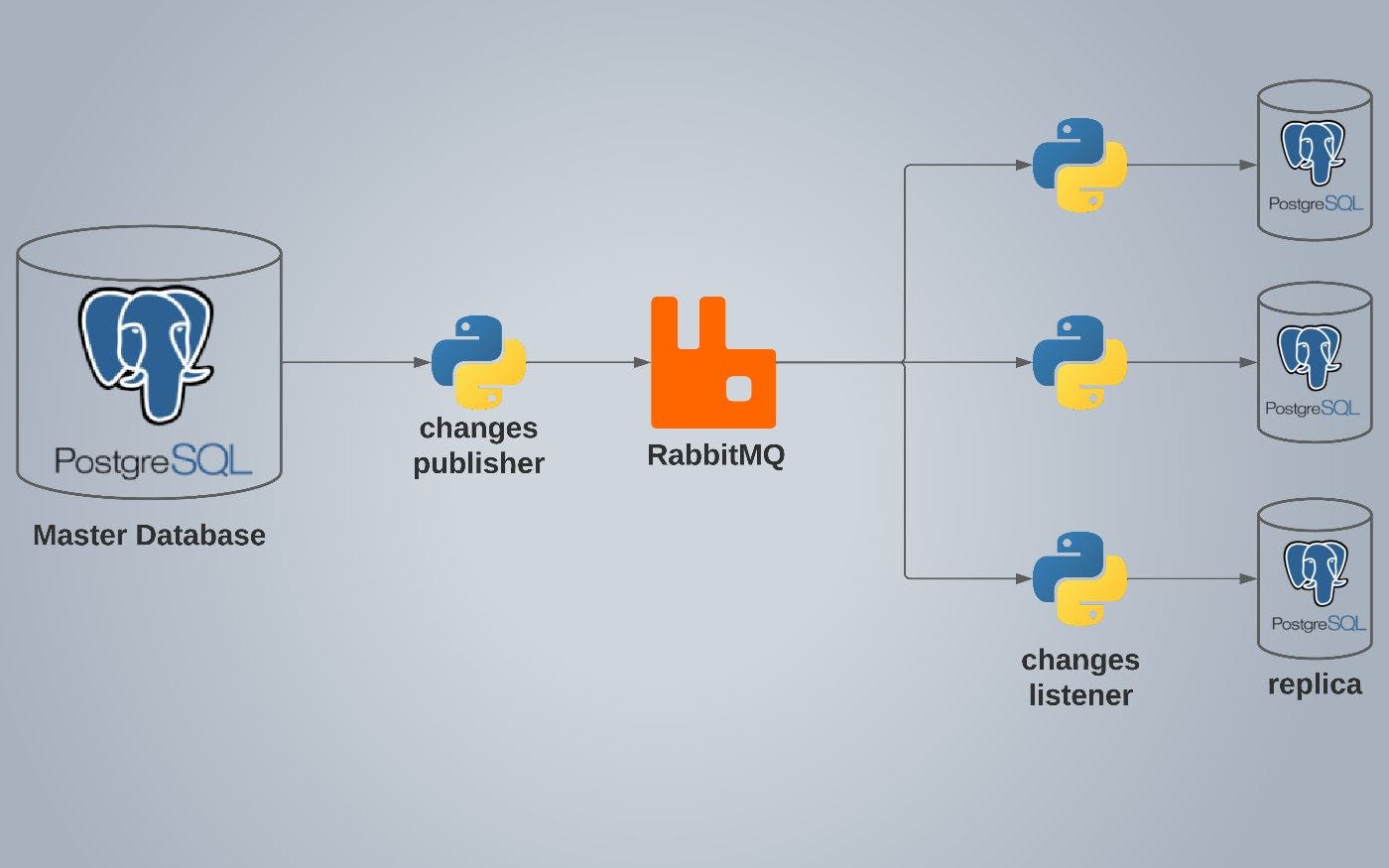
Replicate PostgreSQL Databases Using async Python and RabbitMQ for High Availability
by bybechir@bechir
bybechir@bechir
Software engineering student from Tunisia. Passionate about data engineering, deep learning and solutions architecture.
May 5th, 2022





Software engineering student from Tunisia. Passionate about data engineering, deep learning and solutions architecture.


Software engineering student from Tunisia. Passionate about data engineering, deep learning and solutions architecture.
About Author

Software engineering student from Tunisia. Passionate about data engineering, deep learning and solutions architecture.
Comments

















